Manfaat menggunakan TensorFlow.js di browser
- interaktivitas - browser memiliki banyak alat untuk memvisualisasikan proses yang sedang berlangsung (grafik, animasi, dll.);
- sensor - browser memiliki akses langsung ke sensor perangkat (kamera, GPS, akselerometer, dll.);
- keamanan data pengguna - tidak perlu mengirim data yang telah diproses ke server;
- kompatibilitas dengan model yang dibuat dengan Python .
Performa
Salah satu masalah utamanya adalah kinerja.
Karena fakta bahwa pembelajaran mesin, pada kenyataannya, melakukan berbagai jenis operasi matematika dengan data seperti matriks (tensor), pustaka untuk jenis penghitungan ini di browser menggunakan WebGL. Ini secara signifikan meningkatkan kinerja jika operasi yang sama dilakukan dalam JS murni. Biasanya, pustaka memiliki cadangan jika WebGL tidak didukung di browser karena alasan tertentu (pada saat artikel ini ditulis, caniuse menunjukkan bahwa 97,94% pengguna memiliki dukungan WebGL).
Untuk meningkatkan performa, Node.js menggunakan native-binding dengan TensorFlow. Di sini, CPU, GPU, dan TPU ( Tensor Processing Unit ) dapat berfungsi sebagai akselerator
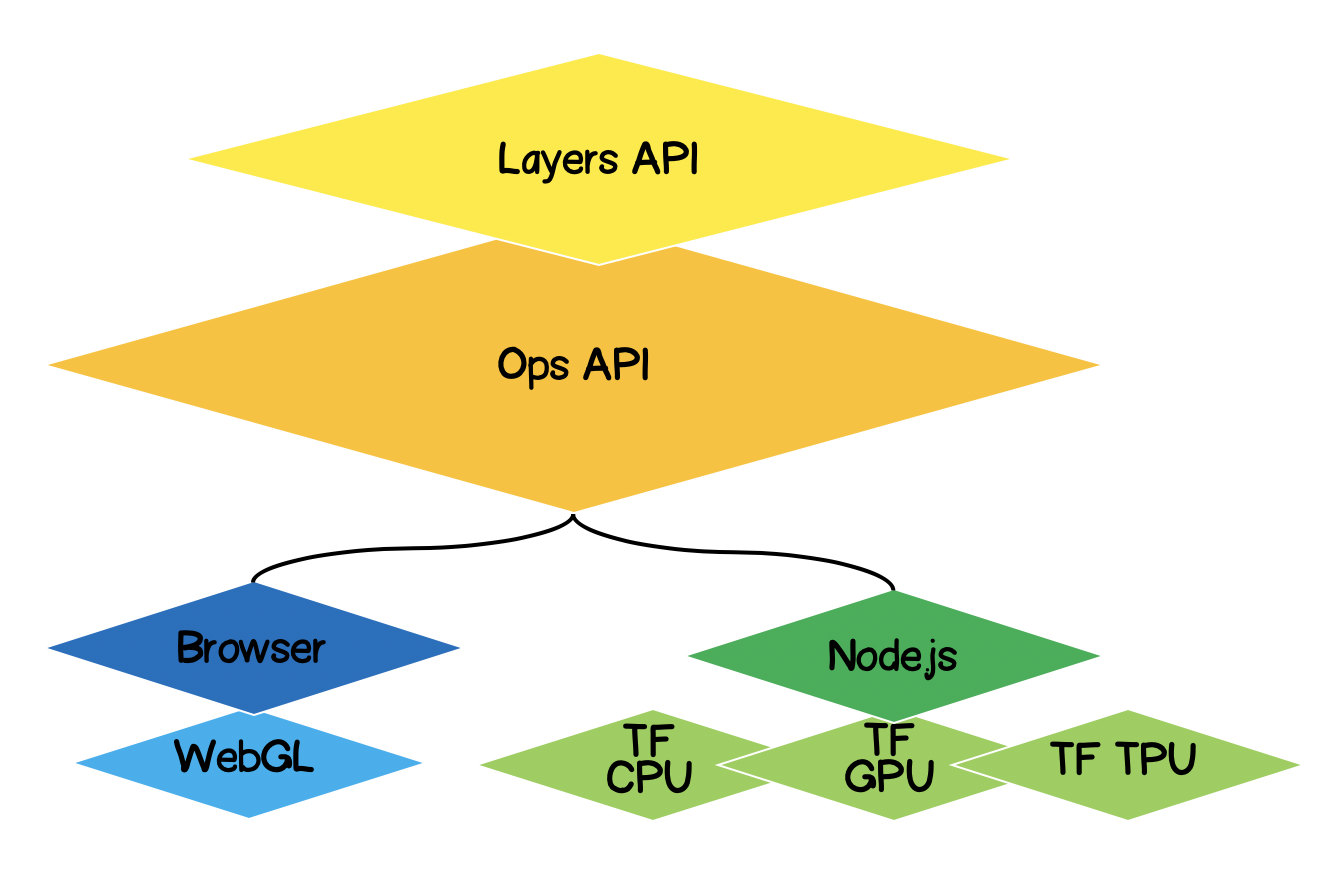
Arsitektur TensorFlow.js.
- Lapisan Terendah - lapisan ini bertanggung jawab untuk memparalelkan komputasi saat melakukan operasi matematika pada tensor.
- Ops API - Menyediakan API untuk melakukan operasi matematika pada tensor.
- API Lapisan - memungkinkan Anda membuat model jaringan neural yang kompleks menggunakan berbagai jenis lapisan (padat, konvolusional). Lapisan ini mirip dengan API Keras Python dan memiliki kemampuan untuk memuat jaringan berbasis Keras Python yang telah dilatih sebelumnya.
Rumusan masalah
Penting untuk menemukan persamaan dari fungsi linier yang mendekati untuk himpunan titik eksperimental tertentu. Dengan kata lain, kita perlu menemukan kurva linier yang paling mendekati titik-titik percobaan.

Formalisasi solusi
Inti dari pembelajaran mesin apa pun adalah model, dalam kasus kami ini adalah persamaan fungsi linier:
Berdasarkan kondisi tersebut, kami juga memiliki sekumpulan poin percobaan:
Misalkan pada langkah pelatihan, koefisien berikut dari persamaan linier dihitung . Sekarang kita perlu mengungkapkan secara matematis seberapa akurat koefisien yang dipilih. Untuk melakukan ini, kita perlu menghitung kesalahan (kerugian), yang dapat ditentukan, misalnya dengan standar deviasi. Tensorflow.js menawarkan sekumpulan fungsi kerugian yang umum digunakan:tf.metrics.meanAbsoluteError,tf.metrics.meanSquaredError, dll.
Tujuan dari aproksimasi adalah untuk meminimalkan fungsi kesalahan . Mari gunakan metode penurunan gradien untuk ini. Itu perlu:
- - temukan vektor gradien dengan menghitung turunan parsial sehubungan dengan koefisien ;
- - perbaiki koefisien persamaan pada arah yang berlawanan dengan arah vektor gradien. Jadi, kami akan meminimalkan fungsi kesalahan:
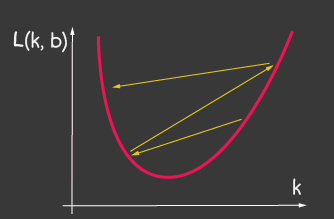
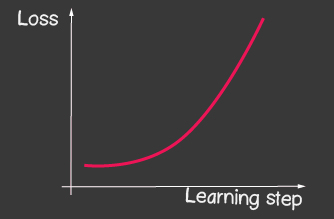
adalah kecepatan pembelajaran dan merupakan salah satu parameter model yang dapat disesuaikan. Untuk penurunan gradien, itu tidak berubah selama proses pembelajaran. Nilai kecil dari kecepatan pemelajaran dapat menyebabkan konvergensi yang lama dari proses pembelajaran model dan kemungkinan hit di minimum lokal (Gambar 2), dan nilai yang sangat besar dapat menyebabkan peningkatan tak terbatas dalam nilai kesalahan pada setiap langkah pelatihan, Gambar 1.
|


|
|---|---|
| Gambar 1: Nilai kecepatan pembelajaran yang tinggi | Gambar 2: Kecepatan Belajar Kecil |
Cara mengimplementasikannya tanpa Tensorflow.js
Misalnya, menghitung nilai fungsi kerugian (deviasi standar) akan terlihat seperti ini:
function loss(ysPredicted, ysReal) {
const squaredSum = ysPredicted.reduce(
(sum, yPredicted, i) => sum + (yPredicted - ysReal[i]) ** 2,
0);
return squaredSum / ysPredicted.length;
}
Namun, jumlah data masukan bisa jadi besar. Saat melatih model, kita tidak hanya perlu menghitung nilai fungsi kerugian pada setiap iterasi, tetapi juga melakukan operasi yang lebih serius - menghitung gradien. Oleh karena itu, masuk akal untuk menggunakan tensorflow, yang mengoptimalkan penghitungan dengan menggunakan WebGL. Selain itu, kodenya menjadi jauh lebih ekspresif, bandingkan:
function loss(ysPredicted, ysReal) => {
const ysPredictedTensor = tf.tensor(ysPredicted);
const ysRealTensor = tf.tensor(ysReal);
const loss = ysPredictedTensor.sub(ysRealTensor).square().mean();
return loss.dataSync()[0];
};
Solusi dengan TensorFlow.js
Kabar baiknya adalah kita tidak perlu menulis pengoptimal untuk fungsi kesalahan yang diberikan (kerugian), kita tidak akan mengembangkan metode numerik untuk menghitung turunan parsial, kita telah menerapkan algoritma backpropogation untuk kita. Kami hanya perlu mengikuti langkah-langkah ini:
- mengatur model (fungsi linier, dalam kasus kami);
- jelaskan fungsi kesalahan (dalam kasus kami, ini adalah deviasi standar)
- pilih salah satu pengoptimal yang diterapkan (dimungkinkan untuk memperluas pustaka dengan penerapan Anda sendiri)
Apa itu tensor
Tentunya setiap orang telah menemukan tensor dalam matematika - ini adalah skalar, vektor, 2D - matriks, 3D - matriks. Tensor adalah konsep umum dari semua hal di atas. Ini adalah wadah data yang berisi data dengan tipe homogen (tensorflow mendukung int32, float32, bool, complex64, string) dan memiliki bentuk tertentu (jumlah sumbu (peringkat) dan jumlah elemen di setiap sumbu). Di bawah ini kita akan mempertimbangkan tensor hingga matriks 3D, tetapi karena ini adalah generalisasi, tensor dapat memiliki sumbu sebanyak yang kita inginkan: 5D, 6D, ... ND.
TensorFlow memiliki API berikut untuk pembuatan tensor:
tf.tensor (values, shape?, dtype?)di mana bentuk adalah bentuk dari tensor dan diberikan oleh larik, di mana jumlah elemen adalah jumlah sumbu, dan setiap nilai larik menentukan jumlah elemen di sepanjang masing-masing sumbu. Misalnya untuk mendefinisikan matriks 4x2 (4 baris, 2 kolom), maka bentuknya adalah [4, 2].
| Visualisasi | Deskripsi |
|---|---|

|
Peringkat Skalar : 0 Bentuk: [] Struktur JS: TensorFlow API: |

|
Peringkat Vektor : 1 Bentuk: [4] Struktur JS: TensorFlow API: |
 |
Peringkat Matriks : 2 Bentuk: [4,2] Struktur JS: TensorFlow API: |
 |
Peringkat Matriks : 3 Bentuk: [4,2,3] Struktur JS: TensorFlow API: |
Pendekatan linier dengan TensorFlow.js
Awalnya, kita akan berbicara tentang membuat kode dapat diperluas. Kita dapat mengubah pendekatan linier menjadi perkiraan titik percobaan dengan fungsi apa pun. Hierarki kelas akan terlihat seperti ini:

Mari mulai mengimplementasikan metode kelas abstrak, dengan pengecualian metode abstrak yang akan didefinisikan di kelas anak, dan di sini kita hanya akan menyisakan stub dengan kesalahan, jika karena alasan tertentu metode tersebut tidak ditentukan di kelas anak.
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
}Jadi, dalam konstruktor model kita telah menentukan lebar dan tinggi - ini adalah lebar dan tinggi sebenarnya dari bidang tempat kita akan menempatkan titik-titik percobaan. Ini diperlukan untuk menormalkan data masukan. Itu. jika kita punya, maka setelah normalisasi kita akan memiliki:
optimizerFunction - kami akan membuat tugas pengoptimal menjadi fleksibel, agar dapat mencoba pengoptimal lain yang tersedia di perpustakaan, secara default kami telah menyetel metode Penurunan Gradien Stochastic tf.train.sgd . Saya juga merekomendasikan bermain dengan pengoptimal lain yang tersedia yang dapat mengubah learningRate selama pelatihan dan proses pembelajaran sangat ditingkatkan, misalnya, coba pengoptimal berikut: tf.train.momentum , tf.train.adam .
Agar proses pembelajaran tidak henti-hentinya, kita telah mendefinisikan dua parameter maxEpochPerTrainSesion dan expectedLoss.- dengan cara ini kami akan menghentikan proses pelatihan baik ketika jumlah maksimum iterasi pelatihan tercapai, atau ketika nilai fungsi kesalahan menjadi lebih rendah dari kesalahan yang diharapkan (kami akan mempertimbangkan semuanya dalam metode kereta di bawah).
Dalam konstruktor, kita memanggil metode initModelVariables - tetapi seperti yang telah disepakati, kita stub dan mendefinisikannya di kelas anak nanti.
initModelVariables() {
throw Error('Model variables should be defined')
}
Sekarang mari kita terapkan metode utama model kereta:
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert array into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
trainSession pada dasarnya adalah pengenal unik untuk sesi pelatihan jika API eksternal memanggil metode kereta, sedangkan sesi pelatihan sebelumnya belum berakhir.
Dari kode tersebut Anda dapat melihat bahwa kita membuat tensor1d dari array satu dimensi, sedangkan datanya harus dinormalisasi terlebih dahulu, fungsi untuk normalisasi ada di sini:
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
Dalam satu putaran, untuk setiap langkah pelatihan, kita memanggil pengoptimal model, yang mana kita harus meneruskan fungsi kerugian. Sesuai kesepakatan, fungsi kerugian akan ditetapkan oleh deviasi standar. Kemudian menggunakan API tensorflow.js kami memiliki:
/**
* Calculate loss function as mean-square deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
// L = sum ((x_pred_i - x_real_i)^2) / N
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
Proses pembelajaran terus berlanjut
- batas jumlah iterasi tidak akan tercapai
- akurasi kesalahan yang diinginkan tidak akan tercapai
- proses pelatihan baru belum dimulai
Perhatikan juga bagaimana fungsi kerugian dipanggil. Untuk mendapatkan predictValue - kita memanggil fungsi f - yang, sebenarnya, akan menyetel bentuk yang sesuai dengan regresi akan dilakukan, dan di kelas abstrak, seperti yang disepakati, kita meletakkan stub:
f(x) {
throw Error('Model should be defined')
}
Di setiap langkah pelatihan, di properti objek model riwayat, kami menyimpan dinamika perubahan kesalahan di setiap periode pelatihan.
Setelah proses pelatihan model, kita perlu memiliki metode yang menerima masukan dan keluaran dari keluaran yang dihitung dengan menggunakan model terlatih. Untuk melakukan ini, di API, kami telah menentukan metode prediksi dan terlihat seperti ini:
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
Perhatikan arraySync , dengan analogi node.js, jika ada metode arraySync , maka pasti ada metode array asinkron yang mengembalikan Promise. Di sini dibutuhkan janji, karena seperti yang kami katakan sebelumnya, semua tensor dimigrasikan ke WebGL untuk mempercepat penghitungan dan prosesnya menjadi asinkron, karena perlu waktu untuk memindahkan data dari WebGL ke variabel JS.
Kami selesai dengan kelas abstrak, Anda dapat melihat versi lengkap kode di sini:
AbstractRegressionModel.js
import * as tf from '@tensorflow/tfjs';
export default class AbstractRegressionModel {
constructor(
width,
height,
optimizerFunction = tf.train.sgd,
maxEpochPerTrainSession = 100,
learningRate = 0.1,
expectedLoss = 0.001
) {
this.width = width;
this.height = height;
this.optimizerFunction = optimizerFunction;
this.expectedLoss = expectedLoss;
this.learningRate = learningRate;
this.maxEpochPerTrainSession = maxEpochPerTrainSession;
this.initModelVariables();
this.trainSession = 0;
this.epochNumber = 0;
this.history = [];
}
initModelVariables() {
throw Error('Model variables should be defined')
}
f() {
throw Error('Model should be defined')
}
xNormalization = xs => xs.map(x => x / this.width);
yNormalization = ys => ys.map(y => y / this.height);
yDenormalization = ys => ys.map(y => y * this.height);
/**
* Calculate loss function as mean-squared deviation
*
* @param predictedValue - tensor1d - predicted values of calculated model
* @param realValue - tensor1d - real value of experimental points
*/
loss = (predictedValue, realValue) => {
const loss = predictedValue.sub(realValue).square().mean();
this.lossVal = loss.dataSync()[0];
return loss;
};
/**
* Train model until explicitly stop process via invocation of stop method
* or loss achieve necessary accuracy, or train achieve max epoch value
*
* @param x - array of x coordinates
* @param y - array of y coordinates
* @param callback - optional, invoked after each training step
*/
async train(x, y, callback) {
const currentTrainSession = ++this.trainSession;
this.lossVal = Number.POSITIVE_INFINITY;
this.epochNumber = 0;
this.history = [];
// convert data into tensors
const input = tf.tensor1d(this.xNormalization(x));
const output = tf.tensor1d(this.yNormalization(y));
while (
currentTrainSession === this.trainSession
&& this.lossVal > this.expectedLoss
&& this.epochNumber <= this.maxEpochPerTrainSession
) {
const optimizer = this.optimizerFunction(this.learningRate);
optimizer.minimize(() => this.loss(this.f(input), output));
this.history = [...this.history, {
epoch: this.epochNumber,
loss: this.lossVal
}];
callback && callback();
this.epochNumber++;
await tf.nextFrame();
}
}
stop() {
this.trainSession++;
}
/**
* Predict value basing on trained model
* @param x - array of x coordinates
* @return Array({x: integer, y: integer}) - predicted values associated with input
*
* */
predict(x) {
const input = tf.tensor1d(this.xNormalization(x));
const output = this.yDenormalization(this.f(input).arraySync());
return output.map((y, i) => ({ x: x[i], y }));
}
}
Untuk regresi linier, kita mendefinisikan kelas baru yang akan diturunkan dari kelas abstrak, di mana kita hanya perlu mendefinisikan dua metode initModelVariables dan f .
Karena kita mengerjakan pendekatan linier, kita harus menentukan dua variabel k, b - dan mereka akan menjadi tensor skalar. Untuk pengoptimal, kita harus menunjukkan bahwa mereka merdu (variabel), dan menetapkan angka acak sebagai nilai awal.
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}Pertimbangkan API untuk variabel di sini :
tf.variable (initialValue, trainable?, name?, dtype?)Perhatikan argumen kedua untuk bisa dilatih - variabel boolean dan secara default benar . Ini digunakan oleh pengoptimal, yang memberi tahu mereka apakah perlu mengonfigurasi variabel ini saat meminimalkan fungsi kerugian. Ini dapat berguna saat kita membangun model baru berdasarkan model yang telah dilatih sebelumnya yang diunduh dari Keras Python, dan kita yakin bahwa tidak perlu melatih ulang beberapa lapisan dalam model ini.
Selanjutnya, kita perlu mendefinisikan persamaan fungsi aproksimasi menggunakan API tensorflow, lihat kodenya dan Anda akan secara intuitif memahami cara menggunakannya:
f(x) {
// y = kx + b
return x.mul(this.k).add(this.b);
}Misalnya, dengan cara ini Anda dapat menentukan pendekatan kuadrat:
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f(x) {
// y = ax^2 + bx + c
return this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}Anda dapat melihat model untuk regresi linier dan kuadrat di sini:
LinearRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class LinearRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.k = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
}
f = x => x.mul(this.k).add(this.b);
}
QuadraticRegressionModel.js
import * as tf from '@tensorflow/tfjs';
import AbstractRegressionModel from "./AbstractRegressionModel";
export default class QuadraticRegressionModel extends AbstractRegressionModel {
initModelVariables() {
this.a = tf.scalar(Math.random()).variable();
this.b = tf.scalar(Math.random()).variable();
this.c = tf.scalar(Math.random()).variable();
}
f = x => this.a.mul(x.square()).add(this.b.mul(x)).add(this.c);
}
Di bawah ini adalah beberapa kode yang ditulis di React yang menggunakan model regresi linier tertulis dan membuat UX untuk pengguna:
Regression.js
import React, { useState, useEffect } from 'react';
import Canvas from './components/Canvas';
import LossPlot from './components/LossPlot_v3';
import LinearRegressionModel from './model/LinearRegressionModel';
import './RegressionModel.scss';
const WIDTH = 400;
const HEIGHT = 400;
const LINE_POINT_STEP = 5;
const predictedInput = Array.from({ length: WIDTH / LINE_POINT_STEP + 1 })
.map((v, i) => i * LINE_POINT_STEP);
const model = new LinearRegressionModel(WIDTH, HEIGHT);
export default () => {
const [points, changePoints] = useState([]);
const [curvePoints, changeCurvePoints] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
if (points.length > 0) {
const input = points.map(({ x }) => x);
const output = points.map(({ y }) => y);
model.train(input, output, () => {
changeCurvePoints(() => model.predict(predictedInput));
changeLossHistory(() => model.history);
});
}
}, [points]);
return (
<div className="regression-low-level">
<div className="regression-low-level__top">
<div className="regression-low-level__workarea">
<div className="regression-low-level__canvas">
<Canvas
width={WIDTH}
height={HEIGHT}
points={points}
curvePoints={curvePoints}
changePoints={changePoints}
/>
</div>
<div className="regression-low-level__toolbar">
<button
className="btn btn-red"
onClick={() => model.stop()}>Stop
</button>
<button
className="btn btn-yellow"
onClick={() => {
model.stop();
changePoints(() => []);
changeCurvePoints(() => []);
}}>Clear
</button>
</div>
</div>
<div className="regression-low-level__loss">
<LossPlot
loss={lossHistory}/>
</div>
</div>
</div>
)
}Hasil:
Saya sangat merekomendasikan melakukan tugas-tugas berikut:
- untuk menerapkan pendekatan fungsi dengan fungsi logaritmik
- untuk pengoptimal tf.train.sgd, coba mainkan dengan learningRate dan amati bagaimana proses pembelajaran berubah. Cobalah untuk mengatur learningRate sangat besar untuk mendapatkan gambar yang ditunjukkan pada Gambar 2.
- setel pengoptimal ke tf.train.adam. Apakah proses pembelajarannya meningkat? Apakah proses pembelajaran bergantung pada perubahan nilai learningRate di konstruktor model.