
Dalam artikel ini, kita akan membahas tentang detail implementasi dan pengoperasian berbagai kompiler JIT, serta strategi pengoptimalan. Kami akan membahas dengan cukup detail, tetapi kami akan menghilangkan banyak konsep penting. Artinya, tidak akan ada cukup informasi dalam artikel ini untuk mencapai kesimpulan yang masuk akal dalam perbandingan implementasi dan bahasa apa pun.
Untuk mendapatkan pemahaman dasar tentang kompiler JIT, baca artikel ini .
Catatan kecil:
, , , - . , JIT ( ), , . , , , , . - , , .
- Pypy
- GraalVM C
- OSR
- JIT
()
LuaJIT menggunakan apa yang disebut penelusuran. Pypy melakukan metatracing, yaitu menggunakan sistem untuk menghasilkan penjejakan dan interpreter JIT. Pypy dan LuaJIT bukanlah contoh implementasi Python dan Lua, tetapi proyek yang berdiri sendiri. Saya akan mencirikan LuaJIT sebagai sangat cepat, dan itu menggambarkan dirinya sebagai salah satu implementasi bahasa dinamis tercepat - dan saya benar-benar percaya itu.
Untuk memahami kapan harus memulai penelusuran, loop interpreter mencari hot loop (konsep kode panas bersifat universal untuk semua kompiler JIT!). Compiler kemudian "melacak" loop, merekam operasi yang dapat dijalankan untuk mengompilasi kode mesin yang dioptimalkan dengan baik. Dalam LuaJIT, kompilasi didasarkan pada jejak dengan representasi perantara seperti instruksi yang unik untuk LuaJIT.
Bagaimana pelacakan diterapkan di Pypy
Pypy mulai melacak fungsi setelah 1619 eksekusi dan mengkompilasi setelah 1039 eksekusi, artinya, dibutuhkan sekitar 3000 eksekusi fungsi untuk mulai berjalan lebih cepat. Nilai-nilai ini dipilih dengan cermat oleh tim Pypy, dan secara umum di dunia penyusun, banyak konstanta yang dipilih dengan cermat.
Bahasa dinamis mempersulit pengoptimalan. Kode di bawah ini dapat dihapus secara statis dalam bahasa yang lebih ketat karena
Falseakan selalu salah. Namun, di Python 2, ini tidak dapat dijamin hingga waktu proses.
if False:
print("FALSE")
Untuk program cerdas apa pun, kondisi ini akan selalu salah. Sayangnya, nilainya
Falsedapat didefinisikan ulang, dan ekspresi tersebut akan berada dalam lingkaran, dapat didefinisikan ulang di tempat lain. Karenanya Pypy bisa membuat "penjaga". Jika pembela HAM gagal, JIT kembali ke loop interpretasi. Pypy kemudian menggunakan konstanta lain (200) yang disebut keinginan jejak untuk memutuskan apakah akan mengompilasi sisa jalur baru sebelum akhir loop. Jalur bawah ini disebut jembatan .
Selain itu, Pypy menyediakan konstanta ini sebagai argumen yang dapat Anda sesuaikan saat runtime bersama dengan konfigurasi unrolling, yaitu ekspansi loop, dan inline! Dan sebagai tambahan, ini menyediakan pengait yang dapat kita lihat setelah kompilasi selesai.
def print_compiler_info(i):
print(i.type)
pypyjit.set_compile_hook(print_compiler_info)
for i in range(10000):
if False:
pass
print(pypyjit.get_stats_snapshot().counters)
Di atas, saya menulis program Python murni dengan hook kompilasi untuk menampilkan jenis kompilasi yang diterapkan. Kode tersebut juga menampilkan data di bagian akhir yang menunjukkan jumlah pembela. Untuk program ini, saya mendapat satu kompilasi loop dan 66 pembela. Ketika saya mengganti ekspresi dengan
ifoperan out-of-loop sederhana for, hanya ada 59 pemain bertahan yang tersisa.
for i in range(10000):
pass # removing the `if False` saved 7 guards!
Dengan menambahkan dua baris ini ke loop
for, saya mendapat dua kompilasi, salah satunya adalah dari tipe "jembatan"!
if random.randint(1, 100) < 20:
False = True
Tunggu, Anda berbicara tentang metatracing!
Ide di balik metatracing dapat dijelaskan sebagai "tulis juru bahasa dan dapatkan kompiler gratis!" Atau "ubah interpreter Anda menjadi kompilator JIT!" Menulis kompiler itu sulit, dan jika Anda bisa mendapatkannya secara gratis, maka idenya keren. Pypy "berisi" interpreter dan kompilator, tetapi tidak secara eksplisit mengimplementasikan kompilator tradisional.
Pypy memiliki alat RPython (dibuat untuk Pypy). Ini adalah kerangka kerja untuk menulis penerjemah. Bahasanya adalah sejenis Python dan diketik secara statis. Dalam bahasa inilah Anda perlu menulis seorang juru bahasa. Bahasa ini tidak dirancang untuk pemrograman Python yang diketik karena tidak berisi pustaka atau paket standar. Program RPython apa pun adalah program Python yang valid. Kode RPython ditranspilasi ke C dan kemudian dikompilasi. Jadi, meta-compiler dalam bahasa ini ada sebagai program C yang dikompilasi.
Awalan "meta" dalam kata metatraces berarti pelacakan dilakukan saat penerjemah dijalankan, bukan programnya. Ini berperilaku kurang lebih seperti interpreter lainnya, tetapi dapat melacak operasinya dan dirancang untuk mengoptimalkan jejak dengan memperbarui jalurnya. Dengan penelusuran lebih lanjut, jalur interpreter menjadi lebih dioptimalkan. Penerjemah yang dioptimalkan dengan baik mengikuti jalur tertentu. Dan kode mesin yang digunakan di jalur ini, yang diperoleh dengan menyusun RPython, dapat digunakan dalam kompilasi akhir.
Singkatnya, "compiler" di Pypy mengkompilasi interpreter Anda, itulah sebabnya Pypy terkadang disebut meta-compiler. Itu tidak mengkompilasi begitu banyak program yang Anda jalankan sebagai jalur interpreter yang dioptimalkan.
Konsep metatracing mungkin tampak membingungkan, jadi untuk tujuan ilustrasi saya menulis program yang sangat buruk yang hanya memahami
a = 0dan a++to.
# interpreter written with RPython
for line in code:
if line == "a = 0":
alloc(a, 0)
elif line == "a++":
guard(a, "is_int") # notice how in Python, the type is unknown, but after being interpreted by RPython, the type is known
guard(a, "> 0")
int_add(a, 1)
Jika saya menjalankan siklus panas ini:
a = 0
a++
a++
Treknya mungkin terlihat seperti ini:
# Trace from numerous logs of the hot loop
a = alloc(0) # guards can go away
a = int_add(a, 1)
a = int_add(a, 2)
# optimize trace to be compiled
a = alloc(2) # the section of code that executes this trace _is_ the compiled code
Tetapi kompilator bukanlah modul khusus yang terpisah, ia dibangun ke dalam interpreter. Oleh karena itu, siklus interpretasi akan terlihat seperti ini:
for line in code:
if traces.is_compiled(line):
run_compiled(traces.compiled(line))
continue
elif traces.is_optimized(line):
compile(traces.optimized(line))
continue
elif line == "a = 0"
# ....
Pengantar JVM
Saya menghabiskan empat bulan menulis dalam bahasa TruffleRuby berbasis Graal dan jatuh cinta dengannya.
Hotspot (dinamai demikian karena mencari hotspot ) adalah mesin virtual yang dilengkapi dengan instalasi Java standar. Ini berisi beberapa kompiler untuk mengimplementasikan kompilasi bertingkat. Basis kode 250.000 baris Hotspot terbuka dan memiliki tiga pengumpul sampah. Dev mengatasi kompilasi JIT, dalam beberapa tolok ukur, ini bekerja lebih baik daripada impls C ++ (pada kesempatan ini sebagai
Strategi yang digunakan di Hotspot telah menginspirasi banyak penulis kompiler JIT berikutnya, kerangka mesin virtual bahasa, dan terutama mesin Javascript. Hotspot juga melahirkan gelombang bahasa JVM seperti Scala, Kotlin, JRuby, dan Jython. JRuby dan Jython adalah implementasi Ruby dan Python menyenangkan yang mengkompilasi kode sumber ke bytecode JVM, yang kemudian dijalankan oleh Hotspot. Semua proyek ini relatif berhasil dalam mempercepat bahasa Python dan Ruby (Ruby lebih dari Python) tanpa menerapkan semua perkakas, seperti halnya dengan Pypy. Hotspot juga unik karena merupakan JIT untuk bahasa yang kurang dinamis (meskipun secara teknis merupakan JIT untuk bytecode JVM, bukan Java).

GraalVM adalah JavaVM dengan potongan kode Java. Itu dapat menjalankan bahasa JVM apa pun (Java, Scala, Kotlin, dll.). Ini juga mendukung Gambar Asli untuk bekerja dengan kode yang dikompilasi AOT melalui VM Substrat. Sebagian besar layanan Scala Twitter berjalan di Graal, yang berbicara tentang kualitas mesin virtual, dan dalam beberapa hal lebih baik daripada JVM, meskipun dibuat di Java.
Dan itu belum semuanya! GraalVM juga menyediakan Truffle: kerangka kerja untuk mengimplementasikan bahasa dengan membuat interpreter AST (Abstract Syntax Tree). Tidak ada langkah eksplisit di Truffle saat bytecode JVM dibuat seperti dalam bahasa JVM biasa. Sebaliknya, Truffle hanya akan menggunakan penerjemah dan berbicara dengan Graal untuk menghasilkan kode mesin secara langsung dengan pembuatan profil dan yang disebut penilaian parsial. Evaluasi parsial berada di luar cakupan artikel ini, singkatnya: metode ini mengikuti "tulis seorang juru bahasa, dapatkan kompiler gratis!" Filsafat metatracking, tetapi pendekatannya berbeda.
TruffleJS — Truffle- Javascript, V8 , , V8 , Google , . TruffleJS «» V8 ( JS-) , Graal.
JIT-
C
Implementasi JIT sering memiliki masalah dalam mendukung ekstensi C. Penerjemah standar seperti Lua, Python, Ruby, dan PHP memiliki C API yang memungkinkan pengguna membuat paket dalam bahasa tersebut, yang secara signifikan mempercepat eksekusi. Banyak paket yang ditulis dalam C, misalnya numpy, fungsi pustaka standar seperti
rand. Semua ekstensi C ini sangat penting untuk membuat bahasa yang ditafsirkan dengan cepat.
Ekstensi C sulit dipertahankan karena sejumlah alasan. Alasan paling jelas adalah bahwa API dirancang dengan mempertimbangkan penerapan internal. Selain itu, ekstensi C lebih mudah untuk mendukung ketika penerjemah ditulis dalam C, jadi JRuby tidak dapat mendukung ekstensi C, tetapi memiliki API untuk ekstensi Java. Pypy baru-baru ini merilis versi beta dari dukungan untuk ekstensi C, meskipun saya tidak yakin apakah itu berfungsi karena Hukum Hyrum . LuaJIT mendukung ekstensi C, termasuk fitur tambahan dalam ekstensi C-nya (LuaJIT luar biasa!)
Graal memecahkan masalah ini dengan Sulong, sebuah mesin yang menjalankan bytecode LLVM di GraalVM, mengubahnya menjadi Truffle. LLVM adalah kotak alat, dan kita hanya perlu tahu bahwa C dapat dikompilasi ke bytecode LLVM (Julia juga memiliki backend LLVM!). Ini aneh, tetapi solusinya adalah menggunakan bahasa yang dikompilasi dengan baik dengan sejarah lebih dari empat puluh tahun dan menafsirkannya! Tentu saja, ini tidak berjalan secepat C yang dikompilasi dengan benar, tetapi mendapatkan beberapa manfaat.
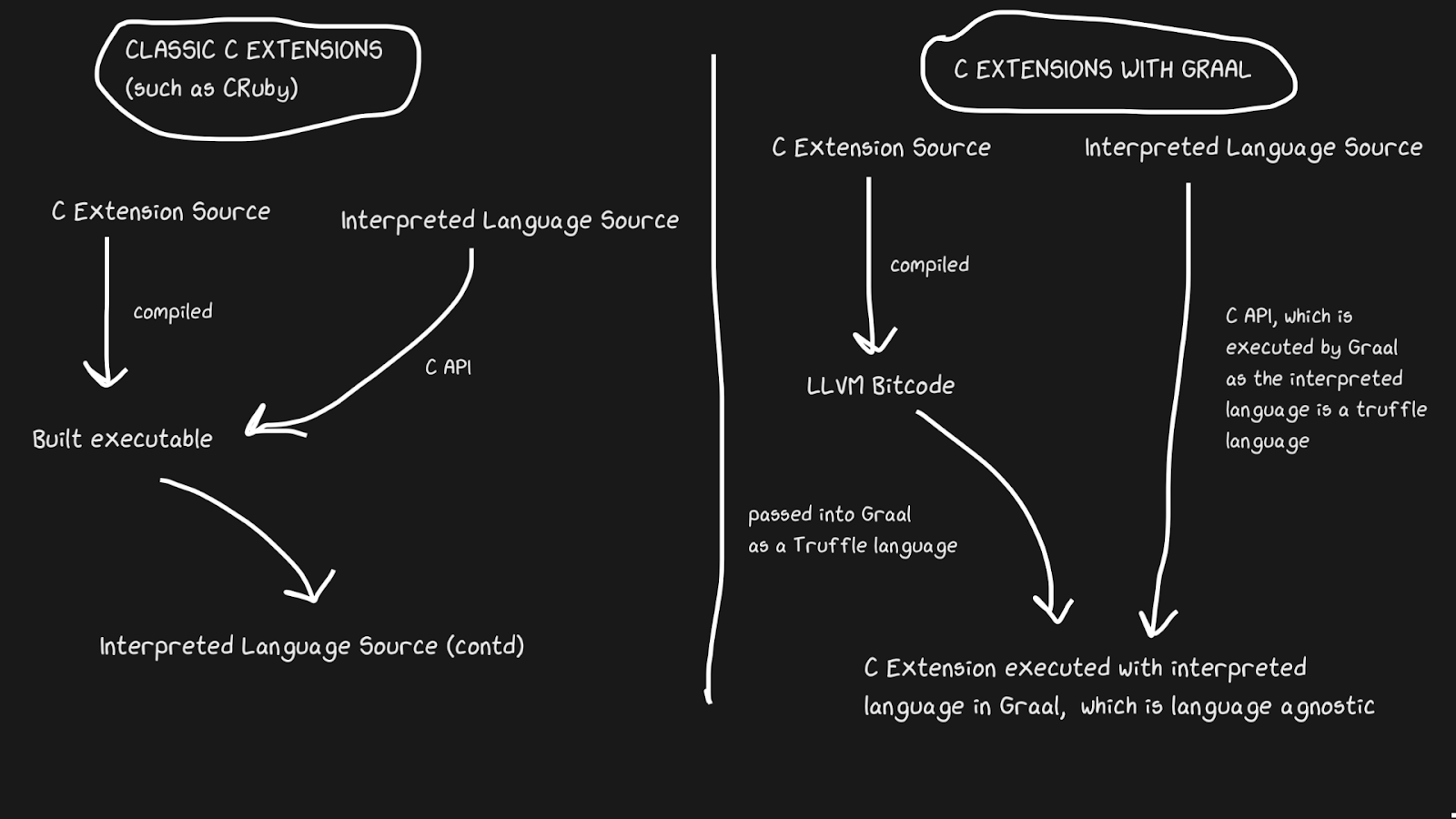
Bytecode LLVM sudah cukup rendah levelnya, yaitu tidak efisien untuk menerapkan JIT ke representasi perantara ini seperti pada C. Bagian dari biaya dikompensasi oleh fakta bahwa bytecode dapat dioptimalkan bersama dengan program Ruby lainnya, tetapi kami tidak dapat mengoptimalkan program C yang dikompilasi ... Semua strip memori ini, sebaris, strip kode mati, dan lainnya dapat diterapkan ke kode C dan Ruby, daripada memanggil biner C dari kode Ruby. Ekstensi TruffleRuby C lebih cepat daripada ekstensi CRuby C dalam beberapa hal.
Agar sistem ini berfungsi, Anda perlu tahu bahwa Truffle sepenuhnya tidak bergantung pada bahasa dan overhead peralihan antara C, Java, atau bahasa lain dalam Graal akan minimal.
Kemampuan Graal untuk bekerja dengan Sulong adalah bagian dari kemampuan poliglot mereka, yang memungkinkan pertukaran bahasa yang tinggi. Ini tidak hanya bagus untuk kompiler, tetapi juga membuktikan bahwa Anda dapat dengan mudah menggunakan banyak bahasa dalam satu "aplikasi".
Kembali ke kode yang ditafsirkan, ini lebih cepat
Kita tahu bahwa JIT berisi interpreter dan compiler, dan mereka berpindah dari interpreter ke compiler untuk mempercepat. Pypy membuat jembatan untuk jalur kembali, meskipun dari sudut pandang Graal dan Hotspot, ini adalah de-optimasi . Kami tidak berbicara tentang konsep yang sama sekali berbeda, tetapi dengan deoptimisasi yang kami maksud adalah kembali ke penafsir sebagai pengoptimalan yang disadari, dan bukan solusi untuk keniscayaan bahasa dinamis. Hotspot dan Graal banyak menggunakan de-optimasi, terutama Graal, karena developer memiliki kontrol yang ketat atas kompilasi dan bahkan membutuhkan lebih banyak kontrol atas kompilasi untuk pengoptimalan (dibandingkan dengan, katakanlah, Pypy). Deoptimisasi juga digunakan di mesin JS, yang akan banyak saya bicarakan, karena JavaScript di Chrome dan Node.js bergantung padanya.
Untuk menerapkan de-optimasi dengan cepat, penting untuk memastikan bahwa Anda beralih antara compiler dan interpreter secepat mungkin. Dengan implementasi yang paling naif, interpreter harus “mengejar” compiler untuk melakukan de-optimasi. Detail tambahan terkait dengan penghentian pengoptimalan aliran asinkron. Graal membuat satu set frame dan mencocokkannya dengan kode yang dihasilkan untuk dikembalikan ke interpreter. Dengan safepoints, Anda dapat membuat thread Java berhenti sebentar dan berkata, "Halo, pengumpul sampah, apakah saya perlu berhenti?" Sehingga pemrosesan thread tidak memerlukan banyak overhead. Ini ternyata agak kasar, tetapi bekerja cukup cepat untuk de-optimasi menjadi strategi yang baik.
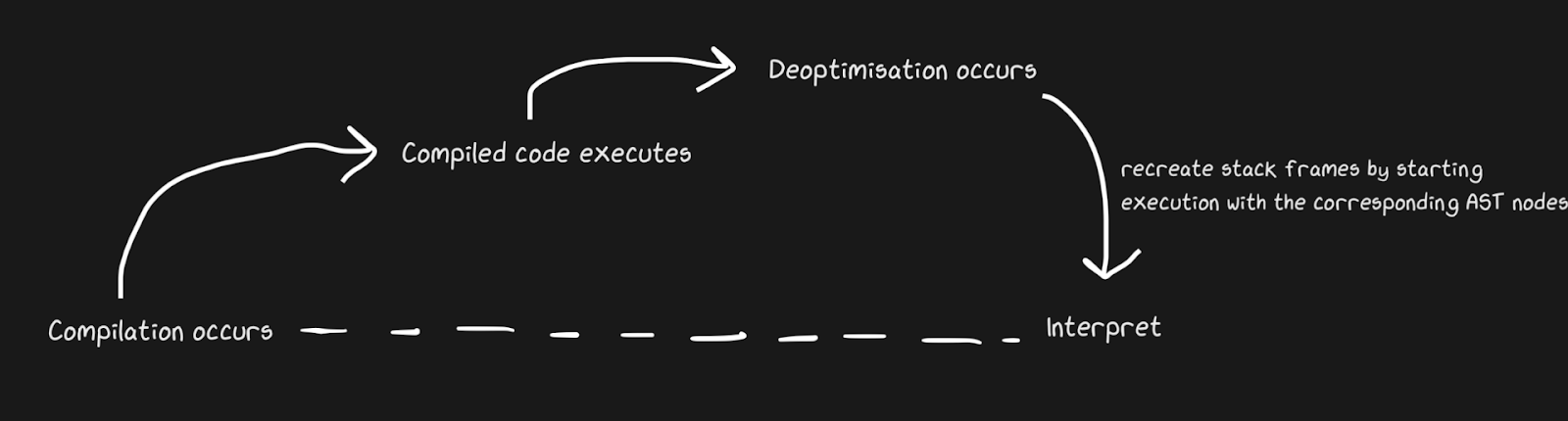
Mirip dengan contoh penghubung Pypy, fungsi tambalan monyet dapat dinonaktifkan. Ini lebih elegan karena kami menambahkan kode de-optimasi bukan ketika pembela gagal, tetapi ketika penambalan gerilya diterapkan.
Contoh yang bagus dari pengoptimalan JIT: overflow konversi adalah istilah tidak resmi. Kami berbicara tentang situasi ketika jenis tertentu (misalnya,
int32) diwakili / dialokasikan secara internal , tetapi perlu diubah menjadi int64. TruffleRuby melakukan ini dengan de-optimasi, seperti V8.
Misalnya, jika Anda bertanya di Ruby
var = 0, Anda mendapatkan int32(Ruby menyebutnya Fixnumdan Bignum, tapi saya akan menggunakan notasi int32dan int64). Melakukan operasi denganvar, Anda perlu memeriksa apakah terjadi luapan nilai. Tapi itu satu hal untuk diperiksa, dan mengkompilasi kode yang menangani luapan itu mahal, terutama mengingat frekuensi operasi numerik.
Tanpa melihat instruksi yang telah dikompilasi, Anda dapat melihat bagaimana de-optimasi ini mengurangi jumlah kode.
int a, b;
int sum = a + b;
if (overflowed) {
long bigSum = a + b;
return bigSum;
} else {
return sum;
}
int a, b;
int sum = a + b;
if (overflowed) {
Deoptimize!
}
Di TruffleRuby, hanya operasi pertama dari operasi tertentu yang tidak dioptimalkan, jadi kami tidak membuang sumber daya untuk itu setiap kali operasi meluap.
Kode WET adalah kode cepat. Inlining dan OSR
function foo(a, b) {
return a + b;
}
for (var i = 0; i < 1000000; i++) {
foo(i, i + 1);
}
foo(1, 2);
Bahkan hal-hal sepele seperti pemicu ini dinonaktifkan di V8! Dengan opsi seperti
--trace-deoptdan, --trace-optAnda dapat mengumpulkan banyak informasi tentang JIT dan juga mengubah perilakunya. Graal memiliki beberapa alat yang sangat berguna, tetapi saya akan menggunakan V8 karena banyak yang sudah menginstalnya.
Deoptimization dimulai oleh baris terakhir (
foo(1, 2)), yang membingungkan, karena panggilan ini dibuat dalam loop! Kami akan menerima pesan "Jenis masukan tidak mencukupi untuk panggilan" (daftar lengkap alasan penghentian pengoptimalan ada di sini , dan ada alasan lucu "tidak ada alasan" di dalamnya). Ini menciptakan bingkai input yang menampilkan literal 1dan 2.
Jadi mengapa membatalkan pengoptimalan? V8 cukup pintar untuk melakukan typecasting: saat
imengetikinteger, literal juga diteruskan integer.
Untuk memahami ini, mari kita ganti baris terakhir dengan
foo(i, i +1). Tapi de-optimasi masih diterapkan, hanya kali ini pesannya berbeda: "Jenis masukan tidak mencukupi untuk operasi biner". MENGAPA?! Bagaimanapun, ini adalah operasi yang persis sama yang dilakukan dalam satu loop, dengan variabel yang sama!
Jawabannya sobat terletak pada on-stack replacement (OSR). Inlining adalah pengoptimalan kompilator yang kuat (tidak hanya JIT) di mana fungsi berhenti menjadi fungsi, dan konten diteruskan ke tempat panggilan. Compiler JIT dapat melakukan inline untuk meningkatkan kecepatan dengan mengubah kode pada saat runtime (bahasa yang dikompilasi hanya dapat melakukan inline secara statis).
// partial output from printing inlining details
[compiling method 0x04a0439f3751 <JSFunction (sfi = 0x4a06ab56121)> using TurboFan OSR]
0x04a06ab561e9 <SharedFunctionInfo foo>: IsInlineable? true
Inlining small function(s) at call site #49:JSCall
Jadi V8 akan mengkompilasi
foo, menentukan bahwa itu bisa sebaris, dan sejajar dengan OSR. Namun, mesin melakukan ini hanya untuk kode di dalam loop, karena ini adalah jalur panas, dan baris terakhir belum ada di interpreter pada saat inline. Oleh karena itu, V8 belum memiliki cukup umpan balik pada jenis fungsinya foo, karena bukan digunakan dalam loop, tetapi versi inline-nya. Jika diterapkan --no-use-osr, maka tidak akan ada deoptimisasi, apapun yang kita lewati, literal atau i. Namun, tanpa sebaris, bahkan sedikit juta iterasi akan berjalan lebih lambat. Penyusun JIT benar-benar mewujudkan prinsip pertukaran-solusi-hanya-trade-off. Pengoptimalan itu mahal, tetapi tidak sebanding dengan biaya menemukan metode dan penyebarisan, yang lebih disukai dalam kasus ini.
Inlining sangat efektif! Saya menjalankan kode di atas dengan beberapa nol ekstra dan itu berjalan empat kali lebih lambat dengan inlining dinonaktifkan.

Meskipun artikel ini tentang JIT, inlining juga efektif dalam bahasa yang dikompilasi. Semua bahasa LLVM secara aktif menggunakan sebaris, karena LLVM juga akan melakukan ini, meskipun Julia sebaris tanpa LLVM, ini sifatnya. JIT dapat disisipkan menggunakan heuristik waktu proses dan dapat beralih antara mode non-sebaris dan sebaris menggunakan OSR.
Catatan tentang JIT dan LLVM
LLVM menyediakan banyak alat yang berhubungan dengan kompilasi. Julia bekerja dengan LLVM (perhatikan bahwa ini adalah kotak peralatan besar dan setiap bahasa menggunakannya secara berbeda), seperti Rust, Swift dan Crystal. Cukuplah untuk mengatakan bahwa ini adalah proyek besar dan luar biasa yang juga mendukung JIT, meskipun LLVM tidak memiliki JIT dinamis bawaan yang signifikan. Tingkat keempat dari kompilasi JavaScriptCore menggunakan backend LLVM untuk sementara waktu, tetapi diganti kurang dari dua tahun yang lalu. Sejak saat itu, toolkit ini tidak terlalu cocok untuk JIT dinamis, terutama karena tidak dirancang untuk bekerja di lingkungan yang dinamis. Pypy mencobanya 5-6 kali, tetapi menetap di JSC. Dengan LLVM, penurunan alokasi dan gerakan kode dibatasi.Itu juga tidak mungkin untuk menggunakan fitur JIT yang kuat seperti range-inferencing (seperti casting, tetapi dengan kisaran nilai yang diketahui). Tetapi yang lebih penting, dengan LLVM, banyak sumber daya dihabiskan untuk kompilasi.
Bagaimana jika alih-alih representasi perantara berbasis instruksi, kami memiliki grafik besar yang memodifikasi dirinya sendiri?
Kami berbicara tentang bytecode LLVM dan bytecode Python / Ruby / Java sebagai representasi perantara. Mereka semua terlihat seperti semacam bahasa dalam bentuk instruksi. Hotspot, Graal, dan V8 menggunakan representasi perantara "Sea of Nodes" (diperkenalkan di Hotspot), yang merupakan AST tingkat lebih rendah. Ini adalah pandangan yang efektif karena bagian penting dari pembuatan profil didasarkan pada gagasan tentang jalur tertentu yang jarang digunakan (atau disilangkan dalam kasus beberapa pola). Perhatikan bahwa kompiler AST ini berbeda dari parser AST.
Biasanya saya menganut posisi "coba di rumah!" Misalnya, saya tidak dapat membaca semua grafik bukan hanya karena kurangnya pengetahuan, tetapi juga karena kemampuan komputasi otak saya (opsi kompiler dapat membantu menghilangkan perilaku yang tidak saya minati).
Dalam kasus V8, kami akan menggunakan alat D8 dengan sebuah bendera
--print-ast. Untuk Graal itu akan terjadi --vm.Dgraal.Dump=Truffle:2. Teks akan ditampilkan di layar (diformat untuk mendapatkan grafik). Saya tidak tahu bagaimana pengembang V8 menghasilkan grafik visual, tetapi Oracle memiliki "Visualizer Grafik Ideal" yang digunakan dalam ilustrasi sebelumnya. Saya tidak memiliki kekuatan untuk menginstal ulang IGV, jadi saya mengambil grafik dari Chris Seaton, yang dibuat dengan Seafoam, yang sumbernya sekarang ditutup.
Oke, mari kita lihat JavaScript AST!
function accumulate(n, a) {
var x = 0;
for (var i = 0; i < n; i++) {
x += a;
}
return x;
}
accumulate(1, 1)
Saya menjalankan kode ini
d8 --print-ast test.js, meskipun kami hanya tertarik pada fungsinya accumulate. Lihat bahwa saya hanya memanggilnya sekali, artinya, saya tidak perlu menunggu kompilasi untuk mendapatkan AST.
Seperti inilah tampilan AST (Saya menghapus beberapa baris yang tidak penting):
FUNC at 19
. NAME "accumulate"
. PARAMS
. . VAR (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VAR (0x7ff535815798) (mode = VAR, assigned = false) "a"
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
. FOR at 43
. . INIT at -1
. . . BLOCK NOCOMPLETIONS at -1
. . . . EXPRESSION STATEMENT at 56
. . . . . INIT at 56
. . . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . . . LITERAL 0
. . COND at 61
. . . LT at 61
. . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. . . . VAR PROXY parameter[0] (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . BODY at -1
. . . BLOCK at -1
. . . . EXPRESSION STATEMENT at 77
. . . . . ASSIGN_ADD at 79
. . . . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . . . VAR PROXY parameter[1] (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . NEXT at 67
. . . EXPRESSION STATEMENT at 67
. . . . POST INC at 67
. . . . . VAR PROXY local[1] (0x7ff535815930) (mode = VAR, assigned = true) "i"
. RETURN at 91
. . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
Sulit untuk mem-parse ini, tetapi ini terlihat seperti AST dari parser (tidak berlaku untuk semua program). Dan AST berikutnya dibuat menggunakan Acorn.js.
Perbedaan yang mencolok adalah definisi variabel. Dalam AST parser, tidak ada definisi eksplisit dari parameter, dan deklarasi loop disembunyikan di node
ForStatement. Dalam AST level compiler, semua deklarasi dikelompokkan dengan alamat dan metadata.
Kompilator AST juga menggunakan ekspresi bodoh ini
VAR PROXY. AST parser tidak dapat menentukan hubungan antara nama dan variabel (berdasarkan alamat) karena variabel (hoisting), evaluasi (eval) dan lain-lain. Jadi AST penyusun menggunakan variabel PROXYyang kemudian dikaitkan dengan variabel sebenarnya.
// This chunk is the declarations and the assignment of `x = 0`
. DECLS
. . VARIABLE (0x7ff5358156f0) (mode = VAR, assigned = false) "n"
. . VARIABLE (0x7ff535815798) (mode = VAR, assigned = false) "a"
. . VARIABLE (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . VARIABLE (0x7ff535815930) (mode = VAR, assigned = true) "i"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 38
. . . INIT at 38
. . . . VAR PROXY local[0] (0x7ff535815840) (mode = VAR, assigned = true) "x"
. . . . LITERAL 0
Dan seperti inilah AST dari program yang sama, yang diperoleh dengan menggunakan Graal, terlihat seperti!
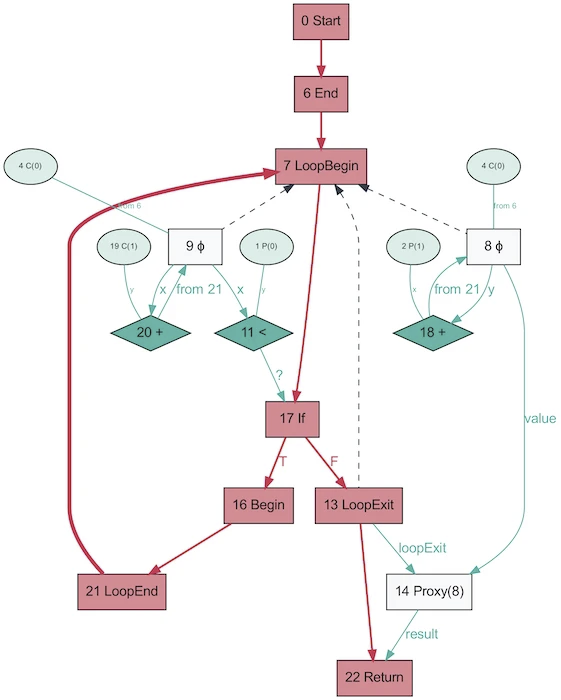
Ini terlihat jauh lebih sederhana. Merah menunjukkan aliran kontrol, biru menunjukkan aliran data, panah menunjukkan arah. Perhatikan bahwa meskipun grafik ini lebih sederhana daripada AST dari V8, ini tidak berarti Graal telah menyederhanakan program dengan lebih baik. Itu baru saja dibuat berdasarkan Java, yang jauh lebih tidak dinamis. Grafik Graal yang sama yang dihasilkan dari Ruby akan lebih mirip dengan versi pertama.
Lucu bahwa AST di Graal akan berubah tergantung pada eksekusi kodenya. Grafik ini dibuat dengan OSR dan inlining dinonaktifkan, ketika fungsi dipanggil berulang kali dengan parameter acak sehingga tidak dioptimalkan. Dan dump akan memberi Anda banyak grafik! Graal menggunakan AST khusus untuk mengoptimalkan program (V8 melakukan pengoptimalan serupa, tetapi tidak pada level AST). Saat Anda menyimpan grafik di Graal, Anda mendapatkan lebih dari sepuluh skema dengan tingkat pengoptimalan yang berbeda. Saat menulis ulang node, mereka mengganti dirinya sendiri (mengkhususkan) dengan node lain.
Grafik di atas adalah contoh yang sangat baik dari spesialisasi dalam bahasa yang diketik secara dinamis (gambar diambil dari One VM ke Rule Them All, 2013). Alasan proses ini ada terkait erat dengan cara kerja penilaian parsial - ini semua tentang spesialisasi.
Hore JIT mengkompilasi kode! Ayo kompilasi lagi! Dan lagi!
Di atas saya sebutkan tentang "multilevel", mari kita bicarakan. Idenya sederhana: jika kita belum siap untuk membuat kode yang dioptimalkan sepenuhnya, tetapi interpretasinya masih mahal, kita dapat melakukan pra-kompilasi dan kemudian mengkompilasi akhir ketika kita siap untuk menghasilkan kode yang lebih dioptimalkan.
Hotspot adalah JIT berlapis dengan dua kompiler, C1 dan C2. C1 melakukan kompilasi cepat dan menjalankan kode, kemudian melakukan profil lengkap untuk mendapatkan kode yang dikompilasi dengan C2. Ini dapat membantu memecahkan banyak masalah pemanasan. Kode terkompilasi yang tidak dioptimalkan lebih cepat daripada interpretasi. Juga, C1 dan C2 tidak mengkompilasi semua kode. Jika fungsinya terlihat cukup sederhana, dengan probabilitas tinggi C2 tidak akan membantu kami dan bahkan tidak akan berjalan (kami juga akan menghemat waktu dalam pembuatan profil!). Jika C1 sibuk menyusun, maka pembuatan profil dapat dilanjutkan, pekerjaan C1 akan terhenti dan kompilasi dengan C2 dimulai.
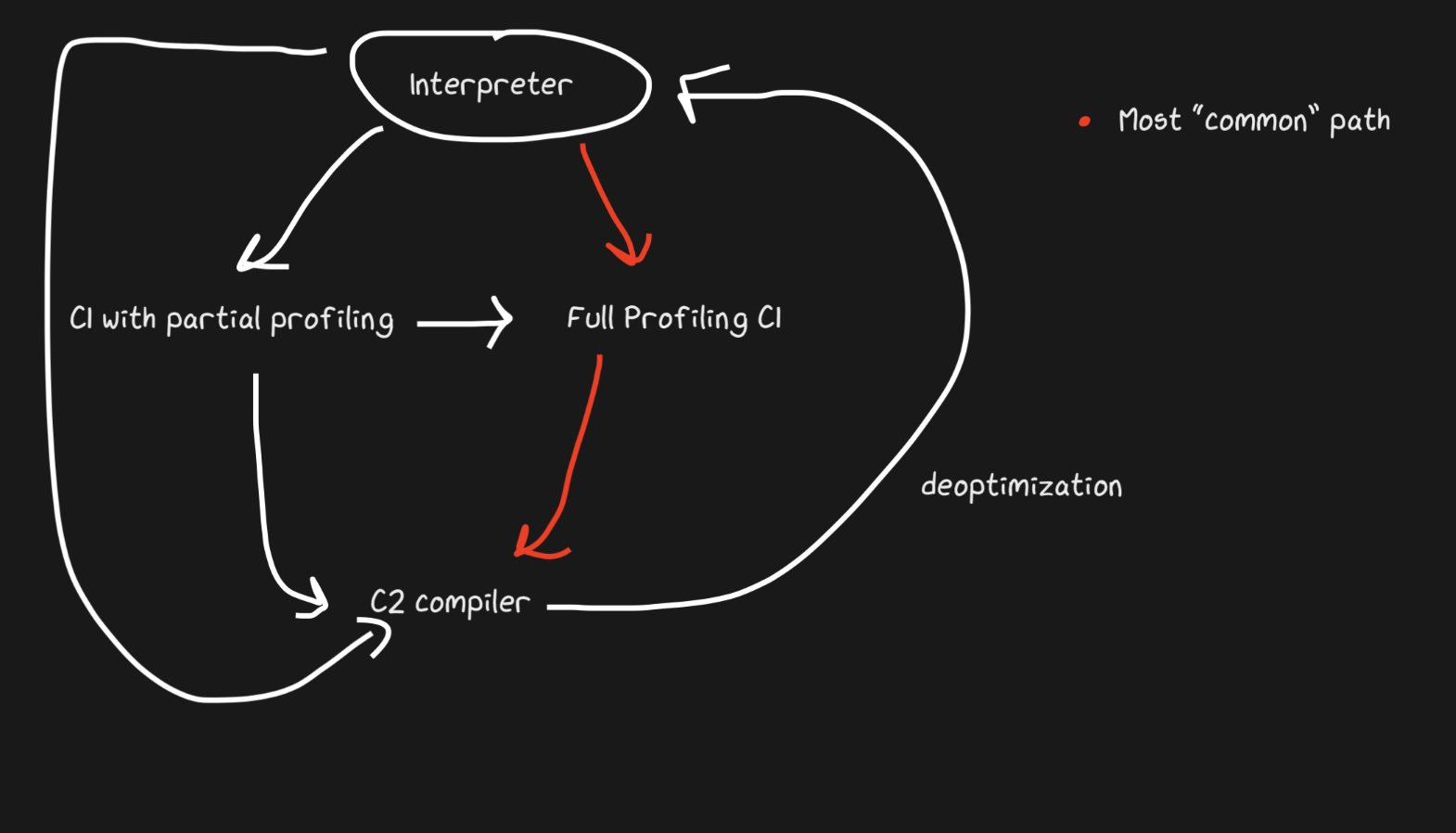
JavaScript Core memiliki lebih banyak level! Faktanya, ada tiga JIT . Penerjemah JSC melakukan beberapa profil ringan, lalu pergi ke Baseline JIT, lalu DFG (Data Flow Graph) JIT, dan terakhir FTL (Faster than Light) JIT. Dengan banyaknya level tersebut, pengertian de-optimization tidak lagi terbatas pada peralihan dari compiler ke interpreter, de-optimization dapat dilakukan dimulai dengan DFG dan diakhiri dengan Baseline JIT (tidak demikian pada kasus Hotspot C2-> C1). Semua de-optimasi dan transisi ke level berikutnya dilakukan menggunakan OSR (Stack Override).
Baseline JIT terhubung setelah sekitar 100 eksekusi, dan DFG JIT setelah sekitar 1000 (dengan beberapa pengecualian). Ini berarti bahwa JIT mendapatkan kode yang dikompilasi jauh lebih cepat daripada Pypy yang sama (yang membutuhkan sekitar 3000 eksekusi). Layering memungkinkan JIT mencoba menghubungkan durasi eksekusi kode dengan durasi pengoptimalannya. Ada banyak trik, jenis pengoptimalan (inlining, casting, dll.) Yang harus dilakukan di setiap level, dan oleh karena itu strategi ini optimal.
Sumber Bermanfaat
- Bagaimana Trace Compiler LuaJIT Bekerja dari Mike Pall
- Dampak Meta-tracing pada VM oleh Laurie Tratt
- Analisis Escape Pypy
- Mengapa Pengguna Tidak Lebih Senang dengan VM oleh Laurie Tratt
- Tentang mesin JS:
- Tentang deoptimization:
- Graal:
- :
- :