Jika Anda telah mendesain aplikasi atau database backend untuk sementara waktu, Anda mungkin telah menulis kode untuk mengeksekusi kueri paginasi. Misalnya - seperti ini:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Apa adanya?
Tetapi jika ini adalah cara Anda melakukan penomoran halaman, dengan menyesal saya katakan bahwa Anda tidak melakukannya dengan cara yang paling efisien.
Apakah Anda ingin berdebat dengan saya? Anda tidak perlu membuang waktu . Slack , Shopify, dan Mixmax sudah menggunakan trik yang ingin saya bicarakan hari ini.
Beri nama setidaknya satu backend developer, yang tidak pernah digunakan
OFFSETdan LIMITuntuk menjalankan kueri dengan penomoran halaman. Dalam MVP (Minimum Viable Product, minimum viable product) dan dalam proyek yang menggunakan data dalam jumlah kecil, pendekatan ini cukup dapat diterapkan. Bisa dibilang begitu saja.
Tetapi jika Anda perlu membuat sistem yang andal dan efisien dari awal, Anda harus menjaga efisiensi kueri ke database yang digunakan dalam sistem tersebut sebelumnya.
Hari ini kita akan berbicara tentang masalah yang terkait dengan implementasi yang banyak digunakan (maaf) dari mesin eksekusi kueri paginasi, dan cara mencapai kinerja tinggi saat menjalankan kueri semacam itu.
Apa yang salah dengan OFFSET dan LIMIT?
Seperti yang telah dikatakan,
OFFSETdan dengan LIMITsempurna menunjukkan dirinya dalam proyek yang tidak perlu bekerja dengan data dalam jumlah besar.
Masalah muncul ketika database tumbuh sedemikian besar sehingga tidak lagi sesuai dengan memori server. Namun, saat bekerja dengan database ini, Anda harus menggunakan kueri yang diberi nomor halaman.
Agar masalah ini terwujud, situasi perlu muncul di mana DBMS menggunakan operasi Pemindaian Tabel Penuh yang tidak efisien saat menjalankan setiap kueri dengan pagination (pada saat yang sama, operasi penyisipan dan penghapusan data dapat terjadi , dan kami tidak membutuhkan data lama!).
Apa itu "scan tabel lengkap" (atau "scan tabel berurutan", Sequential Scan)? Ini adalah operasi di mana DBMS secara berurutan membaca setiap baris tabel, yaitu, data yang terkandung di dalamnya, dan memeriksanya dengan kondisi tertentu. Jenis pemindaian tabel ini dikenal sebagai yang paling lambat. Faktanya adalah bahwa ketika dijalankan, banyak operasi I / O dilakukan yang menggunakan subsistem disk server. Situasi ini diperparah oleh penundaan yang terkait dengan pekerjaan dengan data yang disimpan di disk, dan fakta bahwa mentransfer data dari disk ke memori adalah operasi yang membutuhkan banyak sumber daya.
Misalnya, Anda memiliki catatan 100.000.000 pengguna dan Anda menjalankan kueri dengan konstruksi
OFFSET 50000000... Ini berarti bahwa DBMS harus memuat semua catatan ini (dan kita bahkan tidak membutuhkannya!), Tempatkan mereka dalam memori, dan setelah itu ambil, katakanlah, 20 hasil yang dilaporkan LIMIT.
Katakanlah itu mungkin terlihat seperti "pilih baris 50.000 sampai 50020 dari 100.000". Artinya, sistem harus memuat 50.000 baris terlebih dahulu untuk menjalankan kueri. Lihat berapa banyak pekerjaan tidak perlu yang harus dia lakukan?
Jika Anda tidak percaya, lihat contoh yang saya buat menggunakan db-fiddle.com .

Contoh di db-fiddle.com
Di sana, di sebelah kiri, di dalam kotak
Schema SQL, ada kode untuk memasukkan 100.000 baris ke dalam database, dan di sebelah kanan, di dalam kotakQuery SQL, dua kueri ditampilkan. Yang pertama, lambat, terlihat seperti ini:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Dan yang kedua, yang merupakan solusi efektif untuk masalah yang sama, seperti ini:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Untuk memenuhi permintaan ini, cukup klik tombol
Rundi bagian atas halaman. Setelah melakukan ini, mari bandingkan informasi tentang waktu eksekusi kueri. Ternyata eksekusi kueri yang tidak efisien membutuhkan waktu setidaknya 30 kali lebih lama daripada eksekusi kueri kedua (kali ini berbeda dari peluncuran ke peluncuran, misalnya, sistem mungkin melaporkan bahwa permintaan pertama membutuhkan waktu 37 md untuk diselesaikan, dan eksekusi kedua - 1 ms).
Dan jika ada lebih banyak data, maka semuanya akan terlihat lebih buruk (untuk memverifikasi ini, lihat contoh saya dengan 10 juta baris).
Apa yang baru saja kita diskusikan akan memberi Anda beberapa wawasan tentang bagaimana kueri database sebenarnya ditangani.
Perlu diingat bahwa semakin besar nilainya
OFFSET - permintaan akan semakin lama.
Apa yang harus digunakan sebagai pengganti kombinasi OFFSET dan LIMIT?
Alih-alih kombinasi
OFFSET, LIMITada baiknya menggunakan struktur yang dibangun sesuai dengan skema berikut:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Ini adalah eksekusi kueri penomoran halaman berbasis kursor.
Alih-alih disimpan secara lokal saat ini
OFFSETdan LIMITdan mengirimkannya ke setiap permintaan, perlu untuk menyimpan menerima kunci utama terakhir (biasanya - a ID) dan LIMIT, sebagai hasilnya dan akan diminta menyerupai disebutkan di atas.
Mengapa? Faktanya adalah bahwa dengan secara eksplisit menentukan pengenal baris baca terakhir, Anda memberi tahu DBMS Anda di mana ia perlu mulai mencari data yang dibutuhkannya. Selain itu, pencarian, berkat penggunaan kunci, akan dilakukan secara efisien, sistem tidak akan terganggu oleh garis yang berada di luar rentang yang ditentukan.
Mari kita lihat perbandingan kinerja dari berbagai kueri berikut. Berikut pertanyaan yang tidak efektif.
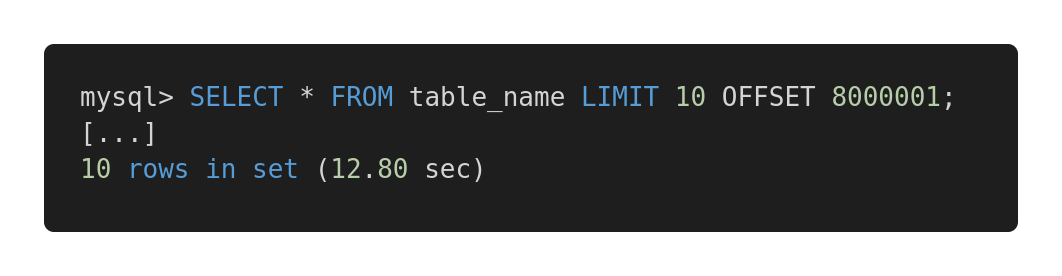
Slow Query
Dan inilah versi optimal dari query ini.

Kueri Cepat
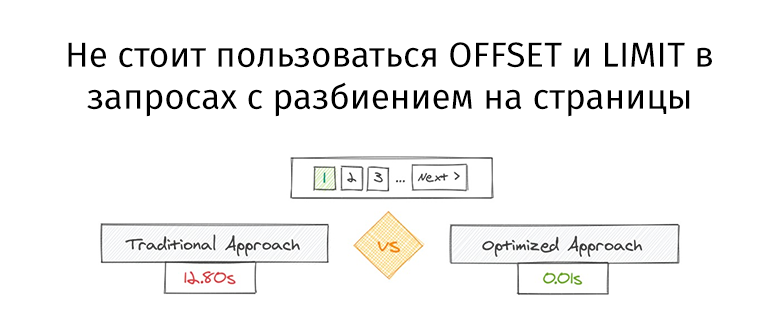
Kedua kueri mengembalikan jumlah data yang persis sama. Tapi yang pertama membutuhkan 12,80 detik, dan yang kedua membutuhkan 0,01 detik. Apakah Anda merasakan perbedaannya?
Kemungkinan masalah
Agar metode eksekusi kueri yang diusulkan berfungsi secara efisien, tabel harus memiliki kolom (atau kolom) yang berisi indeks berurutan unik, seperti pengenal integer. Dalam beberapa kasus tertentu, ini dapat menentukan keberhasilan penggunaan kueri tersebut untuk meningkatkan kecepatan bekerja dengan database.
Biasanya, saat mendesain kueri, Anda perlu mempertimbangkan kekhasan arsitektur tabel, dan memilih mekanisme yang paling baik ditampilkan pada tabel yang ada. Misalnya, jika Anda perlu bekerja dalam kueri dengan data terkait dalam jumlah besar, Anda mungkin menganggap artikel ini menarik .
Jika kita dihadapkan pada masalah tidak adanya kunci primer, misalnya, jika kita memiliki tabel dengan hubungan banyak-ke-banyak, maka pendekatan tradisional menggunakan
OFFSETdan LIMITdijamin akan berhasil untuk kita. Namun penerapannya dapat mengarah pada eksekusi kueri yang berpotensi lambat. Dalam kasus seperti itu, saya akan merekomendasikan menggunakan kunci utama autoincrementing, bahkan jika Anda hanya membutuhkannya untuk mengatur kueri paginasi.
Jika Anda tertarik dengan topik ini - di sini , di sini , dan di sini - beberapa materi bermanfaat.
Hasil
Kesimpulan utama yang dapat kita tarik adalah bahwa selalu, berapa pun ukuran database yang kita bicarakan, kita perlu menganalisis kecepatan eksekusi kueri. Saat ini, skalabilitas solusi sangat penting, dan jika Anda mendesain semuanya dengan benar sejak awal pekerjaan pada sistem tertentu, ini, di masa mendatang, dapat menyelamatkan pengembang dari banyak masalah.
Bagaimana Anda menganalisis dan mengoptimalkan kueri database?
