
Artikel ini mengumpulkan beberapa pola umum untuk membantu insinyur bekerja dengan layanan skala besar yang diminta oleh jutaan pengguna.
Menurut pengalaman penulis, ini bukanlah daftar yang lengkap, tetapitip yangsangat efektif . Jadi, mari kita mulai.
Diterjemahkan dengan dukungan dari Mail.ru Cloud Solutions .
Tingkat pertama
Langkah-langkah yang tercantum di bawah ini relatif mudah untuk diterapkan, tetapi menghasilkan keuntungan yang tinggi. Jika Anda belum pernah mencobanya sebelumnya, Anda akan terkejut dengan peningkatan yang signifikan.
Infrastruktur sebagai kode
Saran pertama adalah menerapkan infrastruktur sebagai kode. Ini berarti Anda harus memiliki cara terprogram untuk menerapkan seluruh infrastruktur Anda. Kedengarannya rumit, tetapi sebenarnya kita berbicara tentang kode berikut:
Terapkan 100 mesin virtual
- dengan Ubuntu
- RAM masing-masing 2 GB
- mereka akan memiliki kode berikut
- dengan parameter seperti itu
Anda dapat melacak dan kembali ke perubahan infrastruktur dengan cepat menggunakan kontrol sumber.
Modernis dalam diri saya mengatakan bahwa Anda dapat menggunakan Kubernetes / Docker untuk melakukan semua hal di atas, dan dia benar.
Alternatifnya, Anda dapat memberikan otomatisasi dengan Chef, Puppet, atau Terraform.
Integrasi dan pengiriman berkelanjutan
Untuk membuat layanan yang skalabel, penting untuk memiliki pipeline build dan pengujian untuk setiap permintaan pull. Sekalipun pengujiannya paling sederhana, setidaknya itu akan memastikan bahwa kode yang Anda terapkan dikompilasi.
Setiap kali pada tahap ini, Anda menjawab pertanyaan: apakah perakitan saya akan mengumpulkan dan lulus tes, apakah valid? Ini mungkin terdengar seperti bar rendah, tetapi ini menyelesaikan banyak masalah.
Tidak ada yang lebih indah dari melihat kotak centang ini.
Untuk teknologi ini, Anda dapat memeriksa Github, CircleCI atau Jenkins.
Load balancer
Jadi, kami ingin memulai penyeimbang beban untuk mengalihkan lalu lintas dan memastikan bahwa semua node dimuat secara sama atau layanan akan berfungsi jika terjadi kegagalan:
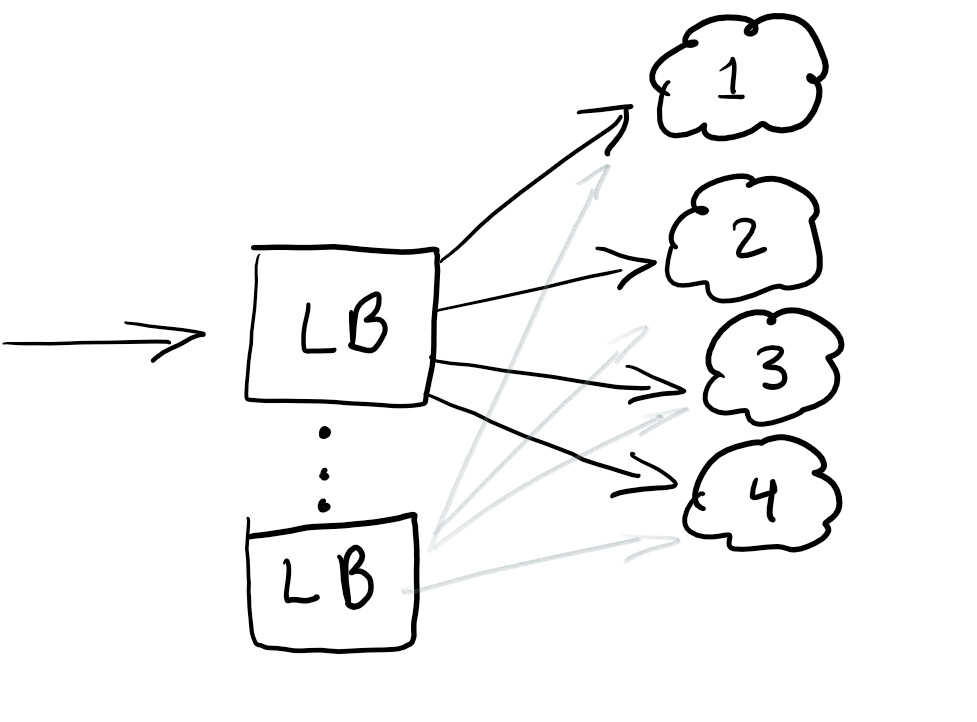
Penyeimbang beban umumnya bagus dalam membantu mendistribusikan lalu lintas. Praktik terbaiknya adalah menyeimbangkan sehingga Anda tidak memiliki satu titik pun kegagalan.
Biasanya, penyeimbang beban dikonfigurasi di awan yang Anda gunakan.
RayID, Correlation ID atau UUID untuk permintaan
Pernahkah Anda menjumpai kesalahan dalam aplikasi dengan pesan seperti ini: “Ada yang tidak beres. Simpan id ini dan kirimkan ke tim dukungan kami ” ?
Pengenal unik, ID korelasi, RayID, atau variasinya, adalah pengenal unik yang memungkinkan Anda melacak permintaan sepanjang siklus hidupnya. Ini memungkinkan Anda melacak seluruh jalur permintaan di log.
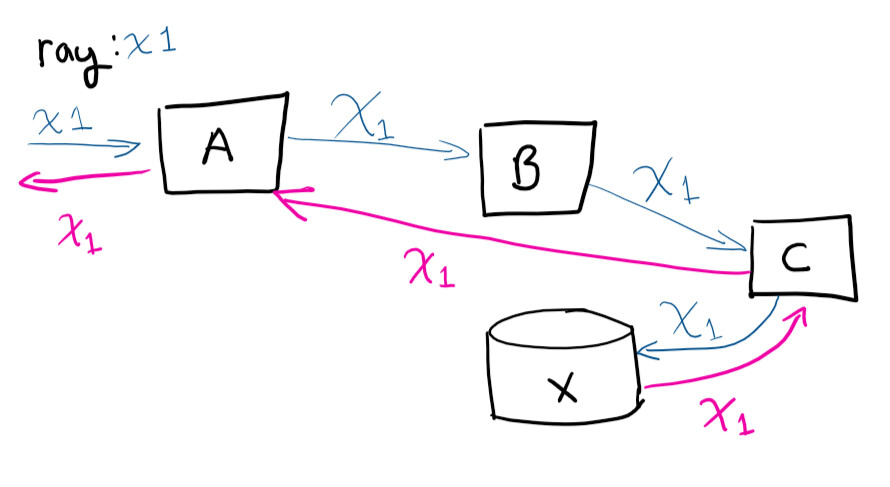
Pengguna membuat permintaan ke sistem A, lalu A menghubungi B, yang menghubungi C, menyimpan ke X, dan kemudian permintaan kembali ke A
Jika Anda terhubung dari jarak jauh ke mesin virtual dan mencoba melacak jalur permintaan (dan secara manual menghubungkan panggilan mana yang terjadi), kamu akan menjadi gila. Memiliki pengenal unik membuat hidup lebih mudah. Ini adalah salah satu hal termudah untuk dilakukan untuk menghemat waktu seiring dengan berkembangnya layanan Anda.
Tingkat menengah
Nasihat di sini lebih kompleks daripada yang sebelumnya, tetapi alat yang tepat membuat tugas lebih mudah, memberikan laba atas investasi bahkan untuk perusahaan kecil dan menengah.
Logging terpusat
Selamat! Anda telah menerapkan 100 mesin virtual. Keesokan harinya, CEO datang dan mengeluh tentang kesalahan yang dia terima saat menguji layanan. Ini melaporkan ID terkait yang kita bicarakan di atas, tetapi Anda harus memeriksa log dari 100 mesin untuk menemukan salah satu yang menyebabkan kerusakan. Dan dia harus ditemukan sebelum presentasi besok.
Meskipun ini terdengar seperti petualangan yang menyenangkan, yang terbaik adalah memastikan Anda memiliki kemampuan untuk mencari semua majalah dari satu tempat. Saya memecahkan masalah sentralisasi log dengan fungsionalitas built-in dari ELK stack: mendukung pengumpulan log yang dapat dicari. Ini akan sangat membantu menyelesaikan masalah dengan menemukan log tertentu. Sebagai bonus, Anda dapat membuat diagram dan hal menyenangkan lainnya seperti itu.
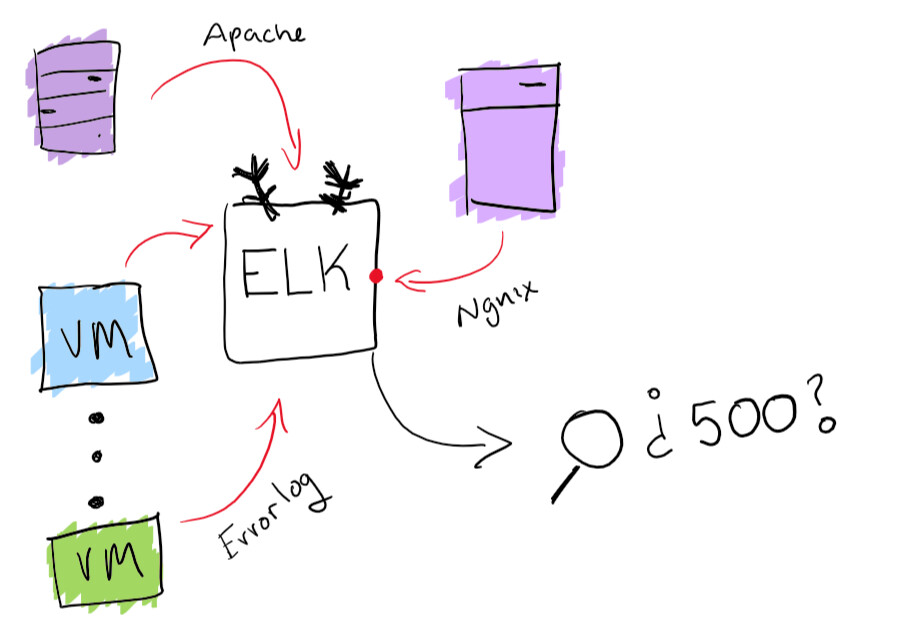
Fungsionalitas tumpukan ELK
Agen pemantau
Sekarang setelah layanan Anda aktif dan berjalan, Anda perlu memastikannya berjalan dengan lancar. Cara terbaik untuk melakukannya adalah dengan menjalankan beberapa agen yang berjalan secara paralel dan memverifikasi bahwa itu berjalan dan operasi dasar dilakukan.
Pada titik ini, Anda memverifikasi bahwa perakitan yang berjalan baik-baik saja dan berfungsi dengan baik .
Untuk proyek kecil hingga menengah, saya merekomendasikan Postman untuk memantau dan mendokumentasikan API. Namun secara umum, Anda hanya perlu memastikan bahwa Anda memiliki cara untuk mengetahui kapan kegagalan telah terjadi dan menerima peringatan tepat waktu.
Penskalaan otomatis berdasarkan beban
Sangat sederhana. Jika Anda memiliki mesin virtual yang melayani permintaan dan penggunaan memorinya mendekati 80%, Anda dapat meningkatkan sumber dayanya atau menambahkan lebih banyak mesin virtual ke kluster. Pelaksanaan otomatis dari operasi ini sangat baik untuk perubahan daya elastis di bawah beban. Tetapi Anda harus selalu berhati-hati tentang berapa banyak uang yang Anda belanjakan dan menetapkan batasan yang masuk akal.
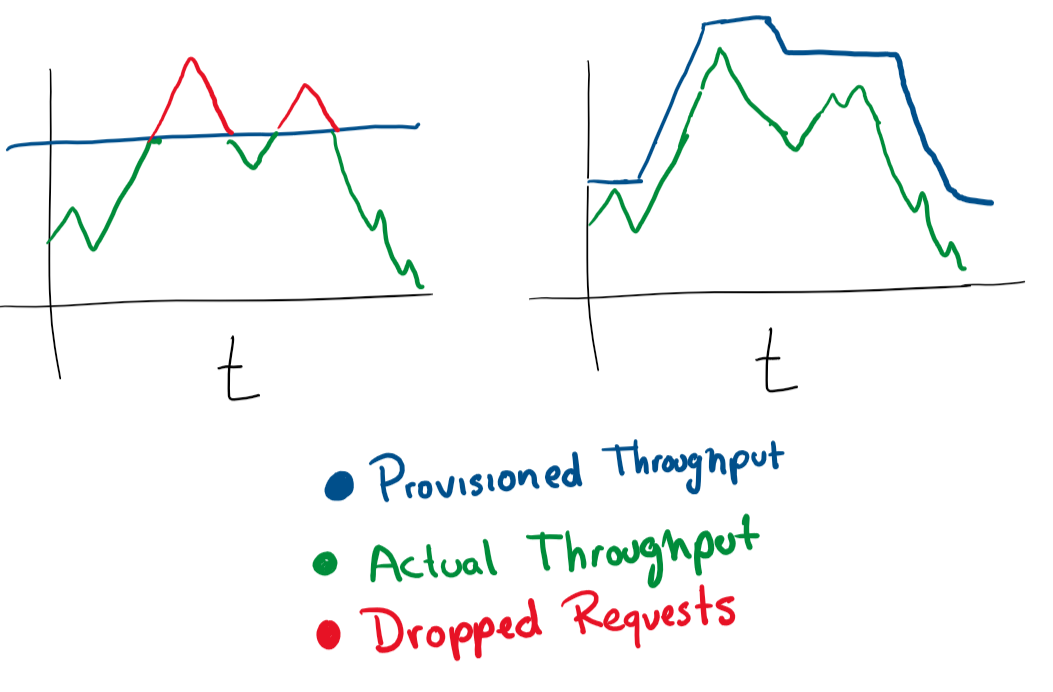
Di sebagian besar layanan cloud, Anda dapat mengonfigurasi penskalaan otomatis dengan lebih banyak server atau server yang lebih kuat.
Sistem percobaan
Cara yang baik untuk menerapkan pembaruan dengan aman adalah dengan menguji sesuatu untuk 1% pengguna dalam satu jam. Anda pasti telah melihat mekanisme seperti itu beraksi. Misalnya, Facebook menunjukkan warna yang berbeda pada bagian audiens atau mengubah ukuran font untuk melihat bagaimana pengguna melihat perubahan tersebut. Ini disebut pengujian A / B.
Bahkan merilis fitur baru dapat dijalankan sebagai eksperimen dan kemudian menemukan cara untuk merilisnya. Anda juga mendapatkan kemampuan untuk "mengingat" atau mengubah konfigurasi dengan cepat, dengan mempertimbangkan fungsi yang menyebabkan penurunan layanan Anda.
Tingkat Lanjut
Berikut beberapa tips yang cukup sulit untuk diterapkan. Anda mungkin membutuhkan lebih banyak sumber daya, sehingga akan sulit bagi perusahaan kecil atau menengah untuk menangani ini.
Penerapan biru-hijau
Inilah yang saya sebut metode penyebaran "Erlang". Erlang banyak digunakan ketika perusahaan telepon datang. Sakelar lunak telah digunakan untuk merutekan panggilan telepon. Fokus utama perangkat lunak pada sakelar ini bukanlah untuk memutuskan panggilan selama peningkatan sistem. Erlang memiliki cara yang bagus untuk memuat modul baru tanpa merusak modul sebelumnya.
Langkah ini bergantung pada keberadaan penyeimbang beban. Katakanlah Anda memiliki perangkat lunak versi N dan kemudian Anda ingin menerapkan versi N + 1.
Anda dapat menghentikan layanan dan menerapkan versi berikutnya pada waktu yang sesuai bagi pengguna Anda dan mendapatkan waktu henti. Tapi misalkan Anda punyapersyaratan SLA yang sangat ketat. Jadi, SLA 99,99% berarti Anda bisa offline hanya 52 menit per tahun.
Jika Anda benar-benar ingin mencapai ini, Anda memerlukan dua penerapan pada saat yang sama:
- yang sekarang (N);
- versi berikutnya (N + 1).
Anda memberi tahu penyeimbang beban untuk mengalihkan persentase lalu lintas Anda ke versi baru (N + 1) saat Anda sendiri secara aktif melacak regresi.
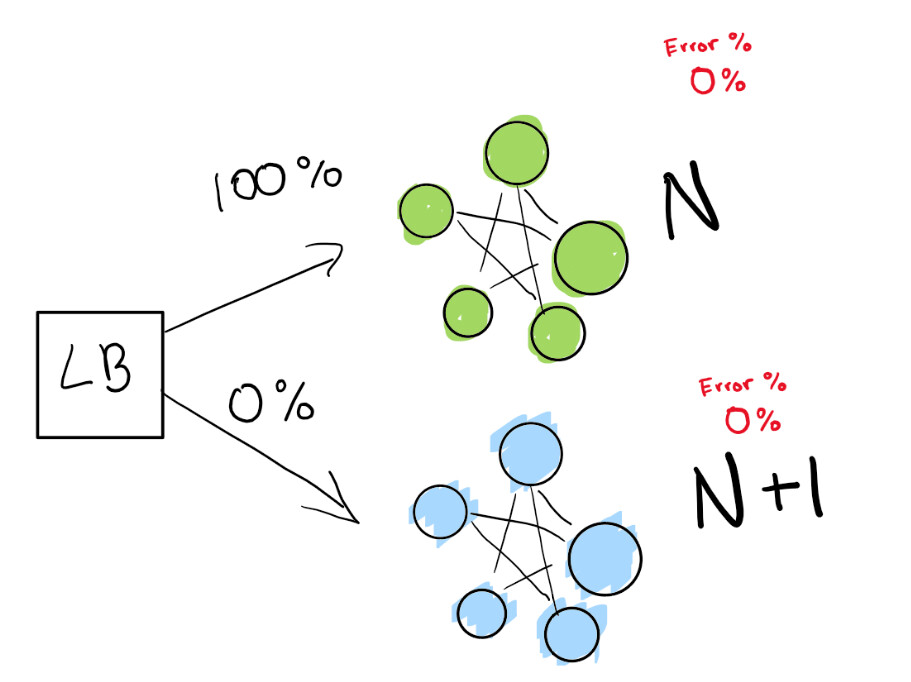
Di sini kami memiliki penerapan hijau N yang berfungsi dengan baik. Kami mencoba untuk melanjutkan ke versi berikutnya dari penerapan ini.
Pertama, kami mengirimkan pengujian yang sangat kecil untuk melihat apakah penerapan N + 1 kami berfungsi dengan sedikit lalu lintas:
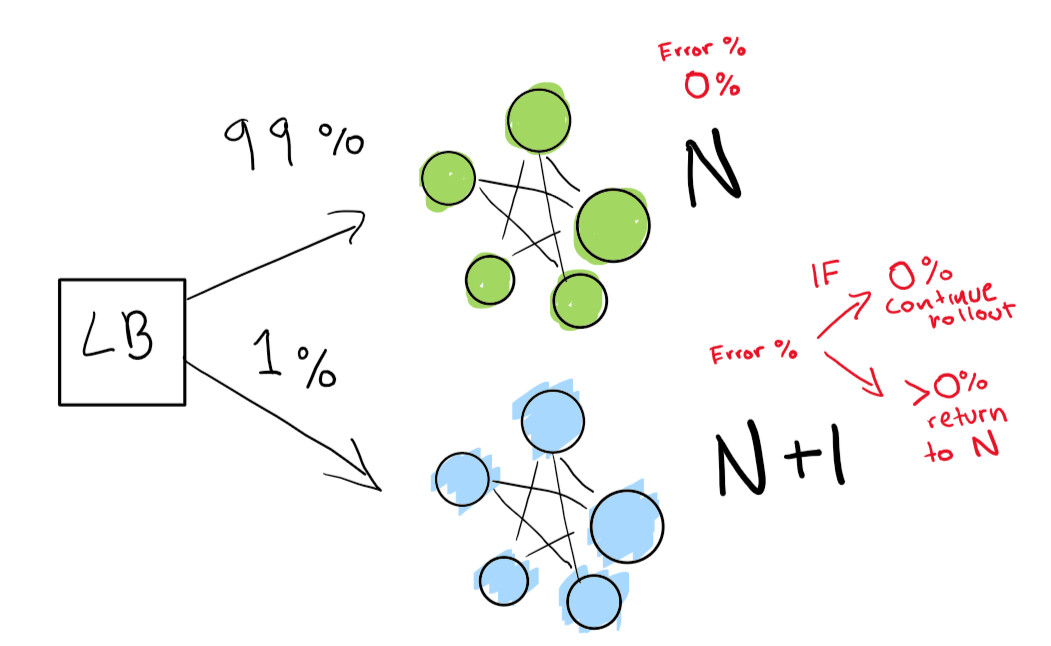
Terakhir, kami memiliki serangkaian pemeriksaan otomatis yang akhirnya kami jalankan hingga penerapan kami selesai. Jika Anda sangat, sangat berhati-hati, Anda juga dapat menyimpan penerapan N selamanya untuk rollback cepat jika terjadi regresi yang buruk:
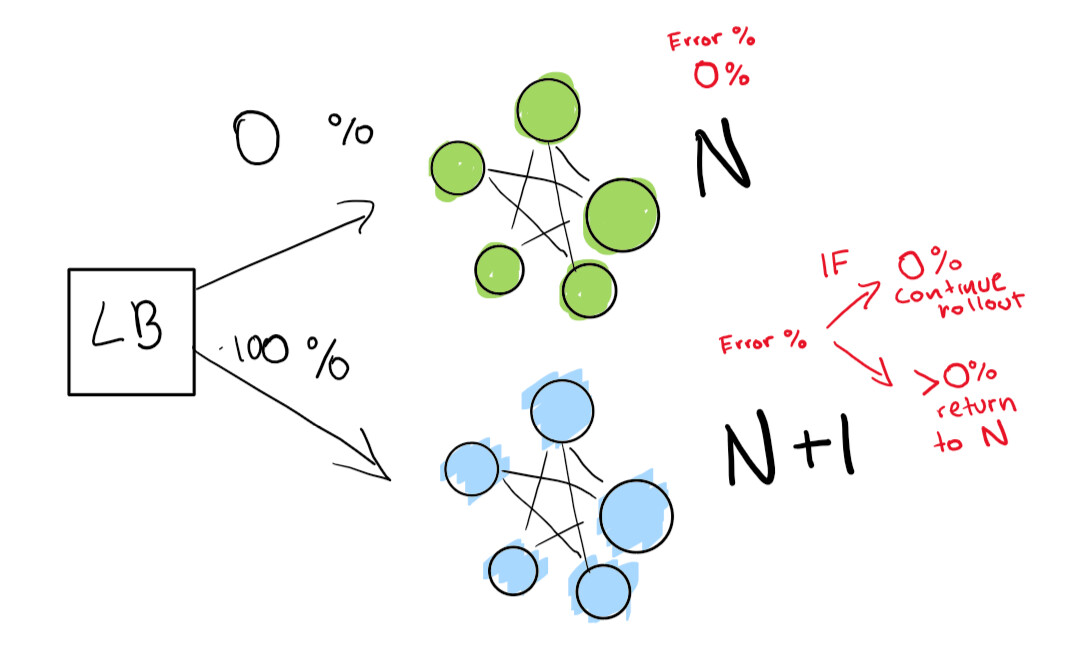
Jika Anda ingin naik ke tingkat yang lebih tinggi, biarkan semua yang ada di penerapan biru-hijau dilakukan secara otomatis.
Deteksi anomali dan mitigasi otomatis
Mengingat Anda memiliki logging terpusat dan pengumpulan log yang baik, Anda sudah dapat menetapkan tujuan yang lebih tinggi. Misalnya, secara proaktif memprediksi kegagalan. Pada monitor dan log, fungsi dilacak dan berbagai diagram dibuat - dan Anda dapat memprediksi sebelumnya apa yang salah:
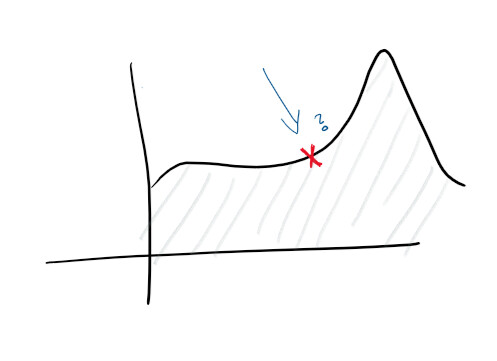
Dengan penemuan anomali, Anda mulai mempelajari beberapa petunjuk bahwa masalah layanan. Misalnya, lonjakan penggunaan CPU mungkin menunjukkan bahwa hard drive gagal, sementara lonjakan permintaan berarti Anda perlu menskalakan. Statistik semacam ini memungkinkan kami membuat layanan menjadi proaktif.
Dengan wawasan ini, Anda dapat menskalakan dalam dimensi apa pun, secara proaktif dan reaktif mengubah karakteristik mesin, database, koneksi, dan sumber daya lainnya.
Itu saja!
Daftar prioritas ini akan menghemat banyak masalah jika Anda menggunakan layanan cloud.
Penulis artikel asli mengundang pembaca untuk meninggalkan komentarnya dan membuat perubahan. Artikel ini didistribusikan sebagai open source, penulis menerima pull request di Github .
Apa lagi yang harus dibaca tentang topik ini: