Pertama, kita akan membiasakan diri secara singkat dengan metode melintasi grafik, menulis pencarian jalur yang sebenarnya, dan kemudian beralih ke cara yang paling enak: mengoptimalkan kinerja dan biaya memori. Idealnya, Anda harus mengembangkan implementasi yang tidak menghasilkan sampah sama sekali saat digunakan.
Saya kagum ketika pencarian dangkal tidak memberi saya satu implementasi yang baik dari algoritma A * di C # tanpa menggunakan perpustakaan pihak ketiga (ini tidak berarti tidak ada). Jadi inilah waktunya untuk meregangkan jari Anda!
Saya menunggu pembaca yang ingin memahami cara kerja algoritma pathfinding, serta ahli dalam algoritma untuk berkenalan dengan implementasi dan metode pengoptimalannya.
Ayo mulai!
Bertamasya ke dalam sejarah
Jala dua dimensi dapat direpresentasikan sebagai grafik, di mana masing-masing simpul memiliki 8 sisi:
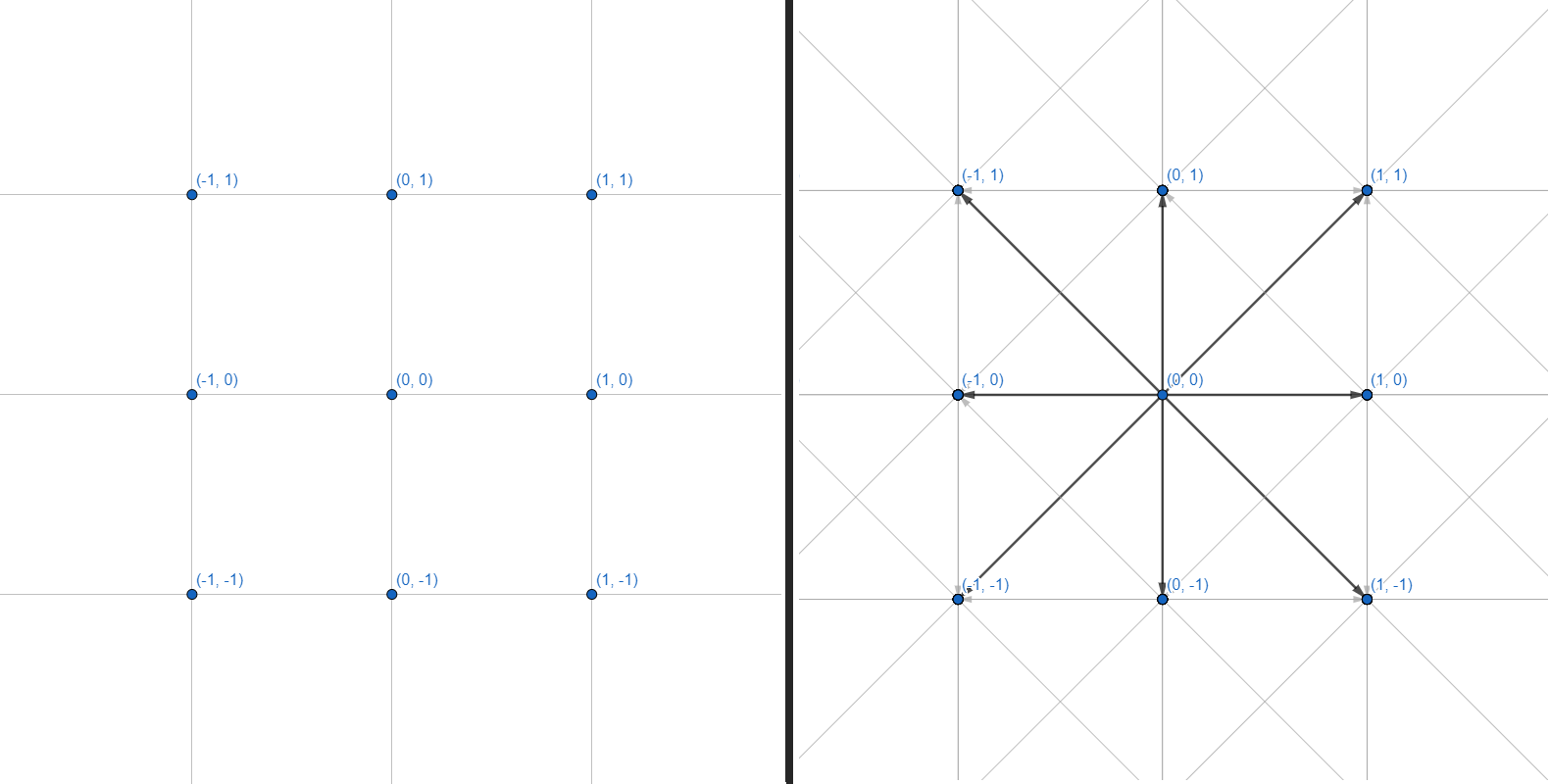
Kita akan bekerja dengan grafik. Setiap titik adalah koordinat bilangan bulat. Setiap tepi adalah transisi lurus atau diagonal antara koordinat yang berdekatan. Kami tidak akan melakukan kisi koordinat dan perhitungan geometri rintangan - kami akan membatasi diri pada antarmuka yang menerima beberapa koordinat sebagai masukan dan mengembalikan sekumpulan titik untuk membangun jalur:
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}Untuk memulainya, pertimbangkan metode yang ada untuk melintasi grafik.
Pencarian mendalam
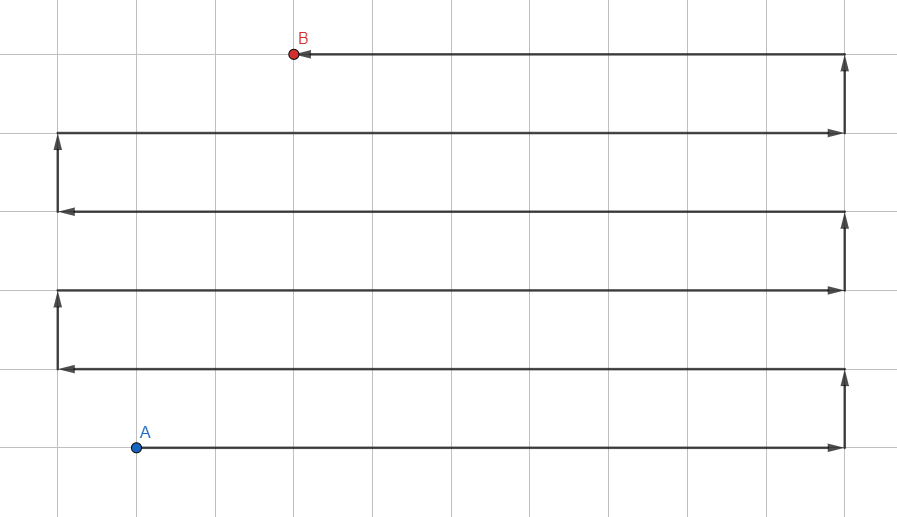
Algoritme yang paling sederhana:
- Tambahkan semua simpul yang belum dikunjungi di dekat simpul saat ini ke tumpukan.
- Pindah ke simpul pertama dari tumpukan.
- Jika puncak adalah yang diinginkan, keluar dari siklus. Jika Anda menemui jalan buntu, kembalilah.
- GOTO 1.
Ini terlihat seperti ini:
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
Ini diatur dalam format LIFO ( Last in - First out ), di mana simpul yang baru ditambahkan dianalisis terlebih dahulu. Setiap transisi antara simpul harus dipantau untuk kemudian membangun jalur aktual sepanjang transisi.
Pendekatan ini tidak akan pernah (yah, hampir) mengembalikan jalur terpendek karena memproses grafik dalam arah acak. Ini lebih cocok untuk grafik kecil untuk menentukan tanpa pusing apakah ada setidaknya beberapa jalur ke simpul yang diinginkan (misalnya, apakah tautan yang diinginkan ada di pohon teknologi).
Dalam kasus kisi navigasi dan grafik tak terbatas, pencarian ini tanpa akhir akan mengarah ke satu arah dan membuang sumber daya komputasi, tidak pernah mencapai titik yang diinginkan. Ini diselesaikan dengan membatasi area tempat algoritme beroperasi. Kami membuatnya menganalisis hanya titik-titik yang terletak tidak lebih dari N langkah dari yang awal. Jadi, saat algoritme mencapai batas wilayah, algoritme akan terbuka dan terus menganalisis simpul dalam radius yang ditentukan.
Kadang-kadang tidak mungkin untuk menentukan area secara akurat, tetapi Anda tidak ingin mengatur perbatasan secara acak. Pencarian kedalaman-pertama yang berulang datang untuk menyelamatkan :
- Tetapkan area minimum untuk DFS.
- Mulai mencari.
- Jika jalur tidak ditemukan, tambah area pencarian dengan 1.
- GOTO 2.
Algoritme akan berjalan berulang-ulang, setiap kali mencakup area yang lebih luas hingga akhirnya menemukan titik yang diinginkan.
Mungkin tampak seperti membuang-buang energi untuk menjalankan kembali algoritme pada radius yang sedikit lebih besar (bagaimanapun, sebagian besar area telah dianalisis pada iterasi terakhir!), Tetapi tidak: jumlah transisi antar simpul tumbuh secara geometris dengan setiap peningkatan dalam radius. Akan jauh lebih mahal untuk mengambil radius yang lebih besar dari yang Anda butuhkan, daripada berjalan beberapa kali sepanjang radius kecil.
Pencarian seperti itu mudah untuk memperketat batas waktu: ia akan mencari jalur dengan radius yang meluas tepat sampai waktu yang ditentukan berakhir.
Breadth First Search
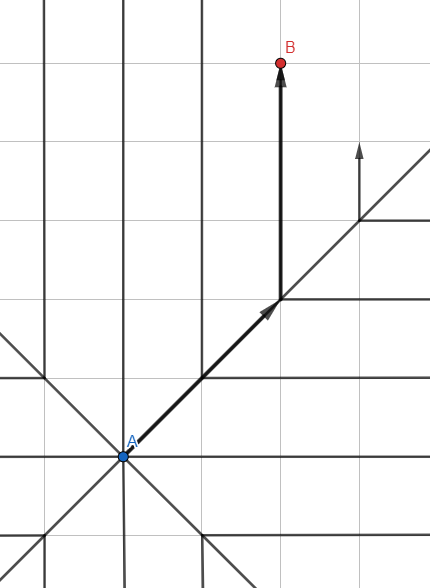
Ilustrasi tersebut mungkin menyerupai Pencarian Langsung - tetapi ini adalah algoritma gelombang yang biasa , dan garis-garis mewakili jalur perambatan pencarian dengan titik-titik perantara dihapus.
Berbeda dengan pencarian kedalaman-pertama menggunakan tumpukan (LIFO), mari kita ambil antrian (FIFO) untuk memproses simpul:
- Tambahkan semua tetangga yang belum dikunjungi ke antrean.
- Pergi ke simpul pertama dari antrian.
- Jika puncak adalah yang diinginkan, keluar dari siklus, jika tidak GOTO 1.
Ini terlihat seperti ini:
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
Pendekatan ini memberikan jalur yang optimal , tetapi ada kendala: karena algoritme memproses simpul ke segala arah, ia bekerja sangat lambat dalam jarak jauh dan grafik dengan percabangan yang kuat. Ini hanya kasus kami.
Di sini, area operasi algoritme tidak dapat dibatasi, karena dalam hal apa pun itu tidak akan melampaui radius ke titik yang diinginkan. Diperlukan metode pengoptimalan lain.
SEBUAH *
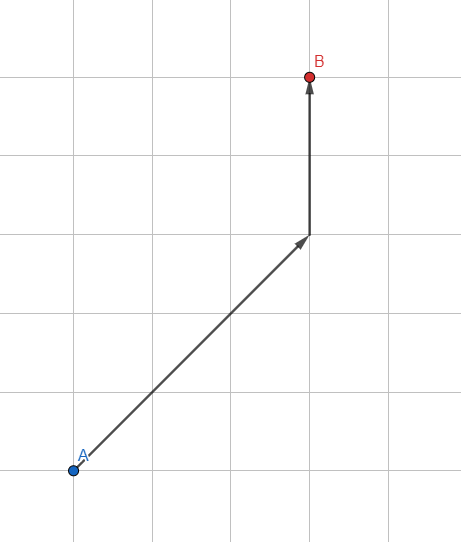
Mari kita ubah pencarian luas-pertama standar: kita tidak menggunakan antrian biasa untuk menyimpan simpul, tapi antrian yang diurutkan berdasarkan heuristik - perkiraan perkiraan jalur yang diharapkan.
Bagaimana cara memperkirakan jalur yang diharapkan? Yang paling sederhana adalah panjang vektor dari simpul yang diproses ke titik yang diinginkan. Semakin kecil vektornya, semakin menjanjikan titik dan semakin dekat ke awal antrean. Algoritme akan memprioritaskan simpul-simpul yang terletak di arah tujuan.
Jadi, setiap iterasi di dalam algoritme akan memakan waktu sedikit lebih lama karena perhitungan tambahan, tetapi dengan mengurangi jumlah simpul untuk analisis (hanya yang paling menjanjikan yang akan diproses), kami mencapai peningkatan kecepatan algoritme yang luar biasa.
Namun masih banyak simpul yang diproses. Mencari panjang vektor adalah operasi mahal yang melibatkan penghitungan akar kuadrat. Oleh karena itu, kami akan menggunakan perhitungan yang disederhanakan untuk heuristik.
Mari buat vektor integer:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}Struktur standar untuk menyimpan sepasang koordinat. Di sini kita melihat caching akar kuadrat sehingga dapat dihitung hanya sekali. Antarmuka IEquatable akan memungkinkan kita membandingkan vektor satu sama lain tanpa harus menerjemahkan Vector2Int ke objek dan sebaliknya. Ini akan sangat mempercepat algoritme kami dan menyingkirkan alokasi yang tidak perlu.
DistanceEstimate () digunakan untuk memperkirakan perkiraan jarak ke target dengan menghitung jumlah transisi lurus dan diagonal. Cara alternatif biasa dilakukan:
return Math.Max(Math.Abs(X), Math.Abs(Y))Opsi ini akan bekerja lebih cepat, tetapi ini dikompensasikan dengan keakuratan yang rendah dari perkiraan jarak diagonal.
Sekarang kita memiliki alat untuk bekerja dengan koordinat, mari buat objek yang mewakili bagian atas grafik:
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}Dalam Parent kita akan merekam simpul sebelumnya untuk setiap simpul baru: ini akan membantu dalam membangun jalur terakhir dengan titik. Selain koordinat, kami juga menghemat jarak yang ditempuh dan perkiraan biaya jalur sehingga kami dapat memilih simpul yang paling menjanjikan untuk diproses.
Kelas ini memohon perbaikan, tapi kita akan kembali lagi nanti. Untuk saat ini, mari kembangkan metode yang menghasilkan tetangga dari simpul:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighboursTemplate - template standar untuk membuat tetangga linier dan diagonal dari titik yang diinginkan. Ini juga memperhitungkan peningkatan biaya transisi diagonal.
GenerateNeighbours - Generator yang melintasi NeighboursTemplate dan mengembalikan simpul baru untuk delapan sisi yang berdekatan.
Dimungkinkan untuk mendorong fungsionalitas di dalam PathNode, tetapi rasanya seperti pelanggaran kecil terhadap SRP. Dan saya juga tidak ingin menambahkan fungsionalitas pihak ketiga di dalam algoritme itu sendiri: kami akan menjaga kelas-kelasnya seringkas mungkin.
Saatnya mengatasi kelas pencarian jalan utama!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodes bekerja dengan dua koleksi: frontier, yang berisi antrian simpul untuk analisis, dan ignoredPositions, tempat simpul yang sudah diproses ditambahkan.
Setiap iterasi perulangan menemukan simpul yang paling menjanjikan, memeriksa apakah kita telah mencapai titik akhir, dan menghasilkan tetangga baru untuk simpul ini.
Dan semua keindahan ini cocok menjadi 50 garis.
Itu tetap untuk mengimplementasikan antarmuka:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodes mengembalikan simpul terakhir kepada kita, dan karena kita menulis tetangga orang tua untuk masing-masing, itu cukup untuk berjalan melalui semua orang tua ke simpul awal, dan kita akan mendapatkan jalur terpendek. Semuanya baik-baik saja!
Atau tidak?
Pengoptimalan algoritme
1. PathNode
Mari kita mulai dengan sederhana. Mari sederhanakan PathNode:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}Ini adalah pembungkus data umum yang juga sangat sering dibuat. Tidak ada alasan untuk menjadikannya sebuah kelas dan memuat memori setiap kali kita menulis baru . Oleh karena itu, kami akan menggunakan struct.
Namun ada masalah: struktur tidak dapat berisi referensi melingkar untuk tipenya sendiri. Jadi, alih-alih menyimpan Induk di dalam PathNode, kita membutuhkan cara lain untuk melacak pembangunan jalur antar simpul. Sangat mudah - mari tambahkan koleksi baru ke kelas Path:
private readonly Dictionary<Vector2Int, Vector2Int> links;Dan kami sedikit memodifikasi generasi tetangga:
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}Alih-alih menulis induk ke puncak itu sendiri, kami menulis transisi ke kamus. Sebagai bonus, kamus dapat bekerja secara langsung dengan Vector2Int, dan tidak dengan PathNode, karena kita hanya perlu koordinat dan tidak ada yang lain.
Menghasilkan hasil di dalam Hitung juga disederhanakan:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
Selanjutnya, mari kita berurusan dengan generasi tetangga. IEnumerable, dengan semua manfaatnya, menghasilkan jumlah sampah yang menyedihkan dalam banyak situasi. Mari kita singkirkan:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}Sekarang metode ekstensi kami bukanlah generator: metode ini hanya mengisi buffer yang diteruskan ke sana sebagai argumen. Buffer disimpan sebagai koleksi lain di dalam Path:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];Dan digunakan seperti ini:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
Alih-alih menggunakan Daftar, mari gunakan HashSet:
private readonly HashSet<Vector2Int> ignoredPositions;Jauh lebih efisien saat bekerja dengan koleksi besar, metode ignoredPositions.Contains () sangat intensif sumber daya karena frekuensi panggilan. Perubahan sederhana pada jenis koleksi akan memberikan peningkatan kinerja yang nyata.
4. BinaryHeap
Ada satu tempat dalam implementasi kami yang memperlambat algoritme sepuluh kali lipat:
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);Daftar itu sendiri adalah pilihan yang buruk, dan menggunakan Linq memperburuk keadaan.
Idealnya, kami menginginkan koleksi dengan:
- Penyortiran otomatis.
- Pertumbuhan rendah kompleksitas asimtotik.
- Operasi penyisipan cepat.
- Operasi penghapusan cepat.
- Navigasi yang mudah melalui elemen.
SortedSet mungkin tampak seperti opsi yang bagus, tetapi tidak tahu cara memuat duplikat. Jika kita menulis sortir dengan EstimatedTotalCost, maka semua simpul dengan harga yang sama (tapi koordinat berbeda!) Akan tereliminasi. Di area terbuka dengan sedikit rintangan, hal ini tidak menakutkan, ditambah akan mempercepat algoritme, tetapi di labirin sempit, hasilnya adalah rute yang tidak akurat dan hasil negatif palsu.
Jadi kami menerapkan koleksi kami - tumpukan biner ! Penerapan klasik memenuhi 4 dari 5 persyaratan, dan sedikit modifikasi akan membuat koleksi ini ideal untuk kasus kami.
Collection adalah pohon yang diurutkan sebagian dengan kompleksitas operasi penyisipan dan penghapusan sama dengan log (n) .
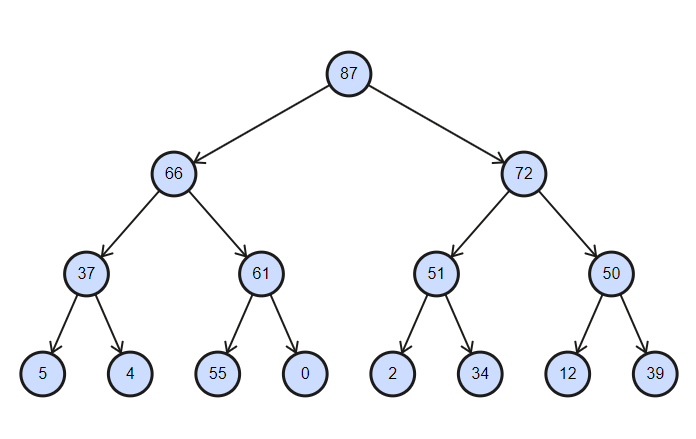
Heap biner diurutkan dalam urutan menurun
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}Mari tulis bagian yang mudah:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}Kami akan menggunakan IComparer untuk penyortiran simpul khusus. IList sebenarnya adalah penyimpanan vertex yang akan kita gunakan. Kita membutuhkan IDictionary untuk melacak indeks simpul untuk penghapusan cepatnya (implementasi standar dari tumpukan biner memungkinkan kita untuk bekerja dengan nyaman hanya dengan elemen teratas).
Mari tambahkan elemen:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}Setiap elemen baru ditambahkan ke sel terakhir dari pohon, setelah itu diurutkan sebagian dari bawah ke atas: menurut simpul dari elemen baru ke akar, hingga elemen terkecil setinggi mungkin. Karena tidak seluruh koleksi diurutkan, tetapi hanya node perantara antara bagian atas dan terakhir, operasi memiliki log kompleksitas (n) .
Mendapatkan sebuah item:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}Dengan analogi dengan menambahkan: elemen root dihilangkan, dan yang terakhir ditempatkan pada tempatnya. Kemudian pengurutan sebagian dari atas ke bawah menukar item sehingga yang terkecil ada di atas.
Setelah itu, kami mengimplementasikan pencarian elemen dan mengubahnya:
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}Tidak ada yang rumit di sini: kami mencari indeks elemen melalui kamus, setelah itu kami mengaksesnya secara langsung.
Versi umum heap:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}Sekarang pencarian jalan kami memiliki kecepatan yang layak, dan hampir tidak ada sampah yang tersisa. Selesai sudah dekat!
5. Koleksi yang dapat digunakan kembali
Algoritme ini dikembangkan dengan memperhatikan kemampuan untuk menyebutnya puluhan kali per detik. Pembuatan sampah apa pun secara kategoris tidak dapat diterima: pengumpul sampah yang dimuat dapat (dan akan!) Menyebabkan penurunan kinerja secara berkala.
Semua koleksi, kecuali untuk output, sudah dideklarasikan satu kali saat kelas dibuat, dan kami akan menempatkan yang terakhir di sana juga:
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}Metode publik mengambil bentuk berikut:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}Dan ini bukan hanya tentang membuat koleksi! Koleksi secara dinamis mengubah kapasitasnya saat diisi; jika jalurnya panjang, pengubahan ukuran akan terjadi puluhan kali. Ini sangat intensif memori. Saat kami menghapus koleksi dan menggunakannya kembali tanpa mendeklarasikan yang baru, kapasitasnya tetap ada. Konstruksi jalur pertama akan menghasilkan banyak sampah saat menginisialisasi koleksi dan mengubah kapasitasnya, tetapi panggilan berikutnya akan berfungsi dengan baik tanpa alokasi apa pun (asalkan panjang setiap jalur yang dihitung plus atau minus sama tanpa distorsi tajam). Oleh karena itu, poin selanjutnya:
6. (Bonus) Pengumuman ukuran koleksi
Sejumlah pertanyaan segera muncul:
- Apakah lebih baik memindahkan beban ke konstruktor kelas Path, atau membiarkannya pada panggilan pertama ke pathfinder?
- Kapasitas apa untuk memberi makan koleksi?
- Apakah lebih murah untuk segera mengumumkan kapasitas yang lebih besar, atau membiarkan koleksinya berkembang sendiri?
Yang ketiga bisa langsung dijawab: jika kita memiliki ratusan dan ribuan sel untuk mencari jalur, pasti akan lebih murah untuk segera menetapkan ukuran tertentu ke koleksi kita.
Dua pertanyaan lainnya lebih sulit untuk dijawab. Jawaban atas pertanyaan ini perlu ditentukan secara empiris untuk setiap kasus penggunaan. Jika kita masih memutuskan untuk memindahkan beban ke konstruktor, maka inilah waktunya untuk menambahkan batas jumlah langkah ke algoritma kita:
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}Di dalam GenerateNodes, perbaiki loop:
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}Jadi, koleksi segera diberi kapasitas yang sama dengan jalur maksimum. Beberapa koleksi tidak hanya berisi node yang dilintasi, tetapi juga tetangganya: untuk koleksi tersebut, Anda dapat menggunakan kapasitas 4-5 kali lebih besar dari yang ditentukan.
Ini mungkin tampak terlalu berlebihan, tetapi untuk jalur yang mendekati maksimum yang dinyatakan, penetapan ukuran koleksi menghabiskan setengah hingga tiga kali lebih sedikit memori daripada ekspansi dinamis. Di sisi lain, jika Anda menetapkan nilai yang sangat besar ke nilai maxSteps dan menghasilkan jalur pendek, inovasi seperti itu hanya akan merugikan. Oh, dan Anda sebaiknya tidak mencoba menggunakan int.MaxValue!
Solusi optimal adalah membuat dua konstruktor, salah satunya menetapkan kapasitas awal koleksi. Kemudian kelas kita dapat digunakan dalam kedua kasus tersebut tanpa mengubahnya.
Apa lagi yang bisa kamu lakukan?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- Ubah tanda tangan metode di antarmuka kami untuk lebih mencerminkan esensinya:
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
Jadi, metode tersebut dengan jelas menunjukkan logika operasinya, sedangkan metode aslinya seharusnya dipanggil seperti ini: CalculateOrReturnEmpty .
Versi terakhir dari kelas Path:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}Tautan ke kode sumber