Baru-baru ini, kolega di "toko" secara mandiri mulai bertanya kepada saya: bagaimana cara mendapatkan semua saluran Bluetooth dari satu penerima SDR secara bersamaan? Bandwidth memungkinkan, ada SDR dengan bandwidth keluaran 80 MHz atau lebih. Anda tentu saja dapat melakukannya di FPGA, tetapi waktu pengembangannya akan cukup lama. Saya sudah tahu sejak lama bahwa cukup mudah melakukan ini dengan GPU, tapi hanya itu!
Standar Bluetooth mendefinisikan lapisan fisik dalam dua versi: Klasik dan Hemat Energi. Spesifikasinya ada di sini . Dokumen itu sangat besar; membacanya secara keseluruhan berbahaya bagi otak. Untungnya, perusahaan instrumentasi besar memiliki sarana untuk membuat dokumen visual tentang suatu topik. Tektronix dan Instrumen Nasional , misalnya. Saya sama sekali tidak memiliki peluang untuk bersaing dengan mereka dalam hal kualitas penyajian materi. Jika Anda tertarik, silakan ikuti tautannya.
Yang perlu saya ketahui tentang lapisan fisik untuk membuat filter multisaluran adalah langkah grid frekuensi dan tingkat modulasi. Mereka ditabulasi di salah satu dokumen yang ditentukan:
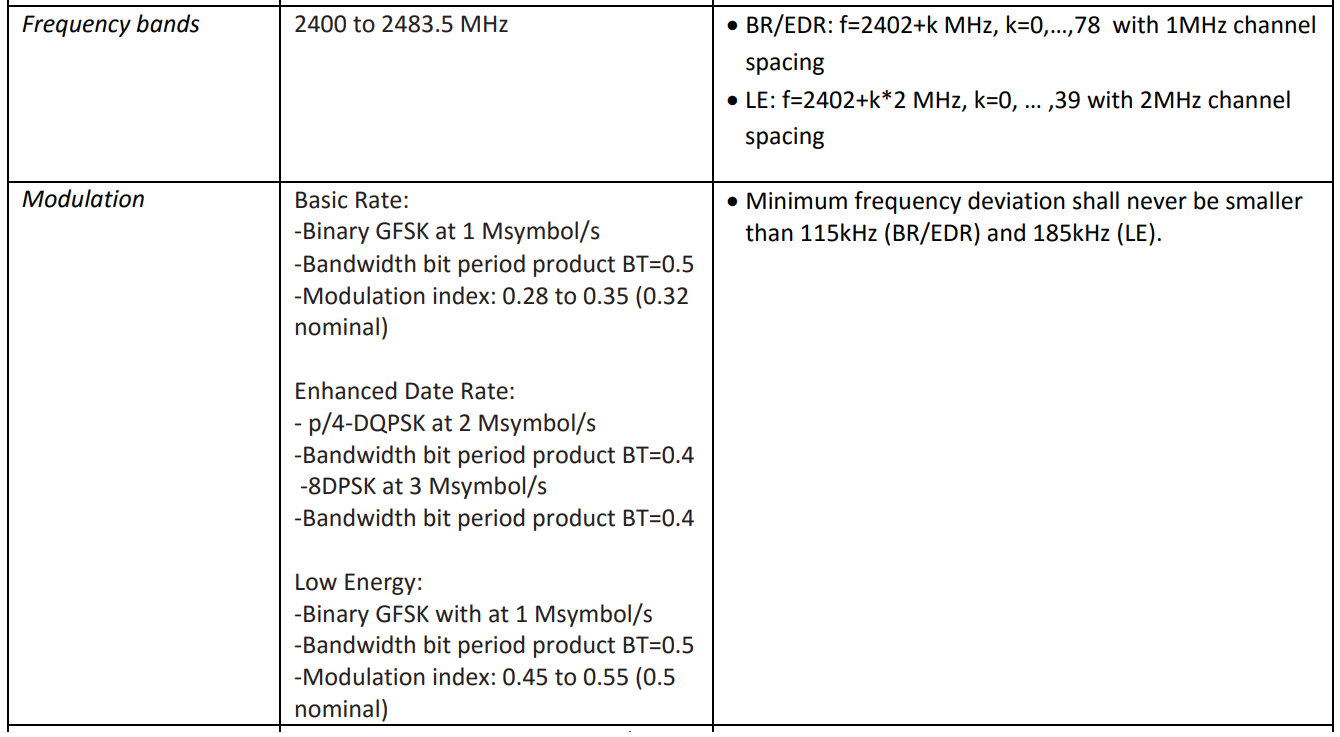
, 80 79 1 , , 40 2 . 1 2 , .
, .
Bluetooth Classic Bluetooth Low Energy. , . , "" . . , .
1 ( ) 500 , 480 . 2 1 240 , . . filterDesigner -header:
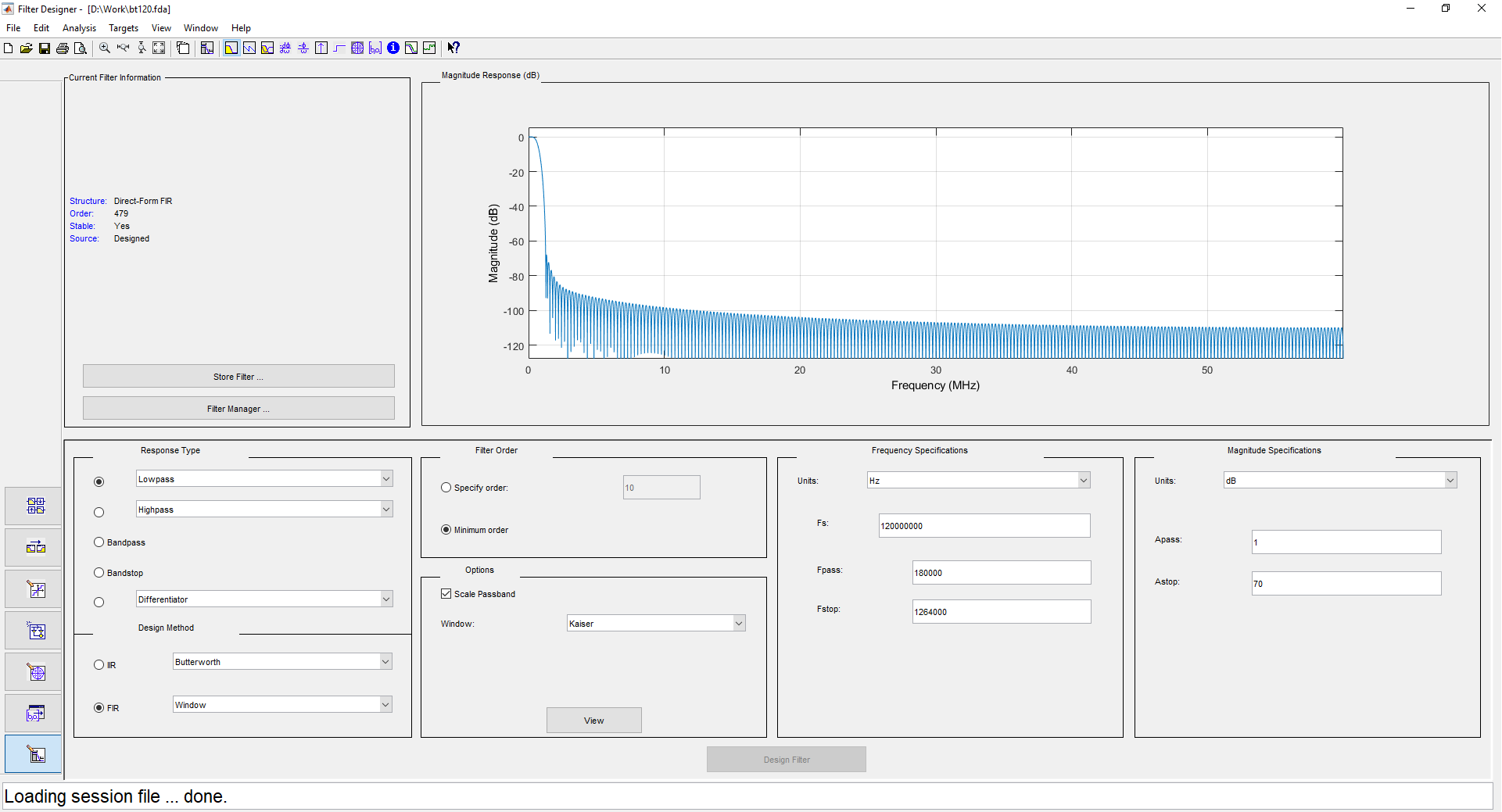
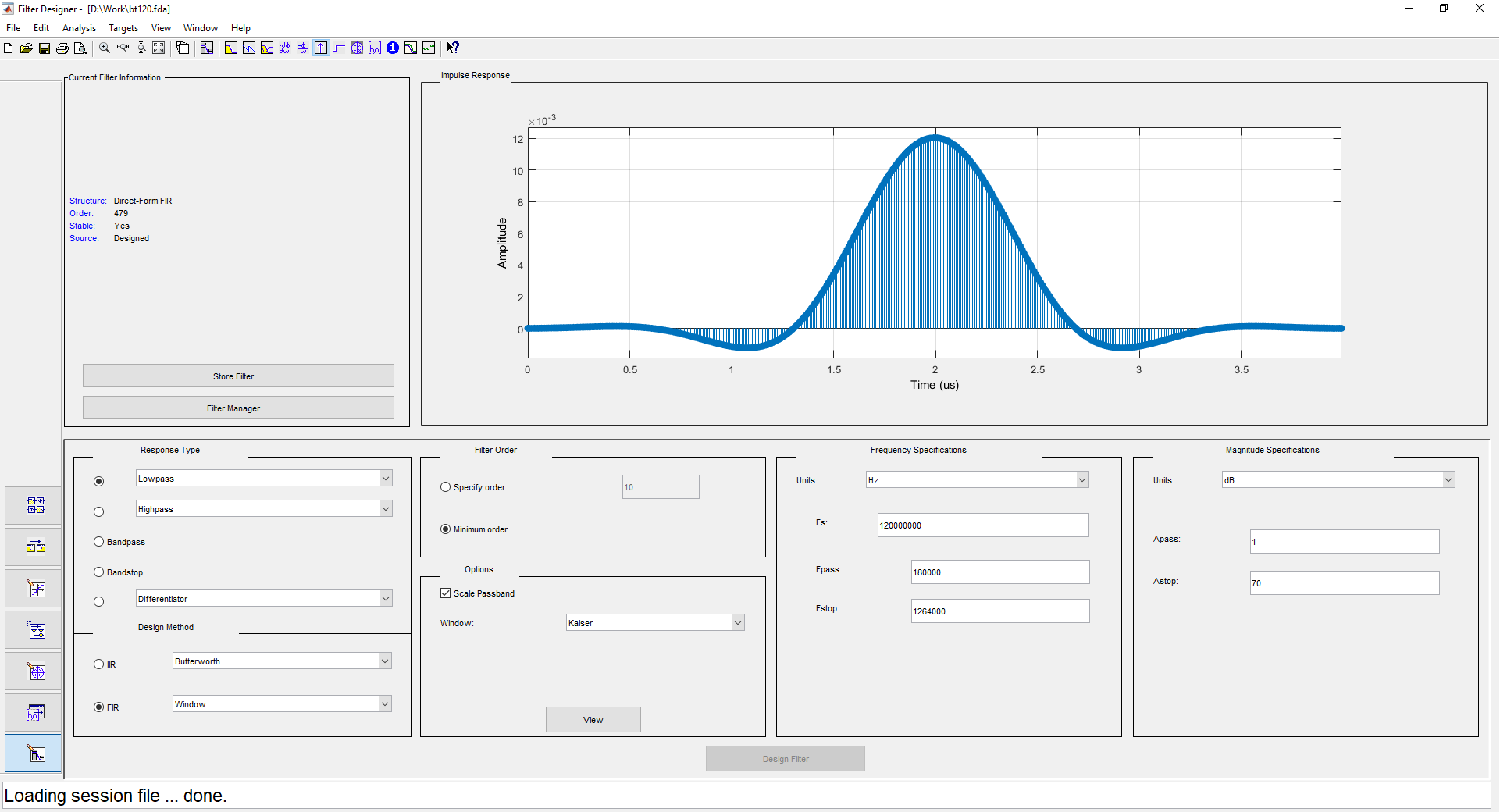
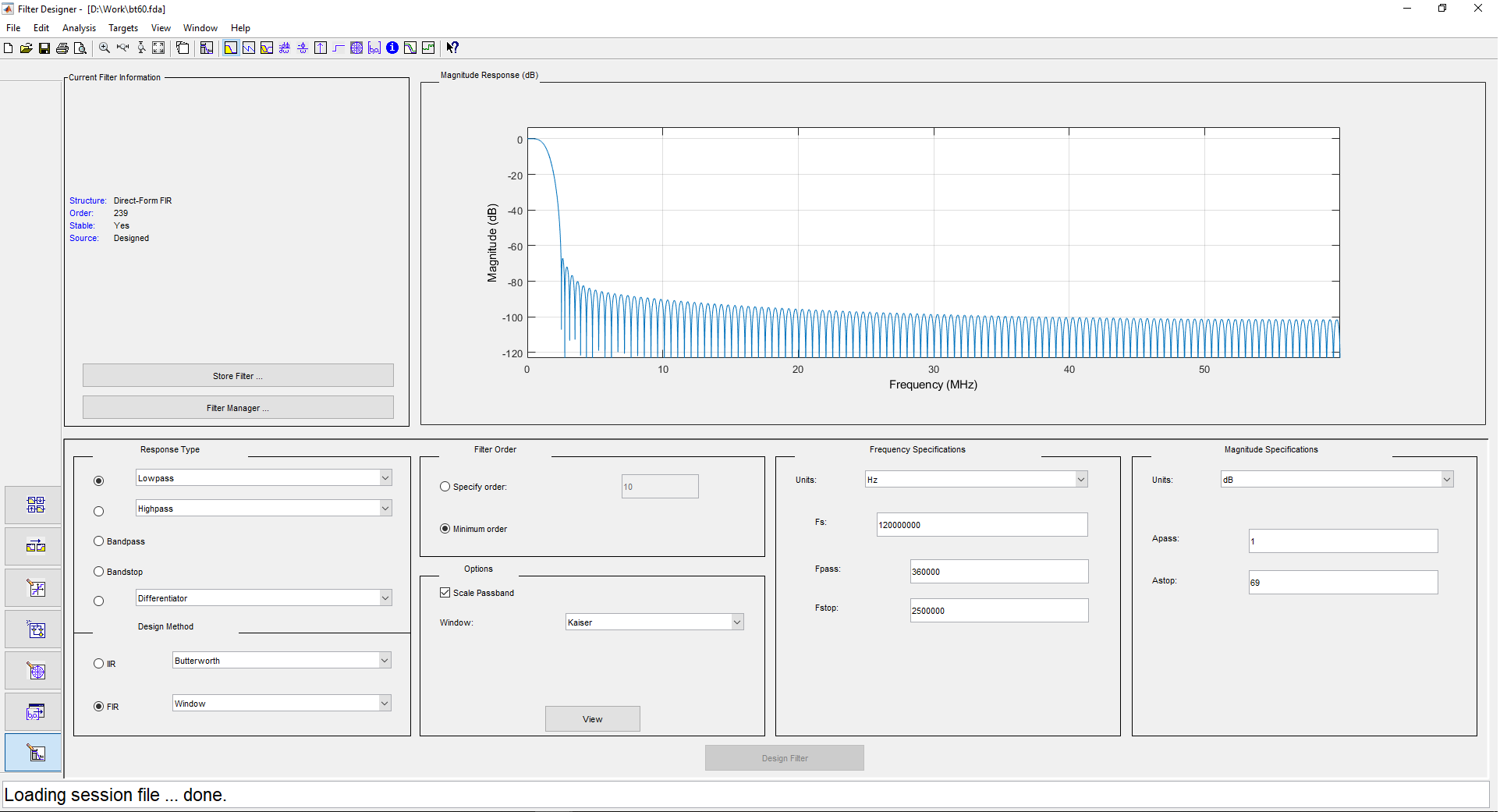
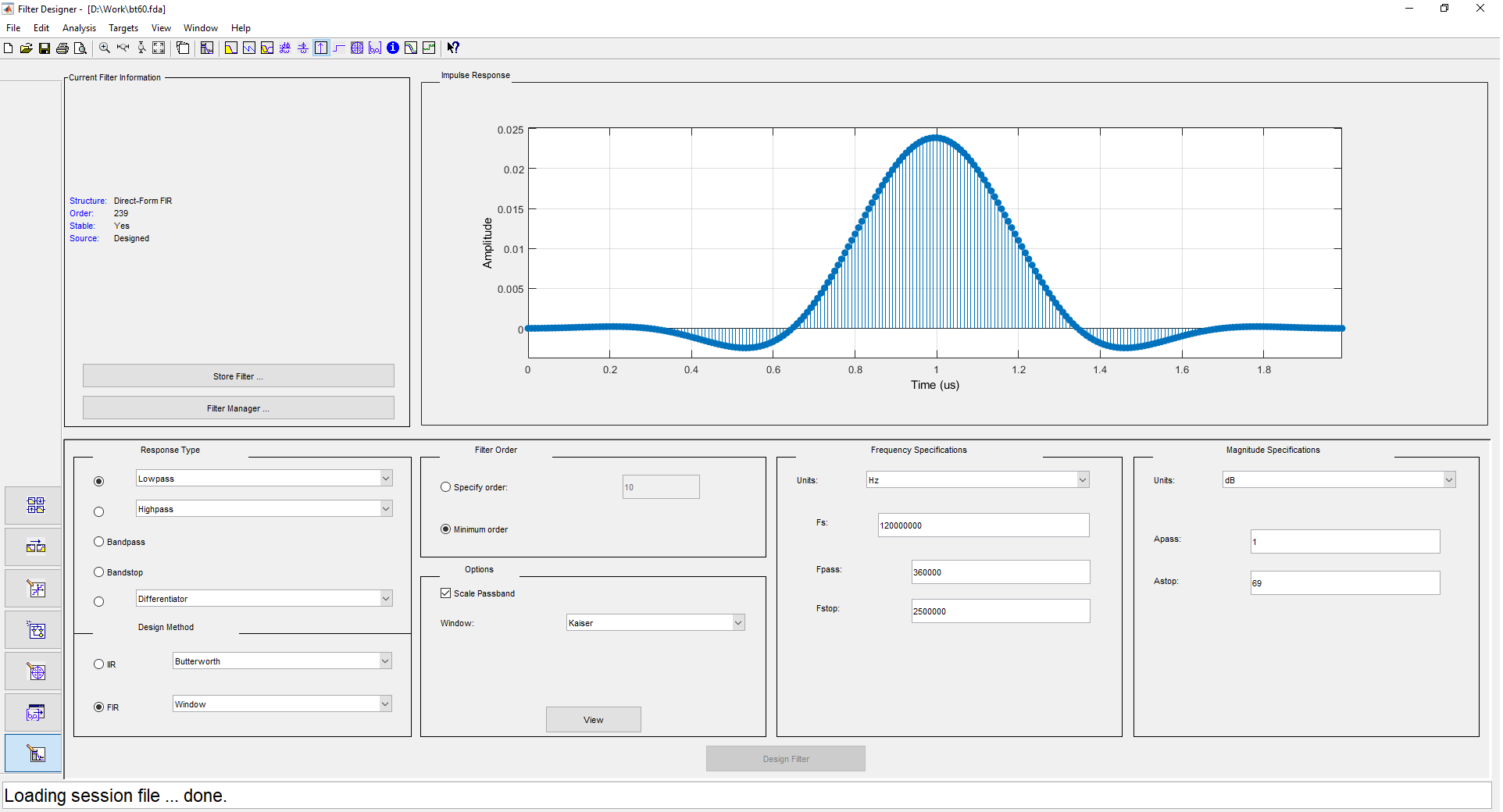
: DDC (Digital Down Converter). , . — - . .
GPU : , CUDA . Polyphase or WOLA (Weight, Overlap and Add) FFT Filterbank. . , 11 ( ), :
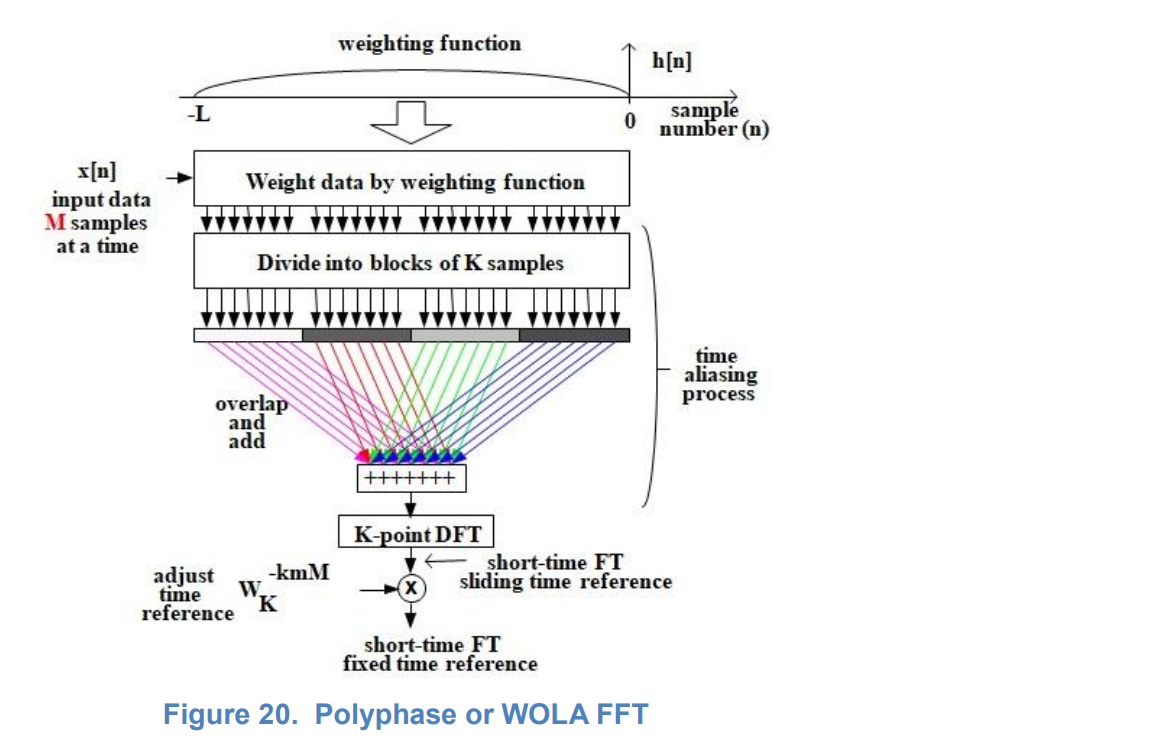
. , . , , . , . , , . . , ( ), . , . , , ,
, , .
, . " " FMC126P. . FMC AD9371 100 . .
- GPU GTX 1050. (, : , , ). .
, - . GPU. , .
, , :
__global__ void cuComplexMultiplyWindowKernel(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result) {
__shared__ cuComplex multiplicationResult[480];
multiplicationResult[threadIdx.x] = cuComplexMultiplyFloat(data[threadIdx.x + windowSize / 4 * blockIdx.x], window[threadIdx.x]);
__syncthreads();
cuComplex sum;
sum.x = sum.y = 0;
if (threadIdx.x < windowSize / 4) {
for(int i = 0; i < 4; i++) {
sum = cuComplexAdd(sum, multiplicationResult[threadIdx.x + i * windowSize / 4]);
}
result[threadIdx.x + windowSize / 4 * blockIdx.x] = sum;
}
}
cudaError_t cuComplexMultiplyWindow(const cuComplex *data, const float *window, size_t windowSize, cuComplex *result, size_t dataSize, cudaStream_t stream) {
size_t windowStep = windowSize / 4;
cuComplexMultiplyWindowKernel<<<dataSize / windowStep - 3, windowSize, 1024, stream>>>(data, window, windowSize, result);
return cudaGetLastError();
}
, , , , .
. AD9371 2450 , .
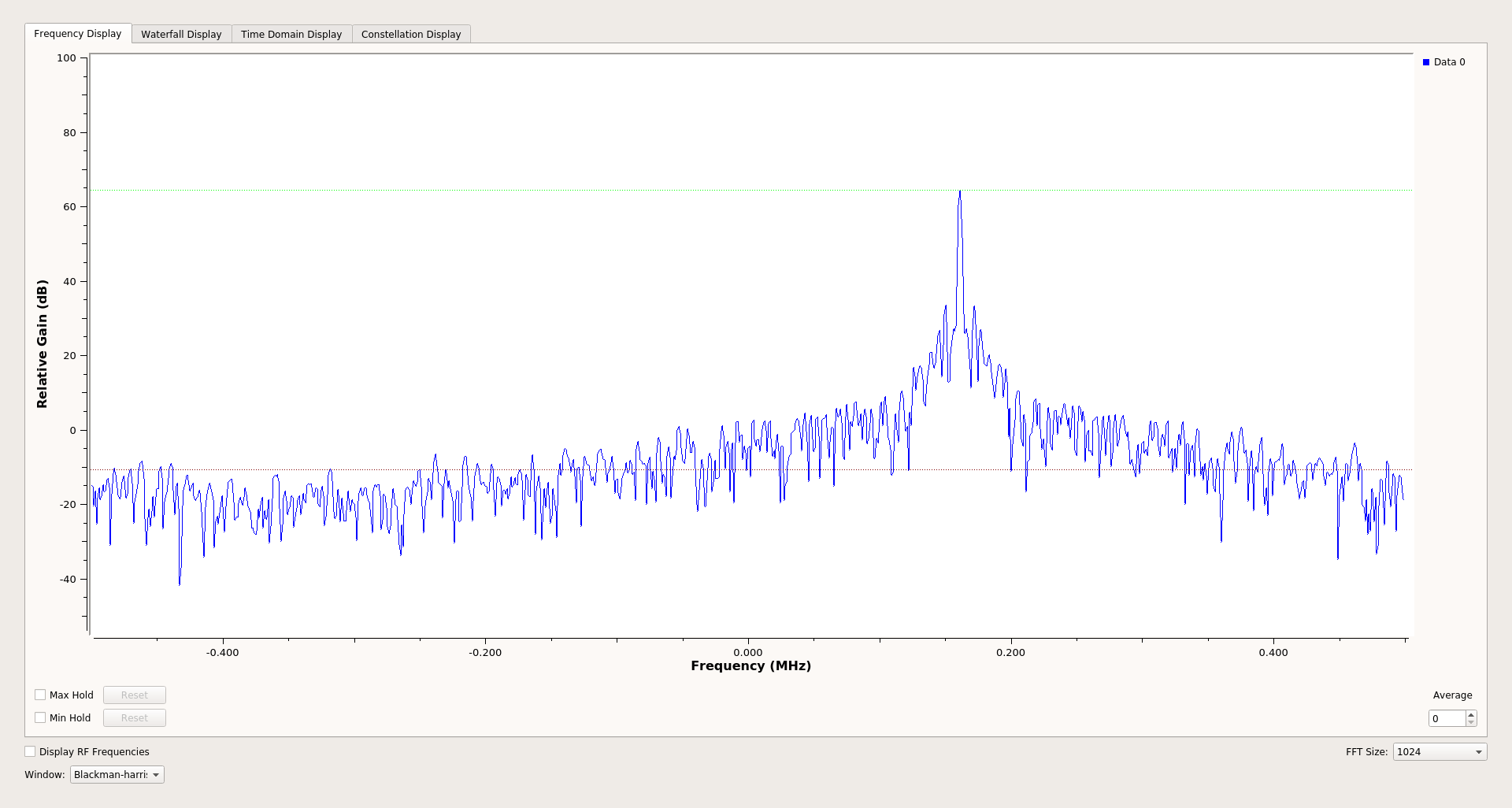
: XRTX , - .
gaudima, !