Dari kemampuan untuk memproses informasi dalam jumlah besar dan menggunakan algoritma pembelajaran mesin dengan jauh lebih efisien, hingga algoritma pemodelan kuantum yang dapat meningkatkan komputasi (baik secara kualitatif maupun kuantitatif) untuk desain obat baru, prediksi struktur protein, analisis berbagai proses dalam organisme biologis, dan dll. Perspektif yang mencengangkan ini tunduk pada info hype yang luar biasa hari ini, yang berarti penting untuk menyoroti peringatan dan tantangan dalam teknologi baru ini.
Peringatan: Tinjauan ini didasarkan pada artikel oleh sekelompok peneliti Eropa dari Inggris dan Swiss (Carlos Outeiral, Martin Strahm, Jiye Shi, Garrett M. Morris, Simon C. Benjamin, Charlotte M. Deane. "Prospek komputasi kuantum dalam biologi molekuler komputasi", WIREs Computational Molecular Science diterbitkan oleh Wiley Periodicals LLC, 2020). Bagian tersulit dari artikel yang terkait dengan model matematika canggih tidak akan disertakan dalam ulasan. Tapi materinya awalnya rumit, dan pembaca dituntut memiliki pengetahuan matematika dan fisika kuantum.
Tetapi jika Anda berniat untuk mulai mempelajari penerapan teknologi kuantum dalam bioinformatika, maka untuk terlebih dahulu masuk ke topik tersebut, disarankan untuk mendengarkan ceramah singkat oleh Viktor Sokolov, Peneliti Senior di Keputusan M&S, yang menguraikan beberapa masalah modern dalam pemodelan obat:
pengantar
Sejak munculnya komputasi berkinerja tinggi, algoritme dan model matematika telah digunakan untuk memecahkan masalah dalam ilmu biologi - mulai dari mempelajari kompleksitas genom manusia hingga pemodelan perilaku biomolekul. Metode komputasi secara teratur digunakan saat ini untuk menganalisis dan mengekstrak informasi penting dari eksperimen biologis, serta untuk memprediksi perilaku objek dan sistem biologis. Faktanya, 10 dari 25 makalah ilmiah yang paling banyak dikutip berhubungan dengan algoritma komputasi yang digunakan dalam biologi [lihat hal. di sini ], termasuk pemodelan kuantum [di sini , di sini , di sini dan di sini ], penyelarasan urutan [di sini , di sini dandi sini ], genetika komputasi [lihat. di sini ] dan difraksi sinar-X dalam pemrosesan data [lih. di sini dan di sini ].
Terlepas dari kemajuan ini, banyak masalah dalam biologi tetap tidak terpecahkan dari sudut pandang solusi mereka menggunakan teknologi komputasi yang ada. Algoritme terbaik untuk tugas-tugas seperti memprediksi pelipatan protein, menghitung afinitas pengikatan ligan ke makromolekul, atau menemukan penyelarasan genomik skala besar yang optimal memerlukan sumber daya komputasi yang melampaui superkomputer terkuat yang tersedia saat ini.
Solusi untuk masalah ini mungkin terletak pada perubahan paradigma dalam teknologi komputasi. Pada 1980-an secara independen, Richard Feynman [lihat. di sini ] dan Yuri Manin [lihat. di sini ] mengusulkan untuk menggunakan efek mekanis kuantum untuk membuat komputer generasi baru yang lebih bertenaga.
Teori kuantum telah terbukti menjadi deskripsi realitas fisik yang sangat sukses dan telah membawa, sejak dimulainya di awal abad ke-20, ke kemajuan seperti laser, transistor, dan mikroprosesor semikonduktor. Komputer kuantum menggunakan algoritme paling efisien, menggunakan operasi yang tidak mungkin dilakukan di mesin klasik. Prosesor kuantum tidak lebih cepat dari komputer klasik, tetapi mereka bekerja dengan cara yang sama sekali berbeda, mencapai percepatan yang belum pernah terjadi sebelumnya, menghindari komputasi yang tidak perlu. Sebagai contoh, menghitung fungsi gelombang elektron total dari molekul obat rata-rata pada setiap superkomputer modern menggunakan algoritma konvensional diperkirakan memakan waktu lebih lama daripada usia penuh alam semesta kita [lihat Referensi. sini], bahkan komputer kuantum kecil pun dapat menyelesaikan masalah ini dalam beberapa hari. Didorong oleh janji keuntungan kuantum, para insinyur dan ilmuwan melanjutkan pencarian mereka untuk prosesor kuantum. Namun, kesulitan teknis dalam pembuatan, pengelolaan, dan perlindungan sistem kuantum sangatlah kompleks, dan prototipe pertama hanya muncul dalam dekade terakhir.
Penting untuk dicatat bahwa masalah teknis dalam membangun komputer kuantum tidak menghentikan pengembangan algoritme komputasi kuantum. Bahkan dengan tidak adanya perangkat keras, algoritme dapat dianalisis secara matematis, dan munculnya simulator komputer kuantum berkinerja tinggi serta prototipe awal dalam beberapa tahun terakhir telah memungkinkan penelitian lebih lanjut untuk maju.
Beberapa dari algoritma ini telah menunjukkan aplikasi potensial yang menjanjikan dalam biologi. Misalnya, algoritme untuk memperkirakan fase kuantum memungkinkan penghitungan nilai eigen secara eksponensial lebih cepat [lihat. di sini ], yang dapat digunakan untuk memahami korelasi skala besar antara bagian-bagian protein atau untuk menentukan sentralitas grafik dalam jaringan biologis. Algoritme Quantum Harrow-Hasidim-Lloyd (HHL) [lih. di sini ] dapat memecahkan beberapa sistem linier secara eksponensial lebih cepat daripada algoritma klasik manapun yang dikenal, dan juga dapat menerapkan metode pembelajaran statistik dengan proses adaptasi yang jauh lebih cepat dan kemampuan untuk mengelola data dalam jumlah besar.
Algoritma optimasi kuantum memiliki aplikasi yang luas di bidang pelipatan protein dan pemilihan konformer, serta dalam masalah yang terkait dengan menemukan minima atau maxima [lihat. di sini ]. Akhirnya, teknologi baru-baru ini dikembangkan untuk mensimulasikan sistem kuantum yang menjanjikan, misalnya, untuk menghasilkan prediksi akurat dari interaksi reseptor obat [lihat Referensi. di sini ] atau untuk berpartisipasi dalam studi dan pemahaman tentang proses kompleks dan mekanisme kimia seperti fotosintesis [lihat. di sini ]. Komputasi kuantum dapat secara signifikan mengubah metode biologi itu sendiri, seperti yang dilakukan komputasi klasik pada masanya.
Klaim terbaru atas supremasi kuantum dari Google [lih. sini], meskipun diperdebatkan oleh IBM [lih. di sini ], menunjukkan bahwa era komputasi kuantum tidak jauh lagi. Prosesor pertama yang menggunakan efek kuantum untuk melakukan komputasi yang tidak mungkin dilakukan oleh teknologi komputer klasik diharapkan dalam dekade berikutnya [lih. di sini ].
Dalam ulasan ini, kami akan memecah poin-poin utama di mana komputasi kuantum menjanjikan untuk biologi komputasi. Ulasan ini menganalisis dampak potensial dari komputasi kuantum di berbagai bidang, termasuk pembelajaran mesin [lih. di sini , di sini dan di sini ], kimia kuantum [lih. di sini , di sini dan di sini ] dan sintesis obat [lihat.di sini ]. Juga baru-baru ini diterbitkan adalah laporan Lokakarya NIMH tentang Komputasi Kuantum dalam Ilmu Hayati [lihat hal. di sini ].
Dalam ulasan ini, pertama-tama kami memberikan penjelasan singkat tentang apa yang dimaksud dengan komputasi kuantum dan pengantar singkat tentang prinsip-prinsip pemrosesan informasi kuantum. Kami kemudian membahas tiga bidang utama biologi komputasi, di mana komputasi kuantum telah menunjukkan perkembangan algoritme yang menjanjikan: metode statistik, kalkulasi struktur elektronik, dan pengoptimalan. Beberapa topik penting akan dikesampingkan, misalnya algoritma string yang dapat mempengaruhi analisis urutan [lihat. di sini ], algoritma pencitraan medis [lihat. di sini ], algoritma numerik untuk persamaan diferensial [di sini ] dan masalah atau metode matematika lainnya untuk menganalisis jaringan biologis [di sini ]. Terakhir, kami membahas dampak potensial komputasi kuantum pada biologi komputasi dalam jangka menengah hingga panjang.
1. Pemrosesan informasi kuantum
Komputer kuantum menjanjikan untuk memecahkan masalah dalam ilmu biologi, seperti memprediksi interaksi protein-ligan atau memahami ko-evolusi asam amino dalam protein. Dan itu tidak mudah untuk dipecahkan, tetapi melakukannya secara eksponensial lebih cepat dari yang dapat Anda bayangkan dengan komputer modern manapun. Namun, pergeseran paradigma ini membutuhkan perubahan mendasar dalam pemikiran kita: komputer kuantum sangat berbeda dari pendahulunya yang klasik. Fenomena fisik yang mendasari keunggulan kuantum seringkali tidak logis dan berlawanan dengan intuisi, dan menggunakan prosesor kuantum memerlukan perubahan mendasar dalam pemahaman kita tentang pemrograman. Di bagian ini, kami menyajikan prinsip-prinsip informasi kuantum dan bagaimana ia diproses untuk melakukan komputasi.
Kami menjelaskan bagaimana informasi bekerja secara berbeda dalam sistem kuantum, di mana ia disimpan dalam qubit, dan bagaimana informasi tersebut dapat dimanipulasi menggunakan gerbang kuantum. Seperti variabel dan fungsi dalam bahasa pemrograman, qubit dan gerbang kuantum menentukan elemen dasar algoritme apa pun. Kami juga akan memeriksa mengapa pembuatan komputer kuantum secara teknis sangat sulit dan apa yang dapat dicapai dengan bantuan prototipe awal yang diharapkan di tahun-tahun mendatang. Pendahuluan ini hanya akan membahas poin-poin utama; untuk studi yang komprehensif, bacalah buku Nielsen dan Chuang [di sini ].
1.1. Elemen algoritma kuantum
1.1.1. Informasi kuantum: pengantar qubit
Masalah pertama dalam merepresentasikan komputasi kuantum adalah memahami bagaimana ia memproses informasi. Dalam prosesor kuantum, informasi biasanya disimpan dalam qubit, yang merupakan analog kuantum bit klasik. Qubit adalah sistem fisik, seperti ion, dibatasi oleh medan magnet [lihat. di sini ] atau foton terpolarisasi [lihat. di sini ], tetapi sering dibicarakan secara abstrak. Seperti kucing Schrödinger, qubit tidak hanya memiliki status 0 atau 1, tetapi juga kemungkinan kombinasi kedua status. Saat qubit diamati secara langsung, ia tidak lagi berada dalam superposisi yang runtuh ke salah satu status yang memungkinkan, seperti kucing Schrödinger mati atau hidup setelah membuka kotak [lihat. sini]. Lebih penting lagi, ketika beberapa qubit digabungkan, mereka dapat menjadi berkorelasi, dan interaksi dengan salah satu dari mereka memiliki konsekuensi untuk keseluruhan keadaan kolektif. Fenomena korelasi antara beberapa qubit, yang dikenal sebagai keterjeratan kuantum, merupakan sumber daya fundamental untuk komputasi kuantum.
Dalam informasi klasik, unit dasar informasi adalah bit, sistem dengan dua status yang dapat diidentifikasi, sering dilambangkan dengan 0 dan 1. Analog kuantum, qubit, adalah sistem dua status, yang statusnya diberi label | 0⟩ dan | 1⟩. Kami menggunakan notasi Dirac, di mana | *⟩ mengidentifikasi status kuantum. Perbedaan utama antara informasi klasik dan kuantum adalah bahwa qubit dapat berada dalam superposisi status | 0⟩ dan | 1⟩:
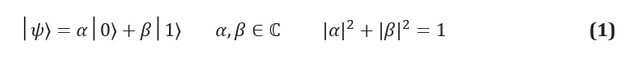
Koefisien kompleks α dan β dikenal sebagai amplitudo keadaan, dan terkait dengan konsep kunci lain dalam mekanika kuantum: efek pengukuran fisik. Karena qubit adalah sistem fisik, Anda selalu dapat membuat protokol untuk mengukur statusnya. Jika, misalnya, status | 0⟩ dan | 1⟩ sesuai dengan status spin sebuah elektron dalam medan magnet, maka mengukur status qubit hanyalah mengukur energi sistem. Postulat mekanika kuantum menyatakan bahwa jika sistem berada dalam superposisi kemungkinan hasil pengukuran, maka tindakan pengukuran harus mengubah keadaan itu sendiri. Sistem superposisi akan hancur pada tahap pengukuran; pengukuran sehingga menghancurkan informasi yang dibawa oleh amplitudo di qubit.
Implikasi komputasi yang penting muncul ketika kita mempertimbangkan sistem dari beberapa qubit yang dapat mengalami keterikatan kuantum. Keterikatan adalah fenomena di mana sekelompok qubit berkorelasi, dan operasi apa pun pada salah satu qubit ini akan memengaruhi status keseluruhan dari semuanya. Sebuah contoh kanonik dari keterjeratan kuantum adalah paradoks Einstein-Podolsky-Rosen, yang disajikan pada tahun 1935 [lih. di sini ]. Pertimbangkan sistem dua qubit, di mana, karena masing-masing qubit individu dapat mengambil superposisi keadaan {| 0⟩ dan | 1⟩}, sistem komposit dapat mengambil superposisi keadaan {| 00⟩, | 01⟩, | 10⟩, | 11 ⟩} (Dan, karenanya, sistem N-qubit dapat mengambil salah satu dari string biner, dari {| 0 ... 0⟩ hingga | 1 ... 1⟩}. Salah satu superposisi yang mungkin dari sistem adalah yang disebut status Bell, yang salah satunya memiliki bentuk berikut: Jika kita melakukan pengukuran pada qubit pertama, kita hanya dapat mengamati | 0⟩ atau | 1⟩, yang masing-masing memiliki probabilitas 1/2. Ini tidak membuat perubahan apa pun untuk kasus qubit tunggal. Jika hasil untuk qubit pertama adalah | 0⟩, sistem akan runtuh ke sistem | 01⟩, dan oleh karena itu setiap pengukuran pada qubit kedua akan memberikan | 1⟩ dengan probabilitas 1; demikian pula, jika pengukuran pertama adalah | 1⟩, pengukuran pada qubit kedua akan menghasilkan | 0⟩. Operasi (dalam hal ini, pengukuran dengan hasil "0") yang diterapkan pada qubit pertama mempengaruhi hasil yang dapat dilihat ketika qubit kedua diukur selanjutnya.

Keberadaan keterjeratan sangat penting bagi komputasi kuantum yang berguna. Telah dibuktikan bahwa algoritma kuantum apa pun yang tidak menggunakan keterjeratan dapat diterapkan pada komputer klasik tanpa perbedaan kecepatan yang signifikan [lih. di sini dan di sini ]. Secara intuitif, alasan adalah jumlah informasi yang dapat dimanipulasi oleh komputer kuantum. Jika sistem N qubit tidak terjerat, makaAmplitudo 2 N dari statusnya dapat dijelaskan oleh amplitudo dari setiap status satu bit, yaitu amplitudo 2N. Namun, jika sistem terjerat, semua amplitudo akan independen, dan register qubit akan terbentuk vektor dimensi N. Kemampuan komputer kuantum untuk memanipulasi informasi dalam jumlah besar dengan banyak operasi adalah salah satu keunggulan utama algoritme kuantum dan menopang kemampuan mereka untuk memecahkan masalah secara eksponensial lebih cepat daripada teknologi komputer klasik.
1.1.2. Gerbang kuantum
Informasi yang disimpan dalam qubit diproses menggunakan operasi khusus yang dikenal sebagai gerbang kuantum. Gerbang kuantum adalah operasi fisik, seperti pulsa laser yang diarahkan ke qubit ion, atau sekumpulan cermin dan pemecah berkas yang melaluinya qubit foton harus berjalan. Namun, gerbang sering kali dipandang sebagai operasi abstrak. Postulat mekanika kuantum memberlakukan beberapa kondisi ketat pada sifat gerbang kuantum dalam sistem tertutup, yang memungkinkannya direpresentasikan dalam bentuk matriks kesatuan, yang merupakan operasi linier yang mempertahankan normalisasi sistem kuantum.
Secara khusus, gerbang kuantum yang diterapkan pada register terjerat N qubit setara dengan mengalikan matriks × per vektor masukan . Kemampuan komputer kuantum untuk menyimpan dan melakukan komputasi sejumlah besar informasi adalah urutannya - dengan memanipulasi banyak elemen - berorde N - membentuk dasar kemampuannya untuk memberikan keuntungan yang berpotensi eksponensial dibandingkan komputer klasik. Pada dasarnya, gerbang kuantum adalah operasi yang diizinkan dalam sistem qubit. Postulat mekanika kuantum memberlakukan dua batasan ketat pada bentuk gerbang kuantum. Operator kuantum bersifat linier. Linearitas adalah kondisi matematis yang memiliki implikasi mendalam bagi fisika sistem kuantum dan, oleh karena itu, bagaimana mereka dapat digunakan untuk komputasi. Jika operator linier diterapkan pada superposisi keadaan
, hasilnya adalah superposisi dari masing-masing negara, yang dipengaruhi oleh operator. Dalam qubit, ini berarti: Operator linier dapat direpresentasikan dalam bentuk matriks, yang merupakan tabel sederhana yang menunjukkan pengaruh operator linier pada setiap status basis. Gambar 1 (c, d) menunjukkan representasi matriks dari salah satu dari dua gerbang qubit dan dua gerbang satu-bit. Namun, tidak setiap matriks mewakili gerbang kuantum nyata. Kami berharap bahwa gerbang kuantum yang diterapkan pada kumpulan qubit akan memberikan kumpulan qubit nyata yang berbeda, khususnya, qubit yang dinormalisasi (misalnya, dalam persamaan (3) kami mengharapkan bahwa
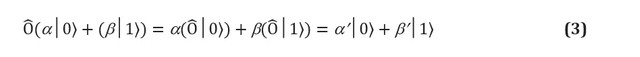
× adalah gerbang kuantum N-qubit yang sepenuhnya valid.
Dalam komputasi klasik, hanya ada satu gerbang non-trivial per bit: gerbang NOT, yang mengubah 0 menjadi 1 dan sebaliknya. Dalam komputasi kuantum, ada sejumlah tak terhingga dari matriks kesatuan 2 × 2, dan salah satunya adalah kemungkinan gerbang kuantum satu qubit. Salah satu keberhasilan awal komputasi kuantum adalah penemuan bahwa berbagai kemungkinan yang luas ini dapat direalisasikan dengan satu set gerbang universal yang memengaruhi satu dan dua qubit [lihat Referensi. sini]. Dengan kata lain, jika diberi gerbang kuantum sewenang-wenang, ada rangkaian gerbang satu dan dua qubit yang dapat mengendarainya dengan presisi yang sewenang-wenang. Sayangnya, ini tidak berarti bahwa pendekatan tersebut efektif. Kebanyakan gerbang kuantum hanya dapat didekati dengan sejumlah gerbang eksponensial dari himpunan universal kita. Bahkan jika gerbang ini dapat digunakan untuk memecahkan masalah yang berguna, implementasinya akan membutuhkan waktu yang sangat lama dan dapat meniadakan keuntungan kuantum apa pun. GAMBAR 1 (a) Perbandingan bit klasik dengan bit kuantum atau "qubit". Sementara bit klasik hanya dapat mengambil satu dari dua keadaan, 0 atau 1, bit kuantum dapat mengambil bentuk apapun

... Qubit tunggal sering digambarkan menggunakan representasi bola Bloch, di mana θ dan ϕ dipahami sebagai sudut azimut dan kutub dalam bidang radius satuan. (b) Skema qubit perangkap ion, salah satu pendekatan paling umum untuk komputasi kuantum eksperimental. Ion (sering) diadakan dalam ruang hampa tinggi oleh medan elektromagnetik dan terkena medan magnet yang kuat. Level hyperfine dipisahkan menurut efek Zeeman, dan dua level yang dipilih dipilih sebagai status | 0⟩ dan | 1⟩. Gerbang kuantum diproduksi oleh pulsa laser yang sesuai, sering kali melibatkan level elektronik lainnya. Diagram ini diadaptasi dari [lihat. di sini ]. (c) Diagram rangkaian kuantum yang mengimplementasikan X atau kuantum negasi terkontrol (CNOT).
Representasi dan perubahan dalam lingkup Bloch ditampilkan. (d) Sirkuit kuantum untuk menghasilkan status Bellmenggunakan gerbang Hadamard dan gerbang CNOT (negasi terkontrol). Garis putus-putus di tengah garis luar menunjukkan keadaan setelah katup Hadamard dipasang.
1.2. Perangkat keras kuantum
Algoritme kuantum hanya dapat menyelesaikan masalah menarik jika dijalankan pada perangkat keras kuantum yang tepat. Ada banyak proposal yang bersaing untuk menciptakan prosesor kuantum berdasarkan ion yang terperangkap [lihat. di sini ], sirkuit superkonduktor [lihat. di sini ] dan perangkat fotonik [lihat. sini]. Namun, mereka semua menghadapi masalah yang sama: kesalahan komputasi yang secara harfiah dapat merusak proses komputasi. Salah satu landasan komputasi kuantum adalah penemuan bahwa kesalahan ini dapat dihilangkan dengan kode koreksi kesalahan kuantum. Sayangnya, kode-kode ini juga membutuhkan peningkatan jumlah qubit yang sangat besar, sehingga diperlukan perbaikan teknis yang signifikan untuk mencapai toleransi kesalahan.
Ada banyak sumber kesalahan yang dapat memengaruhi prosesor kuantum. Misalnya, koneksi qubit dengan lingkungannya dapat menyebabkan runtuhnya sistem ke salah satu keadaan klasiknya - sebuah proses yang dikenal sebagai dekoherensi.... Fluktuasi kecil dapat mengubah gerbang kuantum, yang pada akhirnya memberikan hasil yang berbeda dari yang diharapkan. Gerbang yang paling tidak rentan kesalahan hingga saat ini telah direkam dalam prosesor ion yang terperangkap, dengan frekuensi satu kesalahan pergerbang satu qubit dan dengan tingkat kesalahan 0,1% untuk gerbang dua qubit [di sini dan di sini ]. Sebagai perbandingan, sebuah karya terbaru oleh Google melaporkan ketepatan 0,1% untuk gerbang qubit tunggal dan 0,3% untuk gerbang dua qubit dalam prosesor superkonduktor [lihat Referensi. di sini ]. Mengingat bahwa kegagalan satu gateway dapat merusak perhitungan, mudah untuk melihat bahwa kesalahan propagasi dapat membuat perhitungan tidak berarti setelah urutan elemen yang kecil.
Salah satu arah utama komputasi kuantum adalah pengembangan kode koreksi kesalahan kuantum. Pada 1990-an, beberapa kelompok penelitian membuktikan bahwa kode-kode ini dapat mencapai komputasi yang toleran terhadap kesalahan, asalkan tingkat kesalahan gerbang di bawah ambang tertentu, yang bergantung pada kode [lihat. disini , disini , disini dan disini ]. Salah satu pendekatan yang paling populer, kode permukaan, dapat beroperasi dengan tingkat kesalahan mendekati 1% [lihat Referensi. di sini ].
Sayangnya, kode koreksi kesalahan kuantum memerlukan sejumlah besar qubit fisik nyata untuk menyandikan qubit logis abstrak yang digunakan untuk komputasi, dan overhead ini meningkat seiring dengan laju kesalahan. Misalnya, algoritma kuantum untuk memfaktorkan bilangan prima [lihat. di sini ] dapat secara diam-diam menguraikan nomor 2000-bit menggunakan sekitar 4000 qubit dan, pada 16 GHz, proses ini akan memakan waktu kerja sekitar satu hari. Dengan asumsi tingkat kesalahan menjadi 0,1%, algoritma yang sama, menggunakan kode permukaan untuk memperbaiki kesalahan lingkungan, akan membutuhkan beberapa juta qubit dan jumlah waktu yang sama [lihat. sini]. Mempertimbangkan bahwa rekor saat ini untuk prosesor kuantum yang dapat diprogram dan terkontrol adalah 53 qubit [lihat. di sini ], arah penelitian ini masih panjang.
Banyak kelompok telah berusaha untuk mengembangkan algoritma yang dapat dijalankan pada apa yang disebut prosesor kuantum kebisingan skala menengah [lih. di sini ]. Misalnya, algoritme variasional menggabungkan komputer klasik dengan prosesor kuantum kecil, melakukan sejumlah besar komputasi kuantum pendek yang dapat dilakukan sebelum derau menjadi signifikan.
Algoritme ini sering menggunakan sirkuit kuantum berparameter, yang melakukan tugas yang sangat sulit, dan menggunakan komputer klasik untuk mengoptimalkan parameter. Metode resolusi adalah wilayah pengurangan kesalahan di mana, alih-alih mencapai toleransi kesalahan, upaya dilakukan untuk meminimalkan kesalahan dengan upaya minimal untuk menggerakkan sirkuit gerbang yang lebih besar. Ada sejumlah pendekatan yang mencakup penggunaan operasi tambahan untuk membuang proses yang mengalami kesalahan [lihat. di sini ] atau manipulasi tingkat kesalahan untuk memperkirakan hasil yang benar [lih. disini dan disini]. Meskipun aplikasi utama akan membutuhkan komputer kuantum yang toleran terhadap kesalahan yang sangat besar; perangkat yang tersedia selama dekade berikutnya diharapkan dapat memecahkan masalah ini [lihat di sini ].
2. Metode statistik dan pembelajaran mesin
Dalam biologi komputasi, yang sering kali tujuannya adalah mengumpulkan data dalam jumlah besar, metode statistik dan pembelajaran mesin adalah teknik utama. Misalnya, dalam genomik, model Markov tersembunyi (HMM) banyak digunakan untuk memberi keterangan informasi tentang gen [lihat. di sini ]; selama penemuan obat, berbagai model statistik telah dikembangkan untuk menilai sifat molekuler atau untuk memprediksi ikatan ligan-protein [lihat. di sini ]; dan dalam biologi struktural, jaringan saraf dalam telah digunakan baik untuk memprediksi koneksi protein [lihat. di sini ] dan struktur sekunder [lihat. di sini ], dan baru-baru ini juga struktur protein tiga dimensi [lihat. di sini ].
Pelatihan dan pengembangan model semacam itu sering kali intensif secara komputasi. Katalis utama untuk kemajuan terbaru dalam pembelajaran mesin adalah kesadaran bahwa unit pemrosesan grafis (GPU) tujuan umum dapat mempercepat pembelajaran secara dramatis. Dengan menyediakan algoritme yang lebih cepat secara eksponensial untuk pembelajaran mesin, model komputasi kuantum dapat memberikan minat yang sama dalam fokus aplikasi untuk masalah ilmiah.
Di bagian ini, kami akan menjelaskan bagaimana komputasi kuantum dapat mempercepat berbagai metode pembelajaran statistik.
2.1. Keuntungan dan Kerugian dari Quantum Machine Learning
Kami pertama kali melihat manfaat yang diberikan komputer kuantum untuk pembelajaran mesin. Kecuali untuk contoh yang ideal, komputer kuantum tidak dapat mempelajari informasi lebih dari komputer klasik [lih. di sini ]. Namun, pada prinsipnya mereka bisa jauh lebih cepat dan mampu memproses lebih banyak data daripada rekan klasik mereka. Misalnya, genom manusia mengandung 3 miliar pasangan basa, yang dapat disimpan dalam 1,2 ×bit klasik - sekitar 1,5 gigabyte. Sebuah register N qubit termasukamplitudo, yang masing-masing dapat merepresentasikan bit klasik dengan mengatur amplitudo ke-k ke 0 atau 1 dengan faktor normalisasi yang sesuai. Karenanya, genom manusia dapat disimpan dalam ~ 34 qubit. Meskipun informasi ini tidak dapat diekstraksi dari komputer kuantum, hingga status tertentu disiapkan, masih dimungkinkan untuk mengeksekusi algoritme pembelajaran mesin tertentu di dalamnya. Lebih penting lagi, menggandakan ukuran register menjadi 68 qubit menyisakan cukup ruang untuk menyimpan genom lengkap setiap orang yang hidup di dunia. Penyajian dan analisis data dalam jumlah besar tersebut akan cukup konsisten dengan kemampuan komputer kuantum yang toleran terhadap kesalahan yang kecil sekalipun.
Operasi untuk memproses informasi ini juga bisa lebih cepat secara eksponensial. Misalnya, beberapa algoritme pembelajaran mesin dibatasi pada inversi jangka panjang dari matriks kovarians dengan penaltipada dimensi matriks. Namun, algoritma yang diusulkan oleh Harrow, Hassidim, dan Lloyd [lih. di sini ], memungkinkan Anda untuk membalik matriks menjadidalam beberapa kondisi. Wawasan utamanya adalah, tidak seperti GPU, yang mempercepat komputasi melalui paralelisme masif, algoritme kuantum memiliki keuntungan dari kerumitan algoritme komputasi yang langsung digunakan. Dalam beberapa kasus, terutama dengan percepatan eksponensial saat ini, komputer kuantum menengah dapat memecahkan masalah pembelajaran yang hanya tersedia untuk superkomputer klasik terbesar yang ada saat ini.
Penyimpanan dan pemrosesan data yang ditingkatkan memiliki manfaat sekunder. Salah satu kekuatan jaringan saraf adalah kemampuannya untuk menemukan representasi data yang ringkas [lihat. sini]. Karena informasi kuantum lebih umum daripada informasi klasik (bagaimanapun juga, status bit klasik dibagi lagi menjadi status eigen | 0⟩ dan | 1⟩, atau qubit), sangat mungkin model pembelajaran mesin kuantum dapat mengasimilasi informasi dengan lebih baik daripada model klasik ... Di sisi lain, algoritma kuantum dengan kompleksitas waktu logaritmik juga meningkatkan kerahasiaan data [lihat. di sini ]. Sejak pelatihan model membutuhkan, dan memerlukan rekonstruksi matriks, untuk kumpulan data yang cukup besar, tidak mungkin untuk memulihkan sebagian besar informasi, meskipun pelatihan model yang efektif masih memungkinkan. Dalam konteks penelitian biomedis, hal ini dapat memfasilitasi pertukaran data dengan tetap menjaga kerahasiaan.
Sayangnya, meskipun algoritme pembelajaran mesin kuantum berbasis kertas dapat mengungguli algoritme klasiknya, kesulitan praktis masih tetap ada. Algoritme kuantum sering kali merupakan subrutin yang mengubah masukan menjadi keluaran. Masalah muncul tepat pada dua tahap ini: bagaimana menyiapkan masukan yang memadai dan cara mengekstrak informasi dari keluaran [lihat. di sini ]. Misalkan, sebagai contoh, kita menggunakan algoritma HHL [lihat. di sini ] untuk menyelesaikan sistem linier dari bentuk... Di akhir subrutin, algoritme akan mengeluarkan register qubit dalam kondisi berikut: Di sini
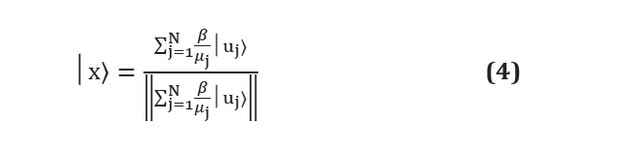
dan Apakah vektor eigen dan nilai eigen dari A, dan - koefisien j-th dinyatakan dalam vektor eigen dari A, dan penyebutnya hanyalah konstanta normalisasi. Dapat dilihat bahwa ini sesuai dengan koefisien, yang disimpan dalam amplitudo berbagai status sebagai dan tidak dapat diakses secara langsung. Pengukuran register qubit akan menyebabkan keruntuhannya menjadi salah satu status vektor eigen, dan memperkirakan ulang amplitudo masing-masing. pengukuran diperlukan , yang terlebih dahulu melebihi keuntungan apa pun dari algoritme kuantum.
HHL dan banyak algoritme lainnya hanya berguna untuk menghitung properti global suatu solusi, seperti nilai yang diharapkan. Dengan kata lain, HHL tidak dapat memberikan solusi untuk sistem persamaan atau membalikkan matriks dalam waktu logaritmik, kecuali kita hanya tertarik pada properti global dari solusi tersebut, yang dapat diperoleh dengan menggunakan beberapa pengukuran yang dapat diamati secara fisik. Ini membatasi penggunaan beberapa rutinitas, tetapi ada banyak saran untuk mengatasi masalah ini.
Memasukkan informasi ke dalam komputer kuantum adalah masalah yang jauh lebih besar. Sebagian besar algoritme pembelajaran mesin kuantum mengasumsikan bahwa komputer kuantum memiliki akses ke kumpulan data dalam bentuk status superposisi; misalnya ada register qubit yang berbentuk: Disini - | bin (j) adalah state yang berfungsi sebagai indeks, dan

Apakah amplitudo yang sesuai. Ini dapat digunakan, misalnya, untuk menyimpan elemen vektor atau matriks. Pada prinsipnya, ada rangkaian kuantum yang dapat mempersiapkan keadaan ini dengan bertindak dalam, katakanlah, keadaan | 0 ... 0⟩. Namun, implementasinya bisa sangat sulit, karena kami berharap bahwa perkiraan keadaan kuantum acak akan sangat sulit secara eksponensial dan akan menghancurkan keuntungan kuantum yang mungkin.
Kebanyakan algoritma kuantum mengasumsikan akses ke memori akses acak kuantum (QRAM) [lihat. di sini ], yang merupakan perangkat kotak hitam yang mampu membangun superposisi ini. Meskipun beberapa gambar telah diusulkan [lihat. disini dan disini], sejauh yang kami tahu, belum ada perangkat yang berfungsi. Selain itu, meskipun perangkat semacam itu tersedia, tidak ada jaminan bahwa perangkat tersebut tidak akan menciptakan hambatan yang melebihi manfaat algoritme kuantum. Misalnya, proposal berbasis skema baru-baru ini untuk QRAM [lih. di sini ] menunjukkan biaya linier yang tak terelakkan dari jumlah status yang melebihi algoritme waktu logaritmik mana pun. Terakhir, meskipun QRAM tidak mengenakan biaya tambahan, pemrosesan awal klasik masih perlu dilakukan - untuk contoh genom, akses ke penyimpanan klasik 12 exabyte akan diperlukan.
Akhirnya, kita harus menekankan bahwa algoritma pembelajaran mesin kuantum tidak bebas dari salah satu masalah paling umum dalam aplikasi praktis: kurangnya data yang relevan. Ketersediaan data dalam jumlah besar sangat penting untuk keberhasilan banyak aplikasi praktis AI dalam ilmu molekuler, seperti pengembangan molekuler de novo [lihat Ref. di sini ]. Namun, kekuatan algoritme kuantum dapat berguna seiring perkembangan ilmiah dan teknologi seperti munculnya laboratorium mandiri [lihat. di sini ] menyediakan lebih banyak data.
Pembelajaran mesin kuantum memiliki potensi untuk mengubah cara kami memproses dan menganalisis data biologis. Namun, masalah praktis penerapan teknologi kuantum saat ini masih signifikan.
2.2. Algoritme pembelajaran mesin kuantum
2.2.1. Belajar tanpa guru
Pembelajaran tanpa pengawasan melibatkan beberapa teknik untuk mengekstraksi informasi dari kumpulan data yang tidak diberi tag. Dalam biologi, di mana sekuensing generasi mendatang dan kolaborasi internasional yang hebat telah merangsang pengumpulan data, metode ini telah digunakan secara luas, misalnya, untuk mengidentifikasi hubungan antara keluarga biomolekul [lihat. di sini ] atau genom beranotasi [lihat. di sini ].
Salah satu algoritma pembelajaran tanpa pengawasan yang paling populer adalah analisis komponen utama (PCA), yang mencoba untuk mengurangi dimensi data dengan menemukan kombinasi linier dari fitur yang memaksimalkan varians [lih. sini]. Metode ini banyak digunakan di semua jenis dataset berdimensi tinggi, termasuk microarray RNA dan data spektrometri massa [lihat. di sini ]. Algoritma kuantum untuk PCA diusulkan oleh sekelompok peneliti [lihat. di sini ]. Intinya, algoritma ini membangun matriks kovarian data dalam komputer kuantum dan menggunakan subrutin yang dikenal sebagai estimasi fase kuantum untuk menghitung vektor eigen dalam waktu logaritmik. Data keluaran dari algoritma ini berupa keadaan superposisi: Disini

Apakah komponen utama ke-j, dan - nilai eigen yang sesuai. Karena PCA tertarik pada nilai eigen yang besar, yang merupakan komponen utama varians, pengukuran keadaan akhir akan memberikan komponen utama yang sesuai dengan probabilitas tinggi. Mengulangi algoritme beberapa kali akan menghasilkan sekumpulan komponen inti. Prosedur ini mampu mereduksi dimensi dari sejumlah besar informasi yang dapat disimpan dalam komputer kuantum.
Algoritma kuantum juga telah diusulkan untuk metode tertentu untuk menganalisis data topologi, yaitu untuk homologi stabil [lihat. di sini ]. Analisis data topologi mencoba mengekstrak informasi menggunakan properti topologi dalam geometri kumpulan data; itu digunakan, misalnya, dalam studi agregasi data [lihat.di sini ] dan analisis jaringan [lihat. di sini ]. Sayangnya, algoritme klasik terbaik memiliki ketergantungan eksponensial dalam dimensi masalah, yang membatasi penerapannya. Algoritma Lloyd et al. juga menggunakan rutinitas estimasi fase kuantum untuk mempercepat diagonalisasi matriks secara eksponensial, mencapai kompleksitas... Kehadiran algoritma yang efisien untuk melakukan analisis topologi dapat merangsang penerapannya untuk analisis masalah dalam ilmu biologi.
2.2.2. Pembelajaran yang diawasi
Supervised Learning mengacu pada sekumpulan metode yang dapat digunakan untuk membuat prediksi berdasarkan data berlabel. Tujuannya adalah untuk membangun model yang dapat mengklasifikasikan atau memprediksi properti dari contoh yang tidak terlihat. Pembelajaran yang diawasi secara luas digunakan dalam biologi untuk memecahkan masalah yang beragam seperti memprediksi afinitas pengikatan ligan untuk protein [lihat. di sini ] dan diagnosis penyakit menggunakan komputer [lihat. di sini ]. Mari kita lihat tiga pendekatan pembelajaran yang diawasi.
Mendukung Mesin Vektor(Bahasa Inggris support vector machine - SVM) adalah algoritma pembelajaran mesin yang menemukan hyperplane memisahkan kelas data yang optimal. SVM telah banyak digunakan dalam industri farmasi untuk mengklasifikasikan data molekul kecil [lih. di sini ]. Tergantung pada kernelnya, pelatihan SVM biasanya diambil dari sebelum ... Rebentrost [lihat. di sini ] menyajikan algoritme kuantum yang dapat melatih SVM dengan kernel polinomial di, dan kemudian diperluas ke inti dari fungsi dasar radial (RBF) [lihat. di sini ]. Sayangnya, tidak jelas bagaimana mengimplementasikan operasi non-linier yang banyak digunakan dalam SVM, mengingat operasi kuantum dibatasi menjadi linier. Di sisi lain, komputer kuantum memungkinkan jenis nuklei lain yang tidak dapat direalisasikan di komputer klasik [lihat. di sini ].
Regresi proses Gaussian (GP) adalah teknik yang biasa digunakan untuk membangun model pengganti, misalnya dalam optimasi Bayesian [lihat. di sini ]. Dokter umum juga banyak digunakan untuk membuat model kuantitatif hubungan struktur-aktivitas (QSAR) dari sifat obat.di sini ], dan baru-baru ini juga untuk pemodelan dinamika molekul [lihat. di sini ]. Salah satu kelemahan dari regresi GP adalah nilainya yang tinggiinversi dari matriks kovarians. Zhao dan rekan [lihat. di sini ] menyarankan menggunakan algoritma HHL untuk sistem linier untuk membalikkan matriks ini, mencapai percepatan eksponensial (selama matriks jarang dan dikondisikan dengan baik) - properti yang sering dicapai oleh matriks kovarian. Lebih penting lagi, algoritma ini telah diperluas untuk menghitung logaritma dari kemungkinan pembatas [lih. di sini ], yang merupakan langkah penting untuk pengoptimalan hyperparameter.
Salah satu metode paling umum dalam biologi komputasi adalah model Markov tersembunyi (HMM), yang banyak digunakan dalam anotasi gen komputasi dan penyelarasan urutan [lih. sini]. Metode ini berisi sejumlah status tersembunyi, yang masing-masing terkait dengan rantai Markov; transisi antara status tersembunyi menyebabkan perubahan dalam distribusi yang mendasarinya. Pada dasarnya, HMM tidak dapat langsung diimplementasikan di komputer kuantum: pengambilan sampel memerlukan beberapa jenis pengukuran yang akan mengganggu sistem. Namun demikian, ada rumusan dalam hal sistem kuantum terbuka, yaitu sistem kuantum yang bersentuhan dengan lingkungan, yang mengakui sistem Markov [lihat. di sini ]. Meskipun tidak ada peningkatan yang telah diusulkan pada algoritme Baum-Welch klasik untuk melatih HMM, HMM kuantum ditemukan lebih ekspresif: mereka dapat mereproduksi distribusi dengan lebih sedikit status tersembunyi [lih. sini]. Hal ini dapat mengarah pada penerapan metode yang lebih luas dalam biologi komputasi.
2.2.3. Jaringan saraf dan pembelajaran mendalam
Perkembangan terbaru dalam pembelajaran mesin telah dirangsang oleh penemuan bahwa beberapa lapisan jaringan saraf tiruan dapat mendeteksi struktur kompleks dalam data mentah [lihat hal. di sini ]. Pembelajaran mendalam telah mulai menembus setiap disiplin ilmu, dan dalam biologi komputasi, kemajuannya mencakup prediksi akurat dari ikatan protein. di sini ], diagnosis yang lebih baik dari beberapa penyakit [lihat. di sini ], desain molekuler [lih. di sini ] dan pemodelan [lihat. di sini dan di sini ].
Mengingat kemajuan signifikan dalam studi jaringan saraf, pekerjaan signifikan telah dilakukan untuk mengembangkan analog kuantum yang dapat mendorong kemajuan teknologi lebih lanjut.
Nama jaringan saraf tiruan sering mengacu pada perceptron multilayer dari jaringan saraf, di mana setiap neuron mengambil kombinasi linier berbobot dari inputnya dan mengembalikan hasilnya melalui fungsi aktivasi non-linier. Tantangan utama dalam mengembangkan analog kuantum adalah bagaimana mengimplementasikan fungsi aktivasi nonlinier menggunakan gerbang kuantum linier. Ada banyak saran akhir-akhir ini, dan beberapa gagasan mencakup pengukuran [lih. di sini , di sini dan di sini ], gerbang kuantum disipatif [ di sini], komputasi kuantum dengan variabel kontinu [di sini ] dan pengenalan qubit tambahan untuk membangun gerbang linier yang mensimulasikan nonlinier [lihat. di sini ]. Pendekatan ini bertujuan untuk mengimplementasikan jaringan saraf kuantum yang diharapkan lebih ekspresif daripada jaringan saraf klasik karena kekuatan informasi kuantum yang lebih besar. Keuntungan atau kerugian dari penskalaan pelatihan perceptron multilayer dalam komputer kuantum tidak jelas, meskipun fokusnya adalah pada kemungkinan peningkatan ekspresi model ini.
Sejumlah besar upaya baru-baru ini difokuskan pada mesin Boltzmann, jaringan saraf berulang yang dapat bertindak sebagai model generatif. Setelah dilatih, mereka dapat menghasilkan pola baru yang mirip dengan set pelatihan.
Model generatif memiliki aplikasi penting, misalnya, dalam desain molekuler de novo [lih. di sini dan di sini ]. Meskipun mesin Boltzmann sangat kuat, masalah kompleks pengambilan sampel dari distribusi Boltzmann harus diselesaikan untuk menghitung gradien dan melakukan pelatihan, yang membatasi aplikasi praktisnya. Algoritma kuantum telah diusulkan menggunakan mesin D-Wave [lihat. di sini , di sini dan di sini ] atau algoritma rangkaian [lihat.di sini ]; sampel dari distribusi Boltzmann ini secara kuadrat lebih cepat daripada yang dimungkinkan dalam versi klasik [lihat. di sini ].
Baru-baru ini, heuristik untuk pelatihan yang efisien dari mesin Boltzmann kuantum telah diusulkan, berdasarkan termalisasi sistem [lihat. di sini ]. Selain itu, dalam beberapa karya, implementasi kuantum jaringan adversarial generatif (GAN) telah diusulkan [lihat. disini , disini dan disini ]. Perkembangan ini melibatkan peningkatan model generatif seiring dengan berkembangnya perangkat keras komputasi kuantum.
3. Simulasi sistem kuantum yang efektif
Menurut model, kimia diatur oleh transfer elektron. Reaksi kimia, serta interaksi antara entitas kimia, juga dikontrol oleh distribusi elektron dan lanskap energi bebas yang mereka bentuk. Masalah seperti memprediksi ikatan ligan ke protein atau memahami jalur katalitik enzim bermuara pada pemahaman lingkungan elektronik. Sayangnya, pemodelan proses ini sangat sulit. Algoritme paling efisien untuk menghitung energi sistem elektron, interaksi konfigurasi penuh (FCI), yang berskala eksponensial seiring bertambahnya jumlah elektron, dan bahkan molekul dengan beberapa atom karbon hampir tidak tersedia untuk penelitian komputasi [lihat. sini]. Meskipun ada banyak metode perkiraan, dijelaskan secara mendalam dan ekstensif dalam publikasi tentang teori fungsional kerapatan [lihat. di sini dan di sini ], mereka bisa jadi tidak akurat dan bahkan tiba-tiba gagal dalam banyak situasi yang menarik, seperti simulasi keadaan respons sementara [lih. di sini ]. Algoritme yang akurat dan efisien untuk mempelajari struktur elektronik akan memungkinkan pemahaman yang lebih baik tentang proses biologis, dan juga membuka peluang untuk pengembangan interaksi biologis generasi berikutnya.
Komputer kuantum pada awalnya diusulkan sebagai metode untuk pemodelan sistem kuantum yang lebih efisien. Pada tahun 1996, Seth Lloyd mendemonstrasikan bahwa hal ini dimungkinkan untuk jenis sistem kuantum tertentu [ di sini], dan satu dekade kemudian, Alan Aspuru-Guzik dan rekannya menunjukkan bahwa sistem kimia adalah salah satunya [di sini ]. Selama dua dekade terakhir, telah ada penelitian yang signifikan ke dalam metode pemodelan fine-tuning untuk sistem kimia yang dapat menghitung properti yang diminati penelitian.
3.1. Keuntungan dan Kerugian Simulasi Kuantum
Pada prinsipnya, komputer kuantum dapat secara efisien menyelesaikan masalah struktur elektronik yang sepenuhnya berkorelasi (persamaan FCI), yang akan menjadi langkah pertama untuk memperkirakan energi pengikatan secara akurat, serta mensimulasikan dinamika sistem kimia. Kimia komputasi klasik berfokus hampir secara eksklusif pada metode perkiraan, yang telah berguna, misalnya, untuk memperkirakan kuantitas termokimia dari molekul kecil [ di sini], tetapi ini mungkin tidak cukup untuk proses yang terkait dengan pemutusan atau pembentukan ikatan. Sebaliknya, prosesor kuantum berpotensi memecahkan masalah elektronik dengan mendiagonalisasi langsung matriks FCI, memberikan hasil yang akurat dalam himpunan basis tertentu dan dengan demikian memecahkan banyak masalah yang timbul dari deskripsi yang salah tentang fisika proses molekuler (misalnya, polarisasi ligan) ... Selain itu, tidak seperti pendekatan klasik, pendekatan ini tidak selalu memerlukan proses berulang, meskipun asumsi awal tetap penting.
Meskipun komputer kuantum tidak dipelajari secara mendalam, mereka juga mengatasi perkiraan pembatas yang diperlukan dalam komputasi klasik. Misalnya, perumusan simulasi kuantum di ruang nyata secara otomatis memperhitungkan fungsi gelombang nuklir jika tidak ada pendekatan Born-Oppenheimer [di sini ]. Hal ini memungkinkan seseorang untuk mempelajari efek non-adiabatik dari beberapa sistem yang diketahui penting untuk mutasi DNA [lihat. di sini ] dan mekanisme kerja banyak enzim [di sini ]. Aplikasi komputasi kuantum untuk pemodelan sistem relativistik juga telah diusulkan [lihat. di sini ], yang berguna untuk mempelajari logam transisi yang muncul di pusat aktif banyak enzim.
Dalam artikel oleh Reicher dan rekan [lihat di sini ] konsep skala waktu untuk menghitung struktur elektronik dalam komputer kuantum terungkap. Para penulis menganggap kofaktor FeMo dari enzim nitrogenase, mekanisme fiksasi nitrogen yang belum dipelajari dan terlalu kompleks untuk dipelajari dengan menggunakan pendekatan komputasi modern. Perhitungan FCI dasar minimum untuk FeMoCo akan memakan waktu beberapa bulan dan sekitar 200 juta qubit dari kelas tertinggi yang tersedia saat ini. Namun perkiraan tersebut harus berubah dengan pesatnya perkembangan teknologi. Selama 3 tahun sejak publikasi, kemajuan algoritmik telah mengurangi persyaratan waktu dengan beberapa kali lipat [lihat. sini]. Selain metode yang lebih kuat dari struktur elektronik, versi cepat dari metode perkiraan modern yang telah diteliti baru-baru ini [lih. di sini dan di sini ] dapat secara signifikan mempercepat pembuatan prototipe, yang dapat berguna, misalnya, ketika mempelajari koordinat reaksi reaksi enzimatik, yang area ini menjadi masalah bagi enzim komputer komputasi [di sini ]. Selain itu, dengan pemahaman yang lebih baik tentang interaksi antarmolekul yang dikatalisasi oleh akses ke komputasi yang sepenuhnya berkorelasi atau akses ke bandwidth yang lebih cepat yang meningkatkan parameterisasi, pemodelan kuantum dapat secara signifikan meningkatkan teknik pemodelan non-kuantum seperti medan gaya.
Satu hal terakhir yang harus diperhatikan adalah bahwa tidak seperti bidang penelitian algoritme lainnya, seperti belajar dengan mesin kuantum, ada sejumlah algoritme simulasi kuantum jangka pendek yang dapat dijalankan pada perangkat keras yang sudah ada sebelumnya. Banyak grup eksperimental di seluruh dunia telah melaporkan demonstrasi yang berhasil dari algoritme ini [di sini , di sini , di sini , dan di sini ].
Sayangnya, ada juga beberapa kelemahan dalam pemodelan sistem kuantum. Seperti dibahas di atas, sangat sulit mengekstrak informasi dari komputer kuantum. Merekonstruksi seluruh fungsi gelombang lebih sulit daripada menghitungnya dengan cara klasik. Ini merupakan kerugian penting untuk masalah kimia, di mana argumen yang didasarkan pada struktur elektronik menjadi sumber pemahaman utama. Namun, dibandingkan dengan pembelajaran mesin, keuntungannya jauh lebih besar daripada kerugiannya, dan simulasi kuantum diharapkan menjadi salah satu aplikasi pertama yang berguna dari komputasi kuantum praktis [lihat Referensi. di sini ].
3.2. Komputasi Kuantum Toleran Kesalahan
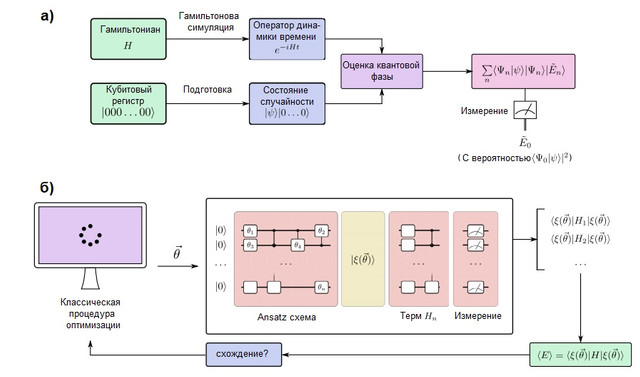
GAMBAR 2. (a) Sebuah algoritma simulasi kuantum dalam komputer kuantum yang toleran terhadap kesalahan. Qubit dibagi menjadi dua register: satu disiapkan di negara bagian, yang menyerupai fungsi gelombang target, sedangkan yang lainnya tetap dalam status ... Algoritma Quantum Phase Estimation (QPE) digunakan untuk mencari nilai eigen dari operator evolusi waktu, yang disusun dengan menggunakan metode pemodelan Hamiltonian. Setelah QPE, pengukuran komputer kuantum memberikan energi keadaan dasar dengan probabilitasjadi penting untuk menyiapkan status tebakan dengan bukan nol tumpang tindih dengan fungsi gelombang sebenarnya. (b) Sebuah algoritma simulasi kuantum variasional dalam komputer kuantum jangka pendek. Algoritme ini menggabungkan prosesor kuantum dengan rutinitas pengoptimalan klasik untuk melakukan beberapa pengoperasian singkat yang cukup cepat untuk menghindari kesalahan. Komputer kuantum mempersiapkan keadaan menebak-nebakdengan rantai ansatz kuantum tergantung pada beberapa parameter... Istilah individu Hamiltonian diukur satu per satu (atau dalam kelompok komuter menggunakan strategi yang lebih maju), memberikan perkiraan energi yang diharapkan untuk vektor parameter tertentu. Kemudian parameter dioptimalkan dengan prosedur optimasi klasik hingga konvergensi. Pendekatan variasional telah diperluas ke banyak masalah algoritmik selain simulasi kuantum.
Komputer kuantum yang dapat mensimulasikan sistem kimia besar harus toleran terhadap kesalahan agar dapat menjalankan algoritme yang dalam secara sewenang-wenang tanpa kesalahan. Komputer kuantum semacam itu mampu mensimulasikan sistem kimia dengan memetakan perilaku elektronnya ke perilaku qubit dan gerbang kuantumnya. Proses pemodelan kuantum secara konseptual sangat sederhana dan digambarkan pada Gambar 2 (a). Kami akan menyiapkan register qubit yang dapat menyimpan fungsi gelombang dan mengimplementasikan evolusi kesatuan Hamiltonianmenggunakan metode pemodelan Hamiltonian, yang dibahas di bawah ini. Dengan elemen-elemen ini, subrutin kuantum yang dikenal sebagai estimasi fase kuantum dapat menemukan vektor eigen dan nilai eigen dari sistem. Yaitu, jika register qubit awalnya dalam keadaan | 0⟩, keadaan akhirnya adalah: Dengan kata lain, keadaan akhir adalah superposisi nilai eigen

dan vektor eigen sistem. Keadaan dasar kemudian diukur dengan probabilitas... Untuk memaksimalkan kemungkinan ini, keadaan dasar ditetapkan dengan keadaan yang mudah disiapkan tetapi juga keadaan termotivasi secara fisik yang diharapkan serupa dengan keadaan dasar yang sebenarnya. Contoh tipikal adalah keadaan Hartree-Fock, meskipun gagasan lain telah dieksplorasi untuk sistem yang berkorelasi kuat [lihat Ref. di sini ].
Ada dua cara umum untuk merepresentasikan elektron dalam sebuah molekul: berbasis grid dan metode orbital atau dasar (lihat McArdle dan rekan untuk rincian lengkapnya [di sini ]). Dalam metode himpunan basis, fungsi gelombang elektron direpresentasikan sebagai jumlah determinan Slater orbital elektron, yang dapat langsung dibandingkan dengan register qubit [di sini dandi sini ]. Ini membutuhkan pemilihan dasar dan perhitungan awal integral elektronik. Di sisi lain, dalam metode grid, masalah dirumuskan sebagai solusi untuk persamaan diferensial biasa dalam grid. Keuntungan dari pemodelan berbasis mesh adalah tidak diperlukan pendekatan Bourne-Oppenheimer atau set dasar. Namun, mereka tidak secara alami antisimetrik, yang disyaratkan oleh prinsip Pauli dari mekanika kuantum, jadi perlu untuk menyediakan antisimetri menggunakan prosedur penyortiran [di sini ]. Metode berbasis grid telah dibahas dalam konteks pemodelan dinamika kimia [lih. di sini ] dan menghitung konstanta laju termal [lihat. sini]. Terlepas dari perbedaannya, alur kerja pemodelan kuantum identik, seperti yang ditunjukkan pada Gambar 2.
Ada juga beberapa cara untuk membangun operator... Kami akan menyajikan teknik paling sederhana, Trotterization, juga dikenal sebagai formulasi produk [lihat hal. di sini ]; untuk gambaran lengkapnya lihat [di sini dan di sini ]. Trotterisasi didasarkan pada premis bahwa Hamiltonian molekuler dapat dipisahkan sebagai jumlah suku yang menjelaskan interaksi satu dan dua elektron. Jika demikian, maka operatornyadapat diimplementasikan dalam istilah operator yang sesuai untuk setiap istilah di Hamiltonian menggunakan rumus Trotter - Suzuki [di sini ]: Misalnya, dalam kuantisasi kedua, setiap istilah dalam ekspresi ini akan memiliki bentuk atau , di mana operator pemusnahan dan penciptaan, masing-masing. Konstruksi skema yang eksplisit dan terperinci yang mewakili istilah-istilah ini telah diberikan oleh Whitfield dan rekan-rekannya [lih. di sini ]. Setelah menghitung anggota
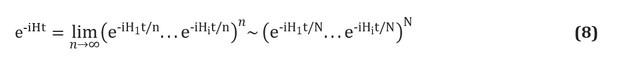

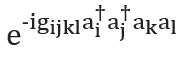
 dan dikenal sebagai integral elektronik, kuantitassepenuhnya ditentukan. Anda juga dapat menggunakan Trotter tingkat tinggi - rumus Suzuki untuk mengurangi kesalahan. Ada banyak teknik pemodelan Hamiltonian lainnya. Contoh teknik yang kuat dan canggih adalah kubitisasi [di sini ] dan pemrosesan sinyal kuantum [lihat Referensi. di sini ], yang terbukti memiliki penskalaan asimtotik optimal, meskipun tidak jelas apakah hal ini akan menghasilkan aplikasi praktis yang lebih baik.
dan dikenal sebagai integral elektronik, kuantitassepenuhnya ditentukan. Anda juga dapat menggunakan Trotter tingkat tinggi - rumus Suzuki untuk mengurangi kesalahan. Ada banyak teknik pemodelan Hamiltonian lainnya. Contoh teknik yang kuat dan canggih adalah kubitisasi [di sini ] dan pemrosesan sinyal kuantum [lihat Referensi. di sini ], yang terbukti memiliki penskalaan asimtotik optimal, meskipun tidak jelas apakah hal ini akan menghasilkan aplikasi praktis yang lebih baik.
4. Masalah pengoptimalan
Banyak masalah dalam biologi komputasi dan disiplin ilmu lain dapat dirumuskan sebagai menemukan minimum atau maksimum global dari fungsi multidimensi yang kompleks. Sebagai contoh, diyakini bahwa struktur asli suatu protein adalah minimum global dari permukaan hiper energi bebasnya [lihat. di sini ]. Di area lain, mengidentifikasi kelompok dalam jaringan protein yang berinteraksi atau objek biologis sama dengan menemukan subset optimal dari node [lihat. sini]. Sayangnya, dengan pengecualian beberapa sistem sederhana, masalah pengoptimalan seringkali sangat kompleks. Meskipun ada heuristik untuk mencari solusi perkiraan, mereka biasanya hanya memberikan minimum lokal, dan dalam banyak kasus bahkan heuristik tidak dapat diputuskan. Kemampuan komputer kuantum untuk mempercepat solusi untuk masalah pengoptimalan seperti itu atau untuk menemukan solusi yang lebih baik telah diteliti secara mendetail.
Topik pengoptimalan di komputer kuantum rumit karena sering kali tidak jelas apakah komputer kuantum dapat memberikan segala jenis percepatan. Di bagian ini, kami akan memberikan gambaran umum dari beberapa ide optimasi kuantum. Namun, jaminan peningkatan tidak begitu jelas jika dibandingkan dengan, misalnya, simulasi kuantum, yang diharapkan bermanfaat dalam jangka panjang.
4.1. Pengoptimalan dalam prosesor kuantum
Optimasi kuantum adiabatik adalah salah satu pendekatan optimasi paling populer karena kehadiran mesin D-Wave [lihat. di sini ] yang awalnya menerapkan pendekatan ini. Komputasi kuantum adiabatik [di sini ] didasarkan pada teorema adiabatik dari mekanika kuantum [lih. sini]. Menurut teorema ini, jika sebuah sistem disiapkan dalam keadaan dasar Hamiltonian, dan Hamiltonian ini berubah agak lambat, sistem akan selalu tetap dalam keadaan dasar seketika. Ini dapat digunakan untuk melakukan komputasi dengan mengkodekan masalah (seperti fungsi penilaian yang kami harap dapat diminimalkan) sebagai Hamiltonian, dan secara bertahap berkembang menuju Hamiltonian ini dari beberapa sistem asli yang dapat dipersiapkan dengan mudah dalam keadaan dasarnya. Secara umum, evolusi adiabatik diungkapkan sebagai berikut: Di sini

dan - berfungsi seperti itu dan untuk waktu tertentu T. Misalnya, kita dapat mempertimbangkan program anil linier dengan dan ... Banyak makalah telah dikhususkan untuk membahas waktu eksekusi algoritma adiabatik, tetapi heuristik umumnya adalah bahwa waktu eksekusi secara maksimal sebanding dengan kuadrat terbalik dari celah spektral minimum (perbedaan energi terkecil antara tanah dan keadaan tereksitasi pertama) selama evolusi adiabatik... Dipercaya bahwa komputasi kuantum adiabatik (dan komputasi kuantum secara umum) tidak dapat secara efektif menyelesaikan kelas masalah NP-complete, atau setidaknya tidak ada dari metode ini yang telah diuji secara ketat [lihat Referensi. di sini ].
Pada prinsipnya, komputasi kuantum adiabatik setara dengan komputasi kuantum universal [lih. di sini ]. Universalitas ini terjadi hanya jika evolusi memungkinkan non-stochasticity, yang berarti Hamiltonian memiliki elemen off-diagonal non-negatif di beberapa titik dalam evolusi. Implementasi eksperimental paling populer dari komputasi kuantum adiabatik, dikomersialkan oleh D-Wave Systems Inc., menggunakan Stochastic Hamiltonians dan oleh karena itu tidak universal. Ada beberapa kekhawatiran dalam literatur profesional bahwa variasi komputasi kuantum ini mungkin disimulasikan secara klasik [di sini ], yang berarti percepatan eksponensial mungkin tidak dapat dilakukan. Terlepas dari kekhawatiran ini, teknik ini telah banyak digunakan sebagai teknik optimasi metaheuristik dan baru-baru ini telah terbukti mengungguli simulasi anil [lihat Referensi. di sini ].
Optimasi kuantum telah dipelajari di luar model adiabatik. Algoritma optimasi perkiraan kuantum e (QAOA) [lih. disini , disini dan disini] Adalah algoritme pengoptimalan variasional dalam komputer kuantum yang telah membangkitkan minat yang cukup besar dalam literatur. Ada beberapa implementasi eksperimental QAOA dalam prosesor kuantum, misalnya [lihat. di sini ] Gambar 3. GAMBAR 3. (a) Simulasi komputer kuantum adiabatik menerapkan masalah pelipatan protein yang disederhanakan dijelaskan [di sini ]. Warna mengkodekan probabilitas logaritmik desimal dari string biner tertentu. Di akhir perhitungan, dua solusi energi terendah memiliki probabilitas pengukuran mendekati 0,5. Evolusi tidak pernah sepenuhnya adiabatik dalam waktu yang terbatas, dan string biner lainnya memiliki probabilitas pengukuran yang tersisa. (b)

Deskripsi proses adiabatik komputasi kuantum .... Potensi yang mendorong qubit berubah perlahan, menyebabkannya berputar. Perhatikan bahwa representasi bola Bloch tidak lengkap karena tidak menampilkan korelasi antara qubit berbeda yang diperlukan untuk keuntungan kuantum. Pada akhir evolusi, sistem qubit berada dalam keadaan klasik (atau superposisi keadaan klasik), mewakili solusi dengan energi terendah. (c) Tingkat energi selama evolusi kuantum adiabatik. Jumlah waktu yang dibutuhkan untuk memastikan evolusi kuasi-adiabatik ditentukan oleh perbedaan energi minimum antar level, yang ditunjukkan dengan garis putus-putus
4.2. Prediksi struktur protein
Prediksi struktur protein tanpa matriks tetap menjadi masalah utama yang belum terpecahkan dalam biologi komputasi. Solusi untuk masalah ini akan diterapkan secara luas dalam rekayasa molekuler dan desain obat. Menurut hipotesis pelipatan protein, struktur asli protein dianggap sebagai energi bebas minimum global [lihat. di sini ], meskipun ada banyak contoh yang berlawanan. Mengingat ruang konformasi luas yang tersedia bahkan untuk peptida kecil, simulasi klasik yang lengkap tidak dapat diselesaikan. Namun, banyak yang bertanya-tanya apakah komputasi kuantum dapat membantu memecahkan masalah ini.
Literatur komputasi kuantum berfokus pada model kisi protein, di mana peptida dimodelkan sebagai struktur kisi yang bergerak sendiri, meskipun beberapa model lain juga baru-baru ini mulai diterapkan dalam praktik komputasi [lih. di sini ]. Setiap situs kisi berhubungan dengan residu, dan interaksi antara situs tetangga spasial berkontribusi pada fungsi energi. Ada beberapa skema kontak energi, tetapi hanya dua yang telah digunakan dalam aplikasi kuantum: model kutub-hidrofobik [lihat. di sini ], yang hanya mempertimbangkan dua kelas asam amino, dan model Miyazawa-Jernigan [lih. sini], yang berisi interaksi untuk setiap pasang residu. Sementara model ini adalah penyederhanaan yang nyata, mereka telah memberikan wawasan substansial tentang pelipatan protein [lihat Referensi. di sini ] dan telah diusulkan sebagai alat mentah untuk mempelajari ruang konformasi sebelum perbaikan rinci lebih lanjut [lihat. di sini dan di sini ].
Hampir semua pekerjaan berfokus pada komputasi kuantum adiabatik, karena peptida model pun memerlukan sejumlah besar qubit, dan mesin kuantum D-Wave adalah perangkat kuantum terbesar yang tersedia saat ini.
Namun demikian, dalam artikel yang baru-baru ini diterbitkan oleh Fingerhat dan rekan [lihat sini] sebuah upaya telah dilakukan untuk menjelaskan penggunaan algoritma QAOA. Kedua metode memiliki karakteristik yang sama jika masalah kisi protein dikodekan sebagai operator Hamilton. Metode ini pertama kali dipertimbangkan oleh Perdomo [lihat. di sini ], yang disarankan menggunakan register qubituntuk menyandikan koordinat Cartesian asam amino N pada kisi kubik berdimensi-D dengan sisi N. Fungsi energi dinyatakan dalam Hamiltonian yang mengandung istilah untuk menghargai kontak dengan protein: pertahankan struktur Primer dan hindari kecocokan asam amino. Tak lama setelah artikel penting ini, artikel lain muncul membahas konstruksi model yang lebih efisien untuk kisi dua dimensi [lihat. di sini ].
Pengodean ini diuji pada perangkat keras sebenarnya pada tahun 2012 ketika Perdomo dan rekan [lihat. sini] menghitung konformasi energi terendah dari peptida PSVKMA pada mesin kuantum D-Wave. Baru-baru ini, tim peneliti Babay memperpanjang rotasi dan pengkodean berlian untuk model 3D dan memperkenalkan peningkatan algoritmik yang mengurangi kompleksitas dan kecepatan pergerakan pengkodean Hamilton [lihat Referensi. di sini ]. Mereka menggunakan prosesor D-Wave 2000Q untuk menentukan keadaan dasar Higoline (10 residu) pada kisi persegi dan triptofan (8 residu) pada kisi kubik, yang merupakan peptida terbesar yang diselidiki hingga saat ini. Implementasi eksperimental ini menggunakan metode di mana sebagian peptida diperbaiki. Hal ini memungkinkan masalah besar dimasukkan ke dalam komputer kuantum karena kemungkinan penelitianjumlah parameter masalah yang dipelajari.
Menemukan konformasi energi terendah dalam model kisi adalah masalah NP yang sulit [lih. di sini dan di sini ], yang berarti bahwa di bawah hipotesis standar tidak ada algoritma klasik untuk pemecahannya. Selain itu, saat ini diyakini bahwa komputer kuantum tidak dapat menawarkan percepatan eksponensial untuk masalah NP-complete dan lebih kompleks [lih. di sini ], meskipun mereka mungkin menawarkan manfaat peningkatan yang dikenal dalam literatur sebagai "percepatan kuantum terbatas" [lih. sini]. Baru-baru ini, kelompok penelitian Outerel menerapkan simulasi numerik untuk menyelidiki fakta ini, menyimpulkan bahwa ada bukti percepatan kuantum terbatas, meskipun hasil ini mungkin memerlukan mesin adiabatik yang menggunakan koreksi kesalahan atau simulasi kuantum dalam mesin tujuan umum yang toleran terhadap kesalahan [lih. di sini ].
Meskipun sebagian besar literatur telah berfokus pada model kisi protein, artikel terbaru [di sini ] mencoba menggunakan anil kuantum untuk sampel rotamer dalam fungsi energi Rosetta [lihat Ref. di sini ]. Penulis menggunakan prosesor D-Wave 2000Quntuk menemukan penskalaan yang tampak hampir konstan dibandingkan dengan anil simulasi klasik. Pendekatan yang sangat mirip disajikan oleh kelompok Marchand [lihat. di sini ] untuk pilihan konformer.
kesimpulan
Komputer kuantum dapat menyimpan dan memanipulasi sejumlah besar informasi, dan menjalankan algoritme dengan kecepatan yang jauh lebih cepat daripada teknologi komputasi klasik mana pun. Potensi komputer kuantum yang kecil sekalipun dapat dengan aman melampaui superkomputer terbaik yang ada saat ini, yang pada akhirnya dapat memiliki dampak transformatif pada biologi komputasi dalam tugas-tugas tertentu, menjanjikan untuk memindahkan masalah dari yang tidak dapat diselesaikan menjadi yang sulit dan kompleks menjadi rutin. Prosesor kuantum pertama yang dapat memecahkan masalah berguna diharapkan muncul dalam dekade berikutnya. Oleh karena itu, memahami apa yang dapat dan tidak dapat dilakukan oleh komputer kuantum adalah prioritas bagi setiap ilmuwan komputasi.
Meskipun kita baru saja memasuki era komputasi kuantum praktis, kita sudah dapat melihat kontur biologi komputasi kuantum baru selama beberapa dekade mendatang. Kami berharap ulasan ini akan membangkitkan minat di antara ahli biologi komputasi untuk teknologi yang dapat segera mengubah bidang eksperimen dan penelitian mereka. Dan spesialis dalam komputasi kuantum, pada gilirannya, akan dapat membantu ahli biologi secara signifikan mengembangkan tingkat biologi komputasi dan bioinformatika, dari mana banyak hasil yang signifikan diharapkan untuk seluruh umat manusia.