Bagian 2
Bagian 3
Di artikel ini, Anda akan mempelajari:
- Apa itu pembelajaran transfer dan bagaimana cara kerjanya
- Apa itu semantik / contoh segmentasi dan cara kerjanya
- Tentang apa itu deteksi objek dan cara kerjanya
pengantar
Untuk tugas deteksi objek, dua metode dibedakan (lihat sumber dan detail selengkapnya di sini ):
- Dua metode -tahap, mereka juga "metode berdasarkan wilayah" (eng metode berbasis Region.) - suatu pendekatan dibagi menjadi dua tahap. Pada tahap pertama, wilayah minat (RoI) dipilih dengan penelusuran selektif atau menggunakan lapisan khusus jaringan neural - wilayah dengan probabilitas tinggi berisi objek di dalamnya. Pada tahap kedua, wilayah yang dipilih dipertimbangkan oleh pengklasifikasi untuk menentukan milik kelas asli dan regressor, yang menentukan lokasi kotak pembatas.
- Metode satu tahap (metode satu tahap Engl.) - pendekatan, tidak menggunakan algoritma terpisah untuk menghasilkan wilayah, tetapi memprediksi koordinat sejumlah kotak pembatas dengan karakteristik berbeda, seperti hasil klasifikasi dan tingkat kepercayaan, dan selanjutnya menyesuaikan kerangka lokasi.
Artikel ini membahas metode satu langkah.
Transfer pembelajaran
Pembelajaran transfer adalah metode untuk melatih jaringan saraf, di mana kami mengambil model yang sudah dilatih pada beberapa data untuk pelatihan tambahan lebih lanjut untuk memecahkan masalah lain. Misalnya, kami memiliki model EfficientNet-B5 yang dilatih pada set data ImageNet (1000 kelas). Sekarang, dalam kasus yang paling sederhana, kita mengubah classifier-layer terakhirnya (katakanlah, untuk mengklasifikasikan objek dari 10 kelas).
Perhatikan gambar di bawah ini:
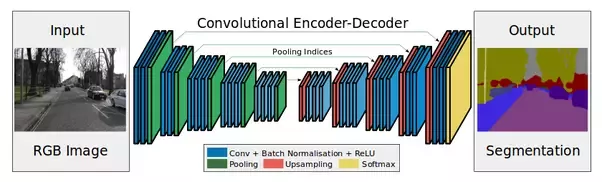
Encoder adalah lapisan subsampling (konvolusi dan pool).
Mengganti lapisan terakhir dalam kode terlihat seperti ini (framework - pytorch, environment - google colab):
Muat model EfficientNet-b5 yang terlatih dan lihat layer-classifiernya:

Ubah lapisan ini ke yang lain:
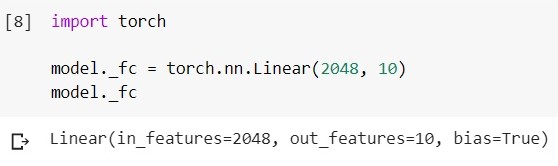
Dekoder diperlukan, khususnya, dalam tugas segmentasi (tentang ini Lebih lanjut).
Mentransfer strategi pembelajaran
Harus ditambahkan bahwa secara default semua lapisan model yang ingin kita latih lebih lanjut dapat dilatih. Kita bisa "membekukan" bobot beberapa lapisan.
Untuk membekukan semua lapisan:

Semakin sedikit lapisan yang kita latih, semakin sedikit sumber daya komputasi yang kita butuhkan untuk melatih model. Apakah teknik ini selalu dibenarkan?
Bergantung pada jumlah data yang ingin kita latih jaringan, dan pada data yang melatih jaringan, ada 4 opsi untuk pengembangan peristiwa untuk pemelajaran transfer (di bawah "sedikit" dan "banyak" Anda dapat menggunakan nilai bersyarat 10k):
- Anda memiliki sedikit data , dan ini mirip dengan data yang melatih jaringan sebelumnya. Anda dapat mencoba melatih hanya beberapa lapisan terakhir.
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
Segmentasi semantik adalah ketika kita memberi makan gambar sebagai masukan, dan pada keluaran kita ingin mendapatkan sesuatu seperti: Secara

lebih formal, kita ingin mengklasifikasikan setiap piksel dari gambar masukan kita - untuk memahami kelas mana yang memilikinya.
Ada banyak pendekatan dan nuansa di sini. Apa hanya arsitektur jaringan ResNeSt-269 :)
Intuisi - pada input gambar (h, w, c), pada output kita ingin mendapatkan mask (h, w) atau (h, w, c), di mana c adalah jumlah kelas (tergantung pada data dan model). Sekarang mari tambahkan decoder setelah encoder kita dan latih mereka.
Dekoder akan terdiri, khususnya, lapisan upsampling. Anda dapat meningkatkan dimensi hanya dengan "merentangkan" tinggi dan lebar peta fitur kami dengan satu langkah atau lainnya. Saat menarik, Anda bisa menggunakaninterpolasi bilinear (dalam kode itu hanya akan menjadi salah satu parameter metode).
Arsitektur jaringan Deeplabv3 +:
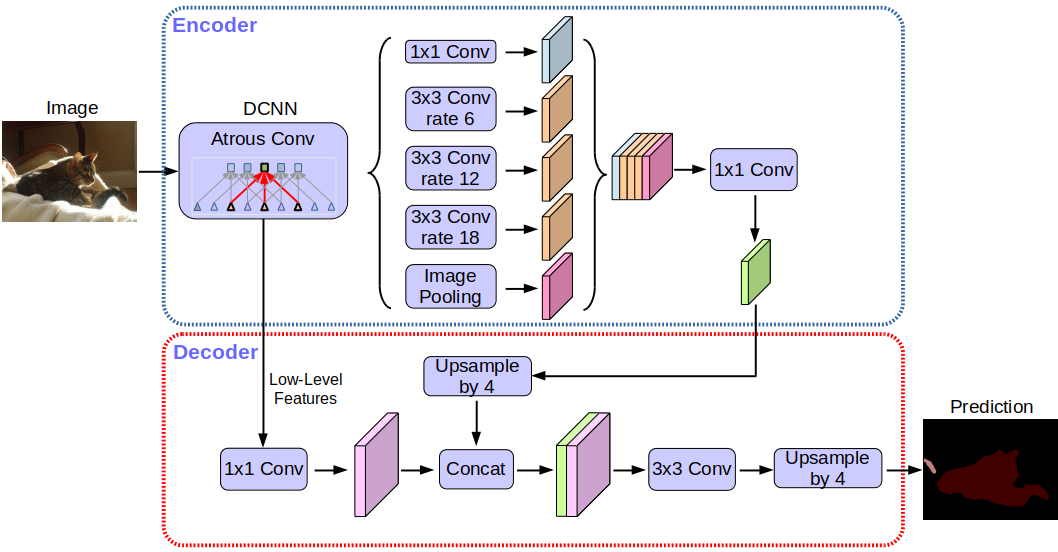
Tanpa membahas detailnya, Anda akan melihat bahwa jaringan menggunakan arsitektur encoder-decoder.
Versi yang lebih klasik, arsitektur jaringan U-net:
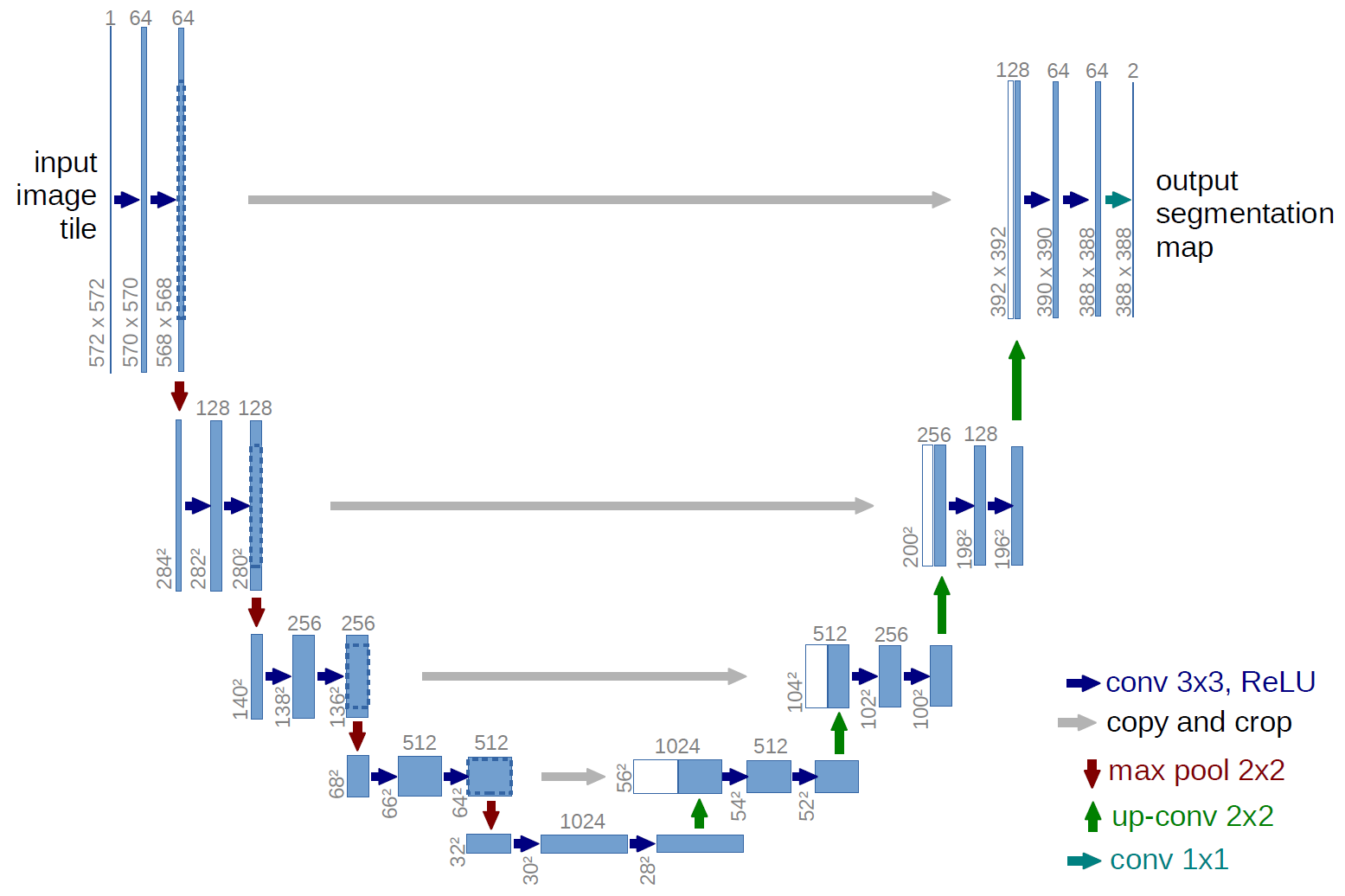
Apa panah abu-abu ini? Inilah yang disebut koneksi lewati. Intinya adalah encoder "menyandikan" lossy gambar masukan kita. Untuk meminimalkan kerugian tersebut, mereka menggunakan koneksi lewati.
Dalam tugas ini, kita dapat menggunakan pembelajaran transfer - misalnya, kita dapat mengambil jaringan dengan pembuat enkode yang sudah terlatih, menambahkan dekoder, dan melatihnya.
Tentang data apa dan model apa yang berkinerja terbaik dalam tugas ini saat ini - Anda dapat melihat di sini...
Segmentasi instance
Versi yang lebih kompleks dari masalah segmentasi. Intinya adalah kita ingin tidak hanya mengklasifikasikan setiap piksel dari gambar masukan, tetapi juga entah bagaimana memilih objek yang berbeda dari kelas yang sama:
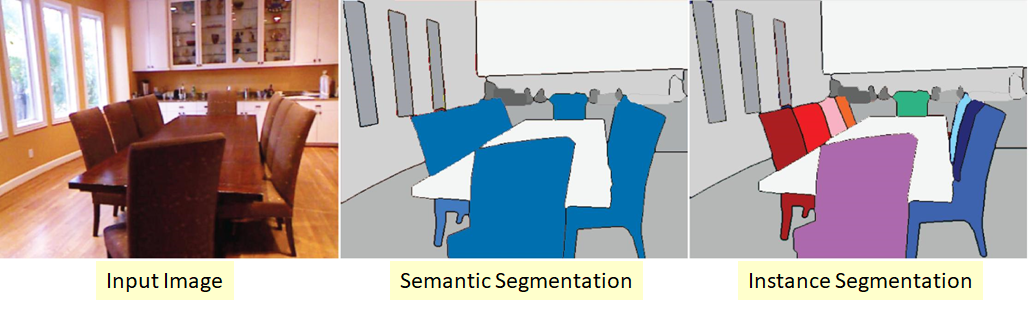
Kebetulan kelas-kelas itu "lengket" atau tidak ada batas yang terlihat di antara mereka, tetapi kita ingin membatasi objek dari kelas yang sama selain.
Ada juga beberapa pendekatan di sini. Yang paling sederhana dan intuitif adalah kami melatih dua jaringan yang berbeda. Kami mengajarkan yang pertama untuk mengklasifikasikan piksel untuk beberapa kelas (segmentasi semantik), dan yang kedua untuk mengklasifikasikan piksel di antara objek kelas. Kami mendapatkan dua topeng. Sekarang kita dapat mengurangi yang kedua dari yang pertama dan mendapatkan yang kita inginkan :)
Pada data apa dan model mana yang berkinerja terbaik dalam tugas ini saat ini - Anda dapat melihat di sini...
Object detection
Kami mengirim gambar ke input, dan pada output kami ingin melihat sesuatu seperti ini:

Hal paling intuitif yang dapat dilakukan adalah "menjalankan" gambar dengan persegi panjang yang berbeda dan, menggunakan pengklasifikasi yang sudah terlatih, tentukan apakah ada objek yang menarik bagi kami di area ini. Ada skema seperti itu, tapi jelas bukan yang terbaik. Bagaimanapun, kita memiliki lapisan konvolusional yang entah bagaimana menafsirkan peta fitur "sebelum" (A) dalam peta fitur "setelah" (B). Dalam hal ini, kita tahu dimensi convolution filter => kita tahu piksel mana dari A ke piksel B mana yang dikonversi.
Mari kita lihat YOLO v3:
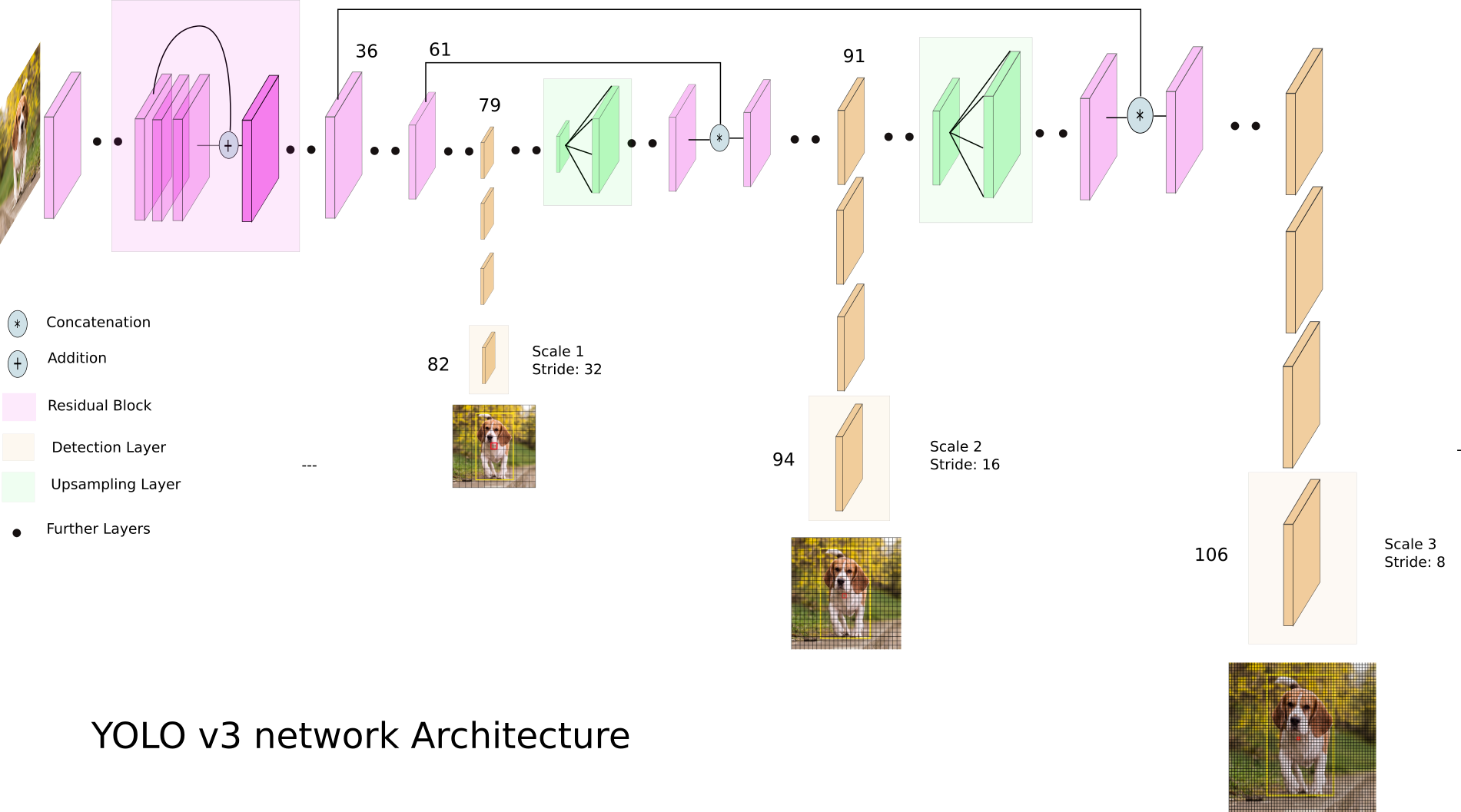
YOLO v3 menggunakan peta fitur dimensi yang berbeda. Ini dilakukan, khususnya, untuk mendeteksi objek dengan ukuran berbeda dengan benar.
Selanjutnya, ketiga skala tersebut digabungkan:
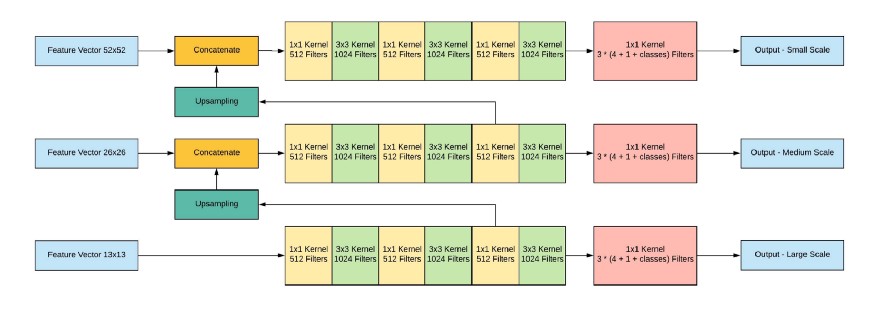
Output jaringan, dengan gambar input 416x416, 13x13x (B * (5 + C)), di mana C adalah jumlah kelas, B adalah jumlah kotak untuk setiap wilayah (YOLO v3 memiliki 3 di antaranya). 5 - ini adalah parameter seperti: Px, Py - koordinat pusat benda, Ph, Pw - tinggi dan lebar benda, Pobj - probabilitas benda berada di wilayah ini.
Mari kita lihat gambarnya, sehingga akan sedikit lebih jelas:

YOLO memfilter data prediksi awalnya dengan skor objektivitas dengan beberapa nilai (biasanya 0,5-0,6), dan kemudian dengan penekanan non-maksimum .
Tentang data dan model apa yang berkinerja terbaik dalam tugas ini saat ini - Anda dapat melihat di sini .
Kesimpulan
Ada banyak model dan pendekatan berbeda untuk tugas segmentasi dan lokalisasi objek hari ini. Ada ide-ide tertentu yang, setelah dipahami, akan memudahkan pembongkaran model dan pendekatan kebun binatang itu. Saya mencoba mengungkapkan ide-ide ini dalam artikel ini.
Di artikel berikutnya, kita akan berbicara tentang transfer gaya dan GAN.