
Nama saya Alexander Deulin, saya bekerja di departemen pengembangan "Factory of Microservices" saya sendiri di MegaFon. Dan saya ingin memberi tahu Anda tentang jalur sulit munculnya cache Tarantool di lanskap perusahaan kami, serta cara kami menerapkan replikasi dari Oracle. Dan saya akan langsung menjelaskan bahwa dalam hal ini cache berarti aplikasi dengan database.
Cache Tarantool
Kami telah berbicara banyak tentang bagaimana kami mengimplementasikan Unified Billing di MegaFon , kami tidak akan membahasnya secara mendetail, tetapi sekarang proyek tersebut dalam tahap penyelesaian. Oleh karena itu, hanya sedikit statistik:
Dengan apa yang kami lakukan pada tugas kami:
- 80 juta pelanggan;
- 300 juta profil pelanggan;
- 2 miliar peristiwa transaksional untuk mengubah saldo per hari;
- 250 TB data aktif;
- > 8 PB arsip;
- dan semua ini terletak di 5000 server di berbagai pusat data.
Artinya, kita berbicara tentang sistem yang sangat padat, di mana setiap subsistem mulai melayani 80 juta pelanggan. Jika sebelumnya kita memiliki 7 instance dan conditional horizontal scaling, sekarang kita telah beralih ke domain. Dulu ada monolit, tapi sekarang kami punya DDD. Sistem ini tercakup dengan baik oleh API, dibagi menjadi beberapa subsistem, tetapi tidak ada cache di semua tempat. Sekarang kita dihadapkan pada fakta bahwa subsistem membuat beban yang terus meningkat. Selain itu, saluran baru muncul, yang mengharuskan untuk menyediakan 5.000 permintaan per detik per operasi dengan latensi 50 md dalam 95% kasus, dan untuk memastikan ketersediaan pada tingkat 99,99%.
Secara paralel, kami mulai membuat arsitektur layanan mikro.

Kami memiliki lapisan cache terpisah tempat data dari setiap subsistem dimunculkan. Ini membuatnya mudah untuk merakit komposit dan mengisolasi sistem master dari beban kerja pembacaan yang berat.
Bagaimana cara membangun cache untuk subsistem tertutup?
Kami memutuskan bahwa kami perlu membuat cache sendiri, tidak bergantung pada vendor. Penagihan Terpadu adalah ekosistem tertutup. Ini berisi banyak pola layanan mikro, yang memiliki banyak API dan basis datanya sendiri. Namun karena sifatnya yang tertutup, tidak mungkin untuk memodifikasi apapun.
Kami mulai berpikir tentang bagaimana kami harus mendekati sistem master kami. Pendekatan yang sangat populer adalah desain yang digerakkan oleh peristiwa, ketika kami menerima data dari beberapa jenis bus: apakah ini adalah topik Kafka, atau bertukar RabbitMQ. Anda juga bisa mendapatkan data dari Oracle: dengan pemicu, menggunakan CQN (alat gratis dari Oracle) atau Golden Gate. Karena kami tidak dapat mengintegrasikan ke dalam aplikasi, opsi tulis-tayang dan tulis-balik tidak tersedia bagi kami.
Menerima data dari bus dispatcher pesan
Kami sangat menyukai opsi dengan antrian dan pengelola pesan. RabbitMQ dan Kafka sudah digunakan dalam "Penagihan terpadu". Kami mengujicobakan salah satu sistem dan mendapatkan hasil yang luar biasa. Kami menerima semua event dari RabbitMQ dan melakukan cold loading, jumlah datanya tidak terlalu besar.
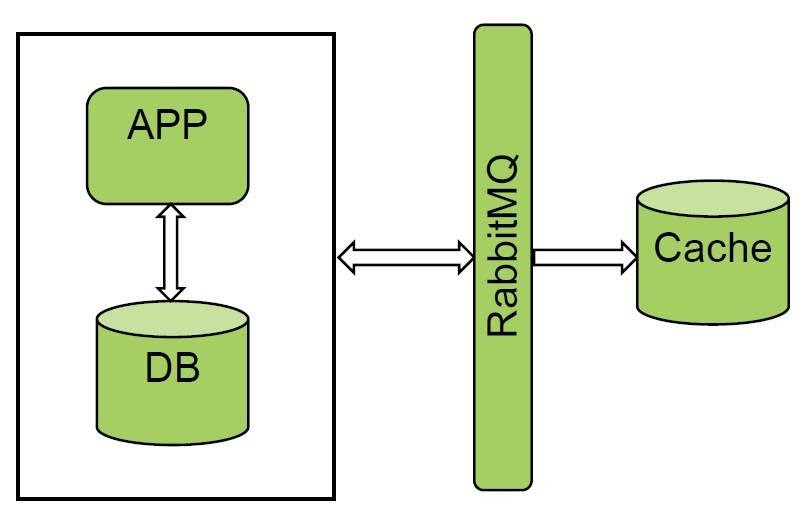
Solusinya berfungsi dengan baik, tetapi tidak semua sistem dapat memberi tahu bus, jadi opsi ini tidak berfungsi untuk kami.
Mengambil data dari database: pemicu
Masih ada cara untuk mendapatkan data dengan mengisi cache dari database.
Opsi paling sederhana adalah pemicu. Tetapi mereka tidak cocok untuk aplikasi beban tinggi, karena, pertama, kami memodifikasi sistem master itu sendiri, dan kedua, ini adalah titik kegagalan tambahan. Jika pemicu tiba-tiba tidak dapat menulis ke beberapa jenis pelat sementara, kami mendapatkan degradasi total, termasuk sistem master.

Mengambil data dari database: CQN
Pilihan kedua untuk mendapatkan data dari database. Kami menggunakan Oracle, dan vendor saat ini hanya mendukung satu alat gratis untuk mengambil data dari database - CQN.
Mekanisme ini memungkinkan Anda untuk berlangganan pemberitahuan perubahan operasi DDL atau DML. Semuanya cukup sederhana di sana. Ada pemberitahuan gaya JDBC dan PL / SQL.
JDBC berarti kami memberi tahu antrian lanjutan dan acara ini dikirim ke sistem eksternal. Bahkan, dibutuhkan konektor OSI eksternal. Kami tidak menyukai opsi ini, karena jika kami kehilangan koneksi dengan Oracle, kami tidak dapat membaca pesan kami.
Kami memilih PL / SQL karena memungkinkan kami untuk mencegat notifikasi dan menyimpannya dalam tabel sementara di database Oracle yang sama. Artinya, dengan cara ini Anda dapat memberikan integritas transaksional.
Semuanya bekerja dengan baik pada awalnya sampai kami mengemudikan pangkalan yang cukup terisi. Kekurangan berikut muncul:
- Beban transaksional di pangkalan. Saat kami mencegat pesan dari antrean notifikasi, kami harus meletakkannya di basis. Artinya, beban tulis berlipat ganda.
- Ini juga menggunakan antrian lanjutan internal. Dan jika sistem master Anda juga menggunakannya, maka persaingan untuk antrian bisa muncul.
- Kami mendapat kesalahan menarik pada tabel yang dipartisi. Jika satu komit menutup lebih dari 100 perubahan, maka CQN tidak menangkap perubahan tersebut. Kami membuka tiket di Oracle, mengubah parameter sistem - itu tidak membantu.
Untuk aplikasi berat, CQN sudah pasti tidak cocok. Ini bagus untuk instalasi kecil, untuk bekerja dengan beberapa jenis kamus, data referensi.
Mengambil data dari database: Golden Gate
Gerbang Emas tua yang bagus tetap ada. Awalnya, kami tidak ingin menggunakannya, karena ini adalah solusi kuno, kami diintimidasi oleh kompleksitas sistem itu sendiri.

Di GG sendiri, ada dua contoh tambahan yang perlu dipertahankan, dan kami tidak memiliki banyak pengetahuan Oracle. Awalnya, ini cukup sulit, meskipun kami sangat menyukai kemungkinan solusinya.
Kombinasi SCN + XID memungkinkan kami untuk mengontrol integritas transaksional. Solusinya ternyata universal, berdampak rendah pada sistem master tempat kami dapat menerima semua peristiwa. Meskipun solusinya memerlukan pembelian lisensi, ini tidak menjadi masalah bagi kami karena lisensi sudah tersedia. Juga, kelemahan dari solusi tersebut termasuk implementasi yang kompleks dan fakta bahwa GG adalah subsistem tambahan.
kesimpulan
Kesimpulan apa yang bisa ditarik dari atas?
Jika Anda memiliki sistem tertutup, maka Anda perlu meneliti sifat beban Anda dan cara penggunaan, dan memilih solusi yang sesuai. Optimalnya, menurut kami, adalah desain yang digerakkan oleh acara, ketika kami memberi tahu topik di Kafka dan broker pesan menjadi sistem master. Topik adalah rekor emas, data lainnya diambil oleh sistem. Untuk sistem tertutup di lanskap kami, GG ternyata menjadi solusi paling sukses.
PIM - etalase makanan
Dan sekarang, dengan menggunakan contoh salah satu produk, saya akan memberi tahu Anda bagaimana kami menerapkan solusi ini. PIM adalah showcase produk berbasis SID. Artinya, ini semua adalah produk pelanggan yang saat ini terhubung dengannya. Atas dasar mereka, biaya dihitung dan logika pekerjaan dibangun.
Arsitektur
Izinkan saya mengingatkan Anda bahwa dalam artikel ini, "cache" berarti kombinasi dari aplikasi dan database, ini adalah pola penggunaan utama untuk Tarantool.
Keunikan proyek PIM adalah bahwa sistem master Oracle asli "kecil", hanya 10 miliar catatan. Itu harus dibaca. Dan masalah terbesar yang kami selesaikan adalah pemanasan cache.
Darimana kita mulai?

10 tabel utama memberikan 10 miliar catatan. Kami ingin membacanya secara langsung. Karena kami hanya mengumpulkan data panas ke cache, dan Oracle menyimpan, antara lain, data historis, kami harus menetapkan klausa lokasi dan menarik 10 miliar ini. Tugas yang tidak sepele. Oracle memberi tahu kami bahwa ini tidak boleh dilakukan: menaikkan beban prosesor menjadi 100%. Kami memutuskan untuk pergi ke arah lain.
Tapi pertama-tama, beberapa kata tentang arsitektur cluster.
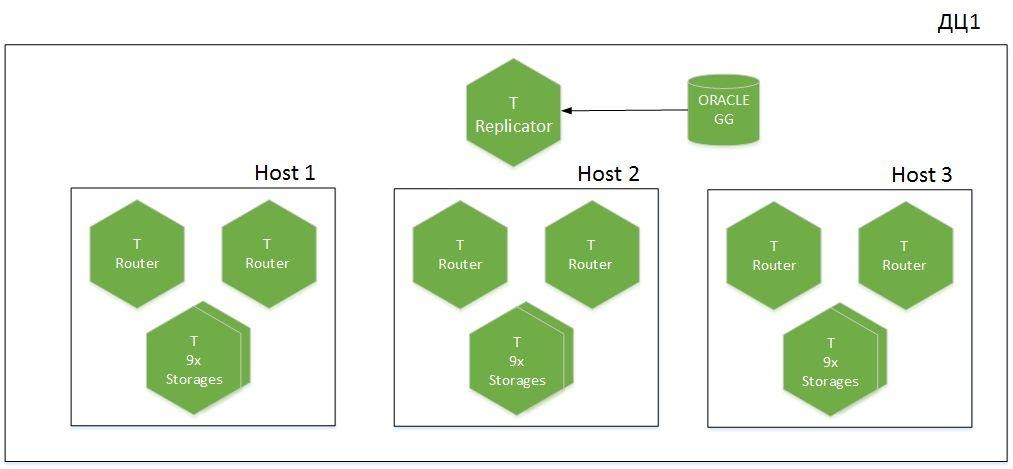
Ini adalah aplikasi dengan sharded, 9 shard dalam 6 host, didistribusikan melalui dua pusat data. Kami memiliki Tarantool dengan peran Replicator, yang menerima data dari Oracle, dan contoh lain yang disebut Importir digunakan untuk cold boot. Sebanyak 1,1 TB data panas dibesarkan di cache.
Boot dingin
Bagaimana kami mengatasi masalah boot dingin? Semuanya ternyata sangat sepele.

Bagaimana keseluruhan mekanisme bekerja? Kami menghapus klausa where dan membaca semuanya. Pertama, kami memulai aliran redo-log untuk benar-benar menerima perubahan online dari database. Dengan pemindaian penuh, kami melewati subbagian, mengambil data dalam batch dengan normalisasi dan filtrasi. Kami menyimpan perubahan, secara bersamaan memulai pemanasan dingin cache dan mengunggah semuanya ke file CSV. Ada 10 contoh importir yang berjalan di cache, yang setelah dibaca dari Oracle, mengirim data ke instance Tarantool. Untuk melakukan ini, setiap importir menghitung shard yang diperlukan dan meletakkan datanya di penyimpanan yang diperlukan itu sendiri, tanpa memuat router.
Setelah memuat semua data dari Oracle, kami memutar aliran jejak dari GG yang telah terakumulasi selama ini. Ketika SCN + XID mencapai nilai yang dapat diterima dengan sistem master, kami menganggap bahwa cache dihangatkan, dan menyertakan beban saat membaca dari sistem eksternal.
Beberapa statistik. Di Oracle, kami memiliki sekitar 2,5 TB data mentah. Kami membacanya selama 5 jam, mengimpornya ke CSV. Memuat ke Tarantool dengan penyaringan dan normalisasi membutuhkan waktu 8 jam. Dan selama enam jam kami memainkan tumpukan kayu yang datang kepada kami dari jalan setapak. Kecepatan puncak dari 600 ribu catatan / s. hingga 1 juta puncak. Tarantool menyisipkan 1,1 TB data pada 200K record / s.
Sekarang, pemanasan dingin cache pada volume besar telah menjadi hal biasa bagi kami, karena kami tidak memiliki banyak dampak pada Oracle.

Alih-alih basis, kami memuat I / O dan jaringan, jadi pertama-tama kami harus memastikan bahwa kami memiliki margin bandwidth jaringan yang cukup, di puncak kami mencapai 400 Mbps.
Cara kerja rantai replikasi dari Oracle ke Tarantool
Saat mendesain cache, kami memutuskan untuk menghemat memori. Kami menghapus semua redundansi, menggabungkan lima tabel menjadi satu, dan mendapatkan skema penyimpanan yang sangat ringkas, tetapi kehilangan kendali atas konsistensi. Kami sampai pada kesimpulan bahwa perlu mengulang DDL dari Oracle. Ini memungkinkan kami untuk mengontrol SCN + XID dengan menyimpannya di ruang teknologi terpisah untuk setiap pelat. Dengan memeriksanya secara berkala, kami dapat memahami di mana replikasi rusak, dan jika terjadi masalah, kami membaca ulang log pengarsipan.
Sharding
Sedikit tentang penyimpanan data logis. Untuk menghilangkan Map Reduce, kami harus memperkenalkan redundansi data tambahan dan menguraikan kamus ke dalam penyimpanan kami sendiri. Kami melakukan ini dengan sengaja, karena cache kami berfungsi terutama untuk membaca. Kami tidak dapat mengintegrasikannya ke dalam sistem master, karena aplikasi ini mengisolasi beban saluran eksternal dari sistem master. Kami membaca semua data tentang pelanggan dari satu penyimpanan. Dalam hal ini, kami kehilangan kinerja tulis, tetapi itu tidak terlalu penting bagi kami, kamus jarang diperbarui.
Apa yang terjadi pada akhirnya?
Kami telah membuat cache untuk sistem tertutup kami. Ada beberapa kesalahan pemfilteran, tetapi kami telah memperbaikinya. Kami telah mempersiapkan diri untuk munculnya konsumen baru dengan beban tinggi. Musim panas lalu, sistem baru muncul, yang menambahkan 5-10 ribu permintaan per detik, dan kami tidak mengizinkan pemuatan ini ke "Penagihan Terpadu". Kami juga belajar bagaimana mempersiapkan replikasi dari Oracle ke Tarantool, menyelesaikan transfer data dalam jumlah besar tanpa memuat sistem master.
Apa yang masih harus kita lakukan?
Ini sebagian besar adalah skenario operasional:
- Kontrol otomatis atas konsistensi data.
- Kerjakan skenario peralihan Active-Standby Oracle, baik peralihan maupun kegagalan.
- Memutar log arsip dari GG.
- — DDL- -. , DDL , .
- «»: ? https://habr.com/ru/article/470842/
- : Tarantool https://habr.com/ru/company/mailru/blog/455694/
- Telegram Tarantool https://t.me/tarantool_news
- Tarantool - https://t.me/tarantoolru