
Halo! Perusahaan kami telah lama menangani masalah perlindungan terhadap serangan DDoS, dan dalam proses pekerjaan ini saya dapat berkenalan dengan area terkait dengan cukup detail - untuk mempelajari prinsip-prinsip pembuatan bot dan cara menggunakannya. Secara khusus, web scraping, yaitu pengumpulan data publik secara massal dari sumber daya web menggunakan bot.
Pada titik tertentu, topik ini membuat saya terpesona dengan berbagai masalah terapan di mana pengikisan berhasil digunakan. Perlu dicatat di sini bahwa "sisi gelap" dari pengikisan web adalah yang paling menarik bagi saya, yaitu, skenario berbahaya dan buruk untuk penggunaannya dan dampak negatif yang dapat ditimbulkannya pada sumber daya web dan bisnis yang terkait dengannya.
Pada saat yang sama, karena spesifikasi pekerjaan kami, paling sering dalam kasus (buruk) seperti itulah kami harus membenamkan diri secara mendetail, mempelajari detail yang menarik. Dan hasil dari penyelaman ini adalah antusiasme saya diteruskan kepada rekan-rekan saya - kami menerapkan solusi kami untuk menangkap bot yang tidak diinginkan, tetapi saya telah mengumpulkan cukup banyak cerita dan pengamatan yang, semoga, menjadi materi yang menarik bagi Anda.

Saya akan berbicara tentang hal berikut:
- Mengapa orang-orang saling menggaruk;
- Apa jenis dan tanda dari kerokan tersebut;
- Apa dampaknya pada situs web yang ditargetkan;
- Alat dan kemampuan teknis apa yang digunakan pembuat bot untuk melakukan scraping;
- Bagaimana berbagai kategori bot dapat dideteksi dan dikenali;
- Apa yang harus dilakukan dan apa yang harus dilakukan jika pengikis datang mengunjungi situs Anda (dan apakah Anda perlu melakukan sesuatu sama sekali).
Mari kita mulai dengan skenario hipotetis yang tidak berbahaya - mari kita bayangkan Anda adalah seorang siswa, besok pagi Anda memiliki pembelaan atas makalah Anda, Anda tidak memiliki kuda berserakan berdasarkan materi, tidak ada angka, tidak ada kutipan, tidak ada kutipan - dan Anda memahami bahwa sepanjang sisa malam Anda tidak memiliki waktu, tenaga, atau keinginan untuk menjelajahi seluruh basis pengetahuan ini secara manual.
Oleh karena itu, atas saran rekan-rekan yang lebih tua, Anda menemukan baris perintah Python dan menulis skrip sederhana yang menerima URL sebagai input, masuk ke sana, memuat halaman, mengurai konten, menemukan kata kunci, blok atau jumlah yang menarik di dalamnya, menambahkannya ke dalam file, atau ke piring dan melanjutkan.
Muat dalam skrip ini jumlah alamat yang diperlukan untuk publikasi ilmiah, publikasi online, sumber berita - semuanya dengan cepat membahas semuanya, menambahkan hasil. Anda hanya perlu menggambar grafik dan diagram, tabel di atasnya - dan keesokan paginya, dengan penampilan pemenang, Anda mendapatkan poin yang memang pantas Anda dapatkan.
Mari kita pikirkan - apakah Anda melakukan sesuatu dengan buruk dalam prosesnya? Nah, kecuali Anda mengurai HTML dengan ekspresi reguler, maka kemungkinan besar Anda tidak merugikan siapa pun, dan terlebih lagi ke situs-situs yang Anda kunjungi dengan cara ini. Ini adalah kegiatan satu kali, dapat disebut sederhana dan tidak mencolok, dan hampir tidak ada yang terluka oleh fakta bahwa Anda datang dengan cepat dan diam-diam mengambil bagian data yang Anda butuhkan.
Di sisi lain, apakah Anda akan melakukannya lagi jika semuanya berhasil pada kali pertama? Mari kita hadapi itu - kemungkinan besar Anda akan melakukannya, karena Anda baru saja menghemat banyak waktu dan sumber daya, setelah menerima, kemungkinan besar, bahkan lebih banyak data daripada yang Anda duga. Dan ini tidak terbatas pada penelitian ilmiah, akademis atau pendidikan umum.

Karena informasi membutuhkan uang, dan informasi yang dikumpulkan pada waktu membutuhkan lebih banyak uang. Itulah mengapa scraping merupakan sumber pendapatan yang serius bagi banyak orang. Ini adalah topik freelance yang populer: masuk dan lihat banyak pesanan yang meminta Anda untuk mengumpulkan beberapa data atau menulis software scraping. Ada juga organisasi komersial yang melakukan scraping untuk memesan atau menyediakan platform untuk aktivitas ini, yang disebut scraping as a service. Variasi dan penyebaran seperti itu dimungkinkan, juga karena mengikis itu sendiri adalah sesuatu yang ilegal, tercela, bukan. Dari segi hukum, sangat sulit mencari-cari kesalahannya - apalagi saat ini kita akan segera mengetahui alasannya.

Bagi saya, yang menarik adalah fakta bahwa secara teknis, tidak ada yang dapat melarang Anda untuk melawan gesekan - ini menciptakan situasi yang menarik di mana para peserta dalam proses di kedua sisi barikade memiliki kesempatan di ruang publik untuk membahas aspek teknis dan organisasi dari masalah ini. Untuk bergerak maju, sampai batas tertentu, rekayasa memikirkan dan melibatkan lebih banyak orang dalam proses ini.

Dari segi hukum, keadaan yang sekarang kita pertimbangkan - dengan dibolehkannya penggarukan, tidak selalu sama sebelumnya. Jika kita melihat sedikit kronologi tuntutan hukum yang cukup terkenal terkait dengan scraping, kita akan melihat bahwa bahkan pada awal fajarnya, klaim pertama eBay adalah melawan scraper yang mengumpulkan data dari lelang, dan pengadilan melarangnya untuk terlibat dalam aktivitas ini. Selama 15 tahun berikutnya, status quo kurang lebih dipertahankan - perusahaan besar memenangkan tuntutan hukum terhadap pencakar ketika mereka menemukan dampaknya. Facebook dan Craigslist, serta beberapa perusahaan lain, telah melaporkan klaim yang berakhir dengan keuntungan mereka.
Namun, setahun lalu, semuanya tiba-tiba berubah. Pengadilan menemukan bahwa klaim LinkedIn terhadap perusahaan yang mengumpulkan profil publik pengguna dan resume tidak berdasar dan mengabaikan surat dan ancaman yang menuntut untuk menghentikan aktivitas tersebut. Pengadilan memutuskan bahwa pengumpulan data publik, terlepas dari apakah itu bot atau manusia, tidak dapat menjadi dasar klaim dari perusahaan yang menampilkan data publik ini. Preseden hukum yang kuat ini telah mengubah keseimbangan yang mendukung pencakar dan telah memungkinkan lebih banyak orang untuk menunjukkan, mendemonstrasikan, dan mencoba minat mereka sendiri di bidang ini.
Namun, melihat semua hal yang umumnya tidak berbahaya ini, jangan lupa bahwa scraping memiliki banyak kegunaan negatif - ketika data dikumpulkan tidak hanya untuk digunakan lebih lanjut, tetapi dalam prosesnya, gagasan untuk menyebabkan kerusakan pada situs atau bisnis di baliknya terwujud. atau mencoba untuk memperkaya diri dengan cara tertentu dengan mengorbankan pengguna sumber daya target.
Mari kita lihat beberapa contoh ikonik.

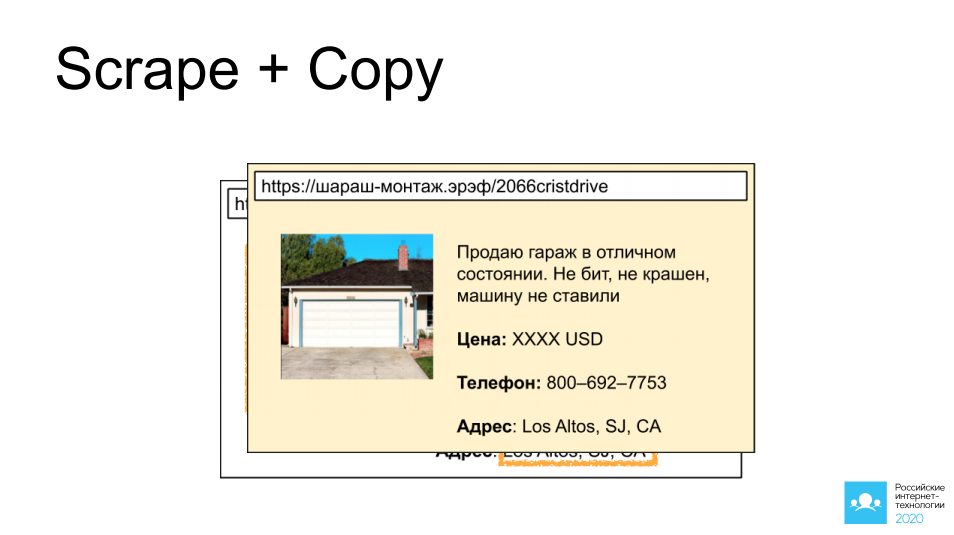
Yang pertama adalah menyalin dan menyalin iklan orang lain dari situs yang menyediakan akses ke iklan tersebut: mobil, real estat, barang pribadi. Saya memilih garasi yang indah di California sebagai contoh. Bayangkan kita memasang bot di sana, mengumpulkan gambar, mengumpulkan deskripsi, mengambil semua informasi kontak, dan setelah 5 menit, iklan yang sama tergantung di situs lain dengan fokus yang sama, dan sangat mungkin terjadi kesepakatan yang menguntungkan melaluinya.
Jika kita menghidupkan imajinasi kita sedikit di sini dan berpikir ke sisi berikutnya - bagaimana jika bukan pesaing kita yang melakukan ini, tetapi penyerang? Salinan situs semacam itu bisa sangat berguna untuk, misalnya, meminta pembayaran di muka dari pengunjung, atau sekadar menawarkan untuk memasukkan detail kartu pembayaran. Anda dapat membayangkan sendiri perkembangan peristiwa lebih lanjut.
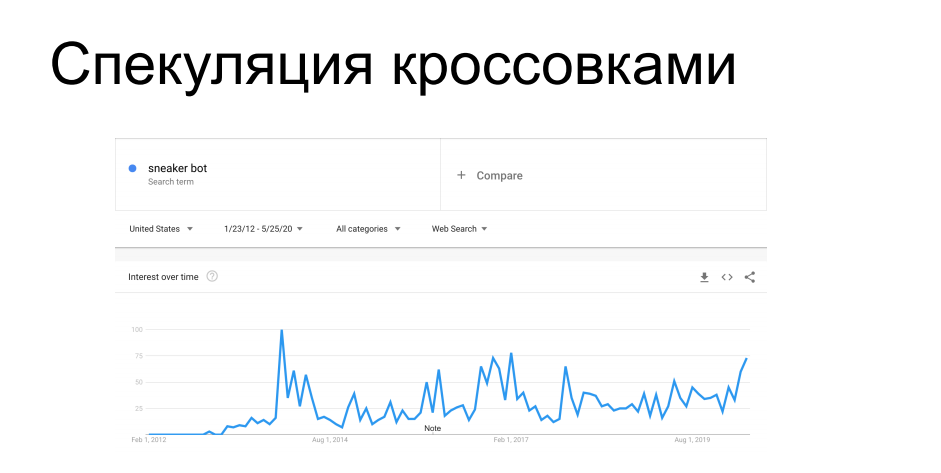
Kasus menarik lainnya yang menarik adalah pembelian barang dengan ketersediaan terbatas. Produsen sepatu atletik seperti Nike, Puma, dan Reebok secara berkala meluncurkan sneakers edisi terbatas, dll. seri tanda tangan - mereka diburu oleh kolektor, dijual untuk waktu yang terbatas. Di depan pembeli, bot datang ke situs web toko sepatu dan meraup seluruh sirkulasi, setelah itu sepatu kets ini melayang ke pasar abu-abu dengan label harga yang sangat berbeda. Pada suatu waktu, hal itu membuat marah vendor dan pengecer yang mendistribusikannya. Selama 7 tahun mereka telah berjuang melawan pencakar dan apa yang disebut. bot sneaker dengan berbagai keberhasilan, baik metode teknis maupun administratif.

Anda mungkin pernah mendengar cerita ketika berbelanja online diharuskan datang ke toko sepatu secara langsung, atau tentang honeypots dengan sepatu kets seharga $ 100k, yang dibeli bot tanpa melihat, setelah itu pemiliknya meraih kepalanya - semua cerita ini ada dalam tren ini.
Dan kasus serupa lainnya adalah menipisnya persediaan di toko online. Ini mirip dengan yang sebelumnya, tetapi sebenarnya tidak ada pembelian yang dilakukan di dalamnya. Ada toko online, dan barang-barang tertentu yang disapu oleh bot yang masuk ke dalam keranjang dalam jumlah yang ditampilkan seperti yang tersedia di gudang. Akibatnya, pengguna sah yang mencoba membeli produk menerima pesan bahwa artikel ini sudah habis, menggaruk bagian belakang kepalanya dengan frustrasi dan pergi ke toko lain. Bot itu sendiri kemudian menjatuhkan keranjang yang terkumpul, barang dikembalikan ke kolam - dan orang yang membutuhkannya datang dan memesan. Atau tidak datang dan tidak memesan, jika ini adalah skenario kerusakan kecil dan hooliganisme. Dari sini jelas bahwa bahkan jika kegiatan seperti itu tidak menyebabkan kerugian finansial langsung pada bisnis online, setidaknya dapat mengganggu metrik bisnis secara serius,yang akan menjadi fokus analis. Parameter seperti konversi, kehadiran, permintaan produk, cek keranjang rata-rata - semuanya akan sangat ternoda oleh tindakan bot dalam kaitannya dengan item ini. Dan sebelum metrik ini digunakan, metrik tersebut harus dibersihkan dengan hati-hati dan susah payah dari efek pengikis.
Selain fokus bisnis tersebut, ada efek teknis yang cukup mencolok yang timbul dari pekerjaan pengikis - paling sering saat pengikisan dilakukan secara aktif dan intensif.
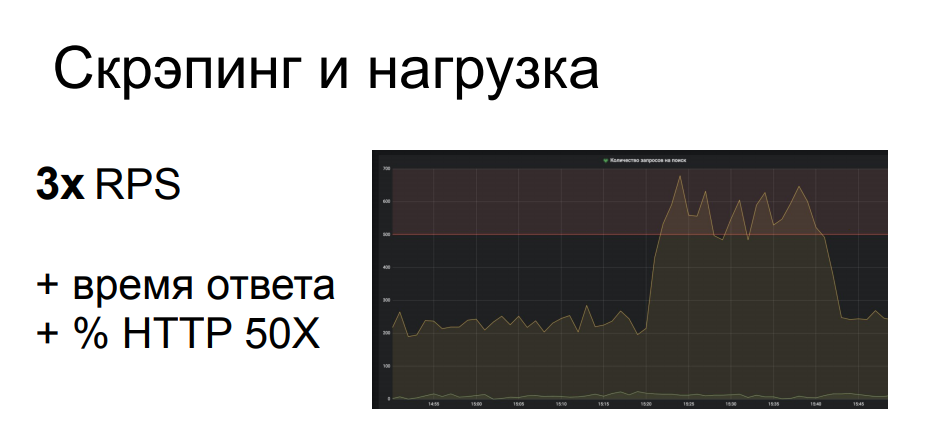
Salah satu contoh kami dari salah satu klien kami. Pengikis datang ke lokasi dengan pencarian berparameter, yang merupakan salah satu operasi tersulit di bagian belakang struktur yang dimaksud. Pengikis harus melalui banyak permintaan pencarian, dan dia menghasilkan hampir 700 dari 200 RPS ke lokasi ini. Hal ini secara serius memuat bagian dari infrastruktur, yang menyebabkan penurunan kualitas layanan untuk pengguna yang sah lainnya, waktu respon lepas landas, 502 dan 503 jatuh. dan kesalahan. Secara umum, pengikis tidak peduli sama sekali dan dia duduk dan melakukan pekerjaannya sementara orang lain dengan panik menyegarkan halaman browser.
Dari sini jelas bahwa aktivitas tersebut dapat diklasifikasikan sebagai serangan DDoS terapan - dan seringkali memang demikian. Apalagi jika toko online tidak begitu besar, tidak memiliki infrastruktur yang berulang kali dicadangkan dalam hal kinerja dan lokasi. Aktivitas seperti itu mungkin saja, jika Anda tidak sepenuhnya menempatkan sumber daya - itu tidak terlalu menguntungkan bagi pengikis, karena dalam hal ini dia tidak akan menerima datanya - kemudian membuat semua pengguna lain sangat kesal.
Tapi selain DDoS, scraping juga memiliki tetangga cybercrime yang menarik. Sebagai contoh, login dan password brute force menggunakan dasar teknis yang serupa, yaitu dengan menggunakan script yang sama, hal itu dapat dilakukan dengan mengutamakan kecepatan dan performa. Untuk penjejalan kredensial, data pengguna yang dihapus dari suatu tempat digunakan, yang didorong ke kolom formulir. Nah, contoh menyalin konten dan mempostingnya di situs serupa adalah pekerjaan persiapan yang serius untuk menyelipkan tautan phishing dan memikat pembeli yang tidak menaruh curiga.

Untuk memahami bagaimana varian scraping yang berbeda, dari sudut pandang teknis, memengaruhi sumber daya, mari kita coba menghitung kontribusi faktor individu untuk tugas ini. Mari kita berhitung.

Katakanlah kita memiliki banyak data di sebelah kanan yang perlu kita kumpulkan. Kami memiliki tugas atau perintah untuk mengambil 10.000.000 baris item komoditas, misalnya label harga atau kutipan. Dan di sisi kiri kami memiliki anggaran waktu, karena besok atau dalam seminggu data ini tidak lagi dibutuhkan oleh pelanggan - data akan menjadi usang dan harus dikumpulkan lagi. Oleh karena itu, Anda perlu menjaga dalam jangka waktu tertentu dan, dengan menggunakan sumber daya Anda sendiri, melakukannya dengan cara yang optimal. Kami memiliki sejumlah server - mesin dan alamat IP di mana mereka berada, dari mana kami akan pergi ke sumber daya yang menarik bagi kami. Kami memiliki sejumlah contoh pengguna yang kami pura-pura - ada tugas untuk meyakinkan toko online atau beberapa basis publik bahwa ini adalah orang yang berbeda atau komputer yang berbeda mencari beberapa jenis data sehingga mereka yangsiapa yang akan menganalisis log, tidak ada kecurigaan. Dan kami memiliki beberapa kinerja, tingkat permintaan, dari satu contoh tersebut.
Jelas bahwa dalam kasus sederhana - satu mesin host, seorang siswa dengan laptop, melalui Washington Post, sejumlah besar permintaan dengan tanda dan parameter yang sama akan dibuat. Ini akan sangat terlihat di log jika ada banyak permintaan seperti itu - yang berarti mudah untuk menemukan dan melarang, dalam hal ini, berdasarkan alamat IP.
Ketika infrastruktur scraping menjadi lebih kompleks, sejumlah besar alamat IP muncul, proxy mulai digunakan, termasuk proxy rumah - tentang mereka nanti. Dan kami mulai membuat multi-instantiate pada setiap mesin - untuk mengganti parameter kueri, tanda-tanda yang menjadi ciri kami, untuk membuat semuanya tercoreng di log dan tidak terlalu mencolok.
Jika kita melanjutkan ke arah yang sama, maka kita memiliki kesempatan, dalam kerangka persamaan yang sama, untuk mengurangi intensitas permintaan dari setiap contoh tersebut - menjadikannya lebih jarang, memutarnya dengan lebih efisien sehingga permintaan dari pengguna yang sama tidak berakhir di log terdekat. tanpa menimbulkan kecurigaan dan menjadi serupa dengan pengguna akhir (sah).
Nah, ada kasus tepi - kami pernah memiliki kasus seperti itu dalam praktiknya, ketika pengikis datang ke pelanggan dari sejumlah besar alamat IP dengan atribut pengguna yang sangat berbeda di belakang alamat ini, dan setiap contoh tersebut membuat satu permintaan untuk konten. Saya membuat GET ke halaman produk yang diinginkan, menguraikannya dan meninggalkannya - dan tidak pernah muncul lagi. Kasus seperti itu sangat jarang, karena membutuhkan lebih banyak sumber daya (yang membutuhkan biaya) untuk terlibat dalam jumlah waktu yang sama. Tetapi pada saat yang sama, menjadi jauh lebih sulit untuk melacak mereka dan memahami bahwa seseorang bahkan datang ke sini dan mengoreknya. Alat penelitian lalu lintas seperti analisis perilaku - membangun pola perilaku pengguna tertentu - menjadi sangat rumit. Lagi pula, bagaimana Anda bisa melakukan analisis perilaku jika tidak ada perilaku? Tidak ada riwayat tindakan pengguna,dia belum pernah muncul sebelumnya, dan, yang menarik, dia tidak pernah datang lagi sejak saat itu. Dalam kondisi seperti itu, jika kami tidak mencoba melakukan sesuatu pada permintaan pertama, maka itu akan menerima datanya dan pergi, dan kami tidak akan punya apa-apa - kami belum menyelesaikan masalah melawan gesekan di sini. Oleh karena itu, satu-satunya kesempatan adalah menebak permintaan pertama bahwa orang yang salah telah datang, yang ingin kita lihat di situs, dan memberinya kesalahan atau memastikan bahwa dia tidak menerima datanya.yang ingin kami lihat di situs, dan memberikan kesalahan atau memastikan bahwa dia tidak menerima datanya.yang ingin kami lihat di situs, dan memberikan kesalahan atau memastikan bahwa dia tidak menerima datanya.
Untuk memahami bagaimana Anda dapat bergerak sepanjang skala kompleksitas ini dalam membuat scraper, mari kita lihat gudang senjata yang dimiliki pembuat bot yang paling sering digunakan - dan kategori apa yang dapat dibagi.

Kategori utama dan paling sederhana yang paling dikenal oleh sebagian besar pembaca adalah scraping skrip, penggunaan skrip yang cukup sederhana untuk memecahkan masalah yang relatif kompleks.

Dan kategori ini mungkin yang paling populer dan terdokumentasi dengan baik. Bahkan sulit untuk merekomendasikan apa sebenarnya yang harus dibaca, karena pada kenyataannya bahannya sangat banyak. Banyak sekali buku yang telah ditulis dengan cara ini, ada banyak artikel dan publikasi - pada prinsipnya cukup menghabiskan 5/4/3/2 menit (tergantung kelancangan penulis materi) untuk mengurai situs pertama anda. Ini adalah langkah pertama yang logis bagi banyak orang yang memulai web scraping. "Paket awal" dari aktivitas semacam itu paling sering adalah Python, ditambah pustaka yang dapat membuat permintaan secara fleksibel dan mengubah parameternya, seperti permintaan atau urllib2. Dan semacam parser HTML, paling sering Beautiful Soup. Ada juga opsi untuk menggunakan lib yang dibuat khusus untuk scrapy, seperti scrapy, yang menyertakan semua fungsionalitas ini dengan antarmuka yang ramah pengguna.
Dengan bantuan trik sederhana, Anda dapat berpura-pura menjadi perangkat yang berbeda, pengguna yang berbeda, bahkan tanpa dapat mengukur aktivitas Anda berdasarkan mesin, alamat IP, dan platform perangkat keras yang berbeda.

Untuk menghilangkan aroma orang yang memeriksa log di sisi server tempat data dikumpulkan, itu cukup untuk mengganti parameter yang menarik - dan ini tidak sulit dan tidak lama. Mari kita lihat contoh format log khusus untuk nginx - kami mencatat alamat IP, informasi TLS, header yang menarik bagi kami. Di sini, tentu saja, tidak semua yang biasanya dikumpulkan, tetapi kita memerlukan batasan ini sebagai contoh - untuk melihat subset, hanya karena yang lainnya lebih mudah untuk "dilempar".
Agar tidak diblokir oleh alamat, kami akan menggunakan proxy tempat tinggal, sebagaimana mereka disebut di luar negeri - yaitu, proxy dari mesin yang disewa (atau diretas) di jaringan penyedia rumah. Jelas bahwa dengan melarang alamat IP seperti itu, ada kemungkinan untuk melarang sejumlah pengguna yang tinggal di rumah-rumah ini - dan mungkin ada pengunjung ke situs Anda, jadi terkadang lebih mahal bagi Anda untuk melakukan ini.
Informasi TLS juga tidak sulit untuk diubah - gunakan cipher suite dari browser populer dan pilih salah satu yang Anda suka - yang paling umum, atau putar secara berkala untuk menampilkan dirinya sebagai perangkat yang berbeda.
Sedangkan untuk tajuk, dengan bantuan studi kecil, Anda dapat mengatur perujuk ke apa pun yang disukai situs salinan, dan kami mengambil agen pengguna dari Chrome, atau Firefox, sehingga tidak berbeda dengan cara apa pun dari puluhan ribu pengguna lainnya.
Kemudian, dengan menyulap parameter ini, Anda dapat berpura-pura menjadi perangkat yang berbeda dan terus mengikis tanpa takut terlihat mata telanjang berjalan melalui log. Untuk mata bersenjata, ini masih agak lebih sulit, karena trik sederhana seperti itu dinetralkan dengan tindakan balasan yang sama, agak sederhana.

Membandingkan parameter permintaan, tajuk, alamat IP satu sama lain dan dengan yang diketahui publik memungkinkan Anda menangkap pengikis paling arogan. Contoh sederhana - bot pencarian datang kepada kami, tetapi karena alasan tertentu IP-nya bukan dari jaringan mesin pencari, tetapi dari beberapa penyedia cloud. Bahkan Google sendiri pada halaman yang menjelaskan Googlebot merekomendasikan melakukan reverse lookup DNS record untuk memastikan bahwa bot ini benar-benar berasal dari google.com atau sumber Google valid lainnya.
Ada banyak pemeriksaan seperti itu, paling sering dirancang untuk pengikis yang tidak peduli dengan fuzzing, semacam substitusi. Untuk kasus yang lebih kompleks, ada metode yang lebih andal dan lebih rumit, misalnya, memasukkan Javascript ke bot ini. Jelas bahwa dalam kondisi seperti itu perjuangannya sudah tidak seimbang - skrip Python Anda tidak akan dapat mengeksekusi dan menafsirkan kode JS. Tapi itu bisa dilakukan oleh penulis skrip - jika penulis bot memiliki cukup waktu, keinginan, sumber daya dan keterampilan untuk pergi dan melihat apa yang dilakukan Javascript Anda di browser.
Inti dari pemeriksaan ini adalah Anda mengintegrasikan skrip ke dalam halaman Anda, dan penting bagi Anda tidak hanya untuk mengeksekusinya, tetapi juga menunjukkan beberapa jenis hasil, yang biasanya POST dikirim kembali ke server sebelum klien cukup tidur. konten, dan halaman itu sendiri akan dimuat. Oleh karena itu, jika penulis bot memecahkan teka-teki dan hardcode Anda dengan jawaban yang benar ke dalam skrip Python-nya, atau, misalnya, memahami di mana ia perlu mengurai baris skrip sendiri untuk mencari parameter yang diperlukan dan metode yang disebut, dan akan menghitung jawabannya sendiri, ia dapat menipu Anda di sekitar jari Anda. Berikut contohnya.

Saya pikir beberapa pendengar akan mengenali bagian javascript ini - ini adalah pemeriksaan yang dulu dimiliki oleh salah satu penyedia cloud terbesar di dunia sebelum mengakses halaman yang diminta, ringkas dan sangat sederhana, dan pada saat yang sama, tanpa mempelajarinya, sangat mudah untuk situs tidak menerobos. Pada saat yang sama, setelah menerapkan sedikit usaha, kita dapat meminta halaman untuk mencari metode JS yang menarik bagi kita yang akan dipanggil, dari mereka, menghitung, menemukan nilai yang menarik bagi kita yang harus dihitung, dan memasukkan perhitungan ke dalam kode. Setelah itu, jangan lupa tidur beberapa detik karena penundaan, dan voila.

Kami sampai ke halaman dan kemudian kami dapat mengurai apa yang kami butuhkan, tidak menghabiskan lebih banyak sumber daya daripada membuat pengikis kami sendiri. Artinya, dari sudut pandang penggunaan sumber daya, kami tidak memerlukan tambahan apa pun untuk menyelesaikan masalah tersebut. Jelas bahwa perlombaan senjata di jalur ini - menulis tantangan JS dan menguraikannya serta mengelak dengan alat pihak ketiga - hanya dibatasi oleh waktu, keinginan, dan keterampilan penulis bot dan penulis cek. Perlombaan ini bisa berlangsung cukup lama, tetapi pada titik tertentu kebanyakan scraper menjadi tidak menarik, karena ada opsi yang lebih menarik untuk mengatasinya. Mengapa duduk-duduk dan mengurai kode JS dengan Python saat Anda bisa langsung mengambil dan menjalankan browser?

Ya, saya terutama berbicara tentang browser tanpa kepala, karena alat ini, awalnya dibuat untuk pengujian dan Tanya Jawab, telah terbukti ideal untuk tugas web scraping saat ini.
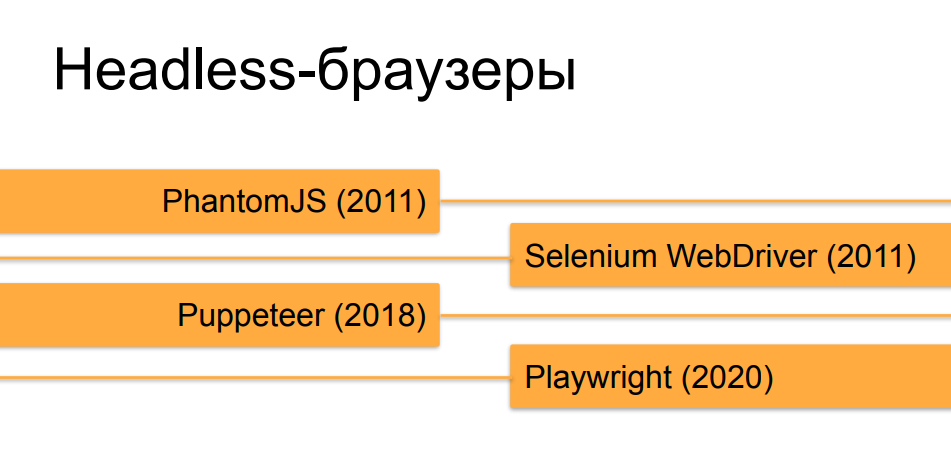
Kami tidak akan membahas secara detail tentang headless browser, saya rasa sebagian besar pendengar sudah tahu tentang mereka. Orchestrator, yang mengotomatiskan browser tanpa kepala, telah mengalami evolusi yang cukup pesat selama 10 tahun terakhir. Pada awalnya, pada saat PhantomJS dan versi pertama Selenium 2.0 dan Selenium WebDriver, browser tanpa kepala yang berjalan di bawah otomat sama sekali tidak sulit untuk dibedakan dari pengguna langsung. Namun, seiring waktu dan munculnya alat-alat seperti Puppeteer untuk Chrome headless dan, sekarang, penciptaan pria dari Microsoft - Playwright, yang melakukan hal yang sama seperti Puppeteer, tetapi tidak hanya untuk Chrome, tetapi untuk semua versi browser populer, mereka semakin banyak. dan mendekatkan browser tanpa kepala dengan yang asli dalam halbagaimana mereka dapat dibuat dengan bantuan orkestrasi serupa dalam perilaku dan dalam tanda dan properti yang berbeda dengan browser orang sehat.

Untuk menangani pengenalan headless'ov dengan latar belakang browser biasa, di belakangnya orang-orang duduk, sebagai aturan, pemeriksaan javascript'ovye yang sama digunakan, tetapi lebih dalam, terperinci, mengumpulkan awan parameter. Hasil pengumpulan ini dikirim kembali ke alat perlindungan atau ke situs tempat pengikis ingin mengumpulkan data. Teknologi ini disebut sidik jari, karena mengumpulkan sidik jari digital nyata dari browser dan perangkat yang menjalankannya.
Ada beberapa hal yang JS periksa saat melihat sidik jari - mereka dapat dibagi menjadi beberapa blok bersyarat, di mana penggalian dapat berlangsung terus dan terus menerus. Ada banyak sekali properti, beberapa di antaranya mudah disembunyikan, beberapa kurang mudah. Dan di sini, seperti pada contoh sebelumnya, banyak hal bergantung pada seberapa cermat pengeruk mendekati tugas menyembunyikan "ekor" tanpa kepala yang menonjol. Ada properti objek di browser, yang digantikan oleh orkestrator secara default, ada properti (navigator.webdriver), yang disetel tanpa kepala, tetapi pada saat yang sama tidak ada di browser biasa. Ini dapat disembunyikan, upaya untuk menyembunyikan dapat dideteksi dengan memeriksa metode tertentu - pemeriksaan apa yang juga dapat disembunyikan dan menyelipkan keluaran palsu ke fungsi yang mencetak metode, misalnya,dan itu bisa bertahan tanpa batas.
Blok pemeriksaan lain, sebagai suatu peraturan, bertanggung jawab untuk mempelajari parameter jendela dan layar, yang menurut definisi tidak ada di browser tanpa kepala: memeriksa koordinat, memeriksa ukuran, berapa ukuran gambar rusak yang belum digambar. Ada banyak nuansa yang dapat diramalkan dengan baik oleh orang yang memahami perangkat browser dan menyelipkan kesimpulan yang masuk akal (tetapi tidak nyata) pada masing-masing, yang akan terbang jauh dalam pemeriksaan sidik jari ke server, yang akan menganalisisnya. Misalnya, dalam hal merender beberapa gambar, 2D dan 3D, melalui WebGL dan Canvas, Anda dapat sepenuhnya menyiapkan seluruh keluaran, memalsukannya, menerbitkannya dengan metode, dan membuat seseorang percaya bahwa ada sesuatu yang benar-benar digambar.
Ada lebih banyak pemeriksaan licik yang tidak terjadi sekaligus, tetapi katakanlah kode JS akan berputar selama beberapa detik pada halaman, atau akan terus-menerus hang dan mentransfer beberapa informasi ke server dari browser. Misalnya, melacak posisi dan kecepatan gerakan kursor - jika bot mengklik hanya di tempat yang dibutuhkan dan mengikuti tautan dengan kecepatan cahaya, maka ini dapat dilacak oleh pergerakan kursor, jika pembuat bot tidak berpikir untuk menulis semacam manusia, mulus , offset.
Dan ada cukup banyak hutan - ini adalah parameter dan properti khusus versi dari model objek, yang spesifik dari browser ke browser, dari versi ke versi. Dan agar pemeriksaan ini berfungsi dengan benar dan tidak memalsukan, misalnya, pada pengguna langsung dengan beberapa browser lama, Anda perlu mempertimbangkan banyak hal. Pertama, Anda perlu mengikuti rilis versi baru, memodifikasi cek Anda sehingga memperhitungkan keadaan di bagian depan. Kompatibilitas mundur harus dijaga agar seseorang dapat mengunjungi situs yang dilindungi oleh pemeriksaan semacam itu pada browser yang tidak biasa dan pada saat yang sama tidak tertangkap seperti bot, dan banyak lainnya.
Ini adalah pekerjaan yang melelahkan, agak rumit - hal-hal seperti itu biasanya dilakukan oleh perusahaan yang menyediakan pendeteksian bot sebagai layanan, dan melakukan ini sendiri dengan sumber daya mereka sendiri bukanlah investasi waktu dan uang yang sangat menguntungkan.
Tapi apa yang harus dilakukan - kita benar-benar perlu mengikis situs, tergantung dengan awan pemeriksaan tanpa kepala seperti itu dan menghitung beberapa krom tanpa kepala dengan dalang, terlepas dari segalanya, tidak peduli seberapa keras kita mencoba.
Penyimpangan lirik kecil - bagi mereka yang tertarik membaca lebih detail tentang sejarah dan evolusi pemeriksaan, misalnya, untuk Chrome tanpa kepala, ada duel epistolary lucu antara dua penulis. Saya tidak tahu banyak tentang satu penulis, dan yang lainnya bernama Antoine Vastel, seorang pemuda dari Prancis yang mengelola blog tentang bot dan pendeteksiannya, kebingungan pemeriksaan, dan banyak hal menarik lainnya. Jadi mereka dan rekan mereka telah berdebat selama dua tahun tentang apakah mungkin mendeteksi Chrome tanpa kepala.
Dan kami akan melanjutkan dan memahami apa yang harus dilakukan jika kami tidak dapat melewati pemeriksaan dengan tanpa kepala.

Ini berarti bahwa kita tidak akan menggunakan headless, tetapi akan menggunakan browser nyata yang besar yang menggambar kita jendela dan segala macam elemen visual. Alat seperti Puppeteer dan Playwright memungkinkan, alih-alih headless, untuk meluncurkan browser dengan layar yang dirender, membaca masukan pengguna dari sana, mengambil tangkapan layar, dan banyak lagi yang tidak tersedia untuk browser tanpa komponen visual.

Selain melewati pemeriksaan tanpa kepala, dalam hal ini, Anda juga dapat mengatasi masalah berikut - saat kami memiliki beberapa pembuat situs yang licik, bersembunyi dari teks dalam gambar, membuatnya tidak terlihat tanpa membuat klik tambahan atau beberapa tindakan dan gerakan lainnya. Mereka menyembunyikan beberapa elemen yang harus disembunyikan, dan yang tanpa kepala ditemukan: mereka tidak tahu bahwa elemen ini seharusnya tidak ditampilkan di layar sekarang, dan mereka menemukannya. Kami cukup menggambar gambar ini di browser, memberi makan tangkapan layar ke OCR, mendapatkan teks pada output dan menggunakannya. Ya, itu lebih sulit, lebih mahal dalam hal pengembangan, membutuhkan waktu lebih lama dan memakan lebih banyak sumber daya. Tetapi ada pengikis yang bekerja dengan cara ini, dan dengan mengorbankan kecepatan dan kinerja, mereka mengumpulkan data dengan cara ini.

"Bagaimana dengan CAPTCHA?" - Anda bertanya. Bagaimanapun, captcha OCR (lanjutan) tidak dapat diselesaikan tanpa beberapa hal yang lebih kompleks. Ada jawaban sederhana untuk ini - jika kita tidak dapat menyelesaikan captcha secara otomatis, mengapa tidak menggunakan tenaga manusia? Mengapa memisahkan bot dan manusia ketika Anda dapat menggabungkan pekerjaan mereka untuk mencapai tujuan?
Ada layanan yang memungkinkan Anda mengirimi mereka captcha, yang diselesaikan oleh tangan orang yang duduk di depan layar, dan melalui API Anda bisa mendapatkan jawaban untuk captcha Anda, memasukkan cookie ke dalam permintaan, misalnya, yang akan dikeluarkan, dan kemudian secara otomatis memproses informasi dari situs ini ... Setiap kali captcha muncul, kami menarik apishka, mendapatkan jawaban untuk captcha - selipkan di pertanyaan berikutnya dan lanjutkan.
Jelas bahwa ini juga membutuhkan biaya yang cukup mahal - solusi CAPTCHA dibeli dalam jumlah besar. Tetapi jika data kita lebih mahal daripada biaya semua trik ini, mengapa tidak?
Sekarang kita telah melihat evolusi menuju kompleksitas dari semua alat ini, mari kita pikirkan tentang apa yang harus dilakukan jika pengikisan terjadi pada sumber daya online kita - toko online, basis pengetahuan publik, atau apapun.

Hal pertama yang harus dilakukan adalah menemukan scraper. Saya akan memberitahu Anda ini: tidak semua kasus pertemuan umum umumnya membawa dampak negatif, seperti yang telah kami bahas di awal laporan. Sebagai aturan, metode yang lebih primitif, skrip yang sama tanpa pembatasan kecepatan, tanpa membatasi kecepatan permintaan, dapat melakukan lebih banyak kerugian (jika tidak dicegah dengan cara perlindungan) daripada pengikisan browser yang rumit, canggih, dan menarik dengan satu permintaan di jam, yang pada awalnya masih perlu entah bagaimana ditemukan di log.

Oleh karena itu, pertama-tama Anda perlu memahami bahwa kami sedang dikesampingkan - untuk melihat makna-makna yang biasanya dipengaruhi oleh aktivitas ini. Kita sekarang berbicara tentang parameter teknis dan metrik bisnis. Ini adalah hal-hal yang dapat Anda lihat di Grafana Anda, dari waktu ke waktu mengamati beban dan lalu lintas, semua jenis semburan dan anomali. Anda juga dapat melakukan ini secara manual jika Anda tidak menggunakan alat keamanan, tetapi lebih andal dilakukan oleh mereka yang tahu cara memfilter lalu lintas, mendeteksi semua jenis insiden dan mencocokkannya dengan beberapa peristiwa. Karena selain menganalisis log setelah fakta dan selain menganalisis setiap permintaan individu, penggunaan beberapa sarana perlindungan basis pengetahuan yang terakumulasi dapat bekerja di sini, yang telah melihat tindakan pengikis pada sumber daya ini atau pada sumber daya serupa, dan entah bagaimana Anda dapat membandingkan satu dengan yang lain - pidato tentang analisis korelasi.
Adapun metrik bisnis, kami telah mengingat kembali menggunakan contoh skrip yang menyebabkan kerusakan finansial langsung atau tidak langsung. Jika dimungkinkan untuk dengan cepat melacak dinamika parameter ini, maka sekali lagi gesekan dapat diperhatikan - dan kemudian, jika Anda memecahkan masalah ini sendiri, selamat datang di log backend Anda.
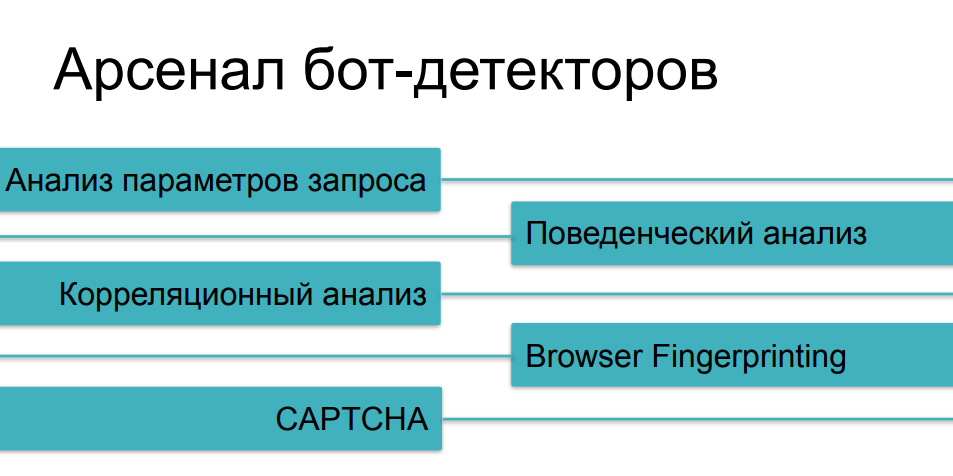
Adapun cara perlindungan yang digunakan terhadap gesekan agresif, kami telah mempertimbangkan sebagian besar metode, berbicara tentang berbagai kategori bot. Analisis lalu lintas akan membantu kita dari kasus yang paling sederhana, analisis perilaku akan membantu melacak hal-hal seperti fuzzing (substitusi identitas) dan skrip multi-instance. Terhadap hal-hal yang lebih kompleks, kami akan mengumpulkan cetakan digital. Dan, tentu saja, kami memiliki CAPTCHA sebagai argumen terakhir para raja - jika kami tidak dapat menangkap bot licik pada pertanyaan sebelumnya, maka, mungkin, bot itu akan tersandung pada CAPTCHA, bukan?
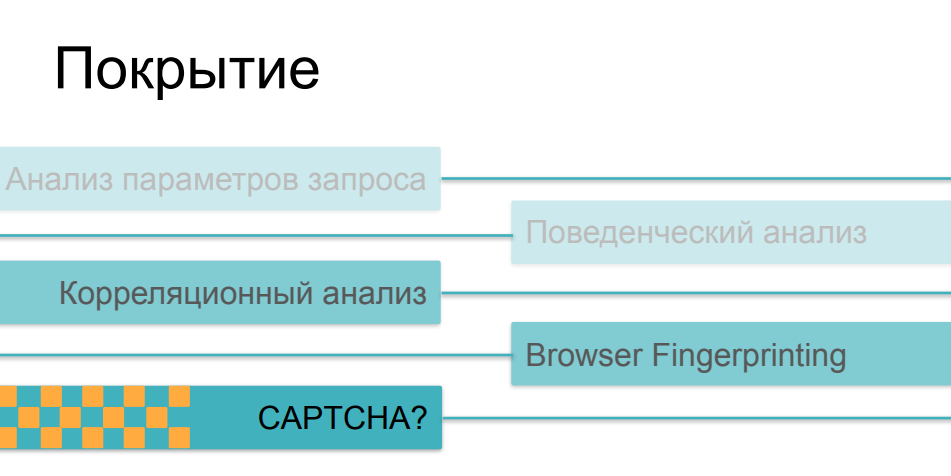
Nah, masalahnya sedikit lebih rumit di sini. Faktanya adalah bahwa ketika kompleksitas dan kelicikan pemeriksaan meningkat, mereka menjadi semakin mahal, terutama untuk sisi klien. Jika analisis lalu lintas dan perbandingan parameter selanjutnya dengan beberapa nilai historis dapat dilakukan secara non-invasif, tanpa mempengaruhi waktu buka halaman dan kecepatan sumber daya online pada prinsipnya, maka sidik jari, jika cukup besar dan membuat ratusan pemeriksaan berbeda di sisi browser, dapat sangat mempengaruhi kecepatan unduh. Dan hanya sedikit orang yang suka melihat halaman dengan pemeriksaan dalam proses tautan berikut.
Terkait CAPTCHA, ini adalah metode paling kasar dan paling invasif. Ini adalah hal yang benar-benar dapat membuat takut pengguna atau pembeli dari sumber daya. Tidak ada yang menyukai captcha, dan mereka tidak menggunakannya karena kehidupan yang baik - mereka menggunakannya ketika semua opsi lain tidak berhasil. Ada satu lagi paradoks lucu di sini, beberapa masalah dengan penerapan metode ini. Faktanya adalah bahwa sebagian besar alat perlindungan dalam satu superposisi atau lainnya menggunakan semua kemungkinan ini, tergantung pada seberapa kompleks skenario aktivitas bot yang mereka temui. Jika pengguna kami berhasil melewati penganalisis lalu lintas, jika perilakunya tidak berbeda dari perilaku pengguna, jika sidik jarinya terlihat seperti browser yang valid, dia mengatasi semua pemeriksaan ini, dan kemudian pada akhirnya kami menunjukkan captcha kepadanya - dan ternyata itu adalah seseorang ... bisa sangat menyedihkan ...Akibatnya, captcha mulai ditampilkan bukan kepada bot jahat yang ingin kami hentikan, tetapi kepada sebagian pengguna yang cukup serius - orang yang mungkin marah pada hal ini dan mungkin tidak datang lain kali, tidak membeli sesuatu di resource, tidak berpartisipasi dalam pengembangan lebih lanjut.

Mempertimbangkan semua faktor ini, apa yang harus kami lakukan pada akhirnya jika kami menemukan scraping, kami melihatnya dan entah bagaimana dapat menilai dampaknya terhadap bisnis dan kinerja teknis kami? Di satu sisi, tidak masuk akal untuk melawan scraping menurut definisi seperti pengumpulan data publik, mesin atau orang - Anda sendiri setuju bahwa data ini tersedia untuk setiap pengguna yang berasal dari Internet. Dan untuk memecahkan masalah membatasi penggosokan "di luar prinsip" - yaitu, karena fakta bahwa bot bot yang canggih dan berbakat mendatangi Anda, Anda mencoba untuk melarang semuanya - itu berarti menghabiskan banyak sumber daya untuk perlindungan, baik milik Anda sendiri, atau menggunakan solusi yang mahal dan sangat kompleks , yang dihosting sendiri atau berbasis cloud dalam "mode keamanan maksimum" dan, dalam mengejar setiap bot individu, berisiko menakut-nakuti pengguna yang valid dengan hal-hal seperti itu,seperti pemeriksaan javascript yang berat, seperti captcha yang muncul di setiap transisi ketiga. Semua ini dapat mengubah situs Anda tanpa bisa dikenali demi pengunjung Anda.
Jika Anda ingin menggunakan alat keamanan, maka Anda perlu mencari alat yang memungkinkan Anda untuk berubah dan entah bagaimana menemukan keseimbangan antara proporsi scraper (dari yang sederhana ke yang rumit) yang akan Anda coba hentikan dari penggunaan sumber daya Anda dan, pada kenyataannya, kecepatan web Anda -sumber. Karena, seperti yang telah kita lihat, beberapa pemeriksaan dilakukan dengan sederhana dan cepat, sementara beberapa pemeriksaan sulit dan memakan waktu - dan pada saat yang sama sangat terlihat oleh pengunjung itu sendiri. Oleh karena itu, solusi yang dapat menerapkan dan memvariasikan tindakan pencegahan ini dalam platform umum akan memungkinkan Anda mencapai keseimbangan ini lebih cepat dan lebih baik.
Nah, sangat penting juga untuk menggunakan apa yang disebut "pola pikir yang benar" dalam mempelajari semua masalah ini sendiri atau contoh orang lain. Harus diingat bahwa bukan data publik itu sendiri yang membutuhkan perlindungan - cepat atau lambat semua orang yang menginginkannya akan melihatnya. Pengalaman pengguna membutuhkan perlindungan: UX pelanggan, pelanggan, dan pengguna Anda, yang, tidak seperti pencakar, menghasilkan pendapatan untuk Anda. Anda dapat menyimpannya dan meningkatkannya jika Anda lebih mahir dalam bidang yang sangat menarik ini.
Terima kasih banyak atas perhatiannya!
