
Melanjutkan siklus catatan tentang masalah nyata dalam Ilmu Data, hari ini kita akan membahas masalah yang hidup dan melihat masalah apa yang menanti kita di sepanjang jalan.
Misal, selain Data Science, saya sudah lama menggemari atletik dan salah satu tujuan lari bagi saya tentunya adalah lari marathon. Dan di mana maraton di sana dan pertanyaannya adalah - seberapa banyak lari? Seringkali jawaban atas pertanyaan ini diberikan dengan mata - "baik, rata-rata, mereka berlari" atau "ini saat yang tepat"!
Dan hari ini kita akan membahas masalah penting - kita akan menerapkan Ilmu Data dalam kehidupan nyata dan menjawab pertanyaan:
Apa yang dikatakan data tentang maraton Moskow?
Lebih tepatnya, seperti yang sudah jelas dari tabel di awal - kami akan mengumpulkan data, mencari tahu siapa yang berlari dan bagaimana. Dan pada saat yang sama, ini akan membantu kita memahami apakah kita harus ikut campur dan memungkinkan kita menilai kekuatan kita dengan bijaksana!
TL; DR: Saya mengumpulkan data tentang perlombaan maraton Moskow untuk 2018/2019, menganalisis waktu dan kinerja para peserta, serta membuat kode dan datanya tersedia untuk umum.
Pengumpulan data
Melalui googling cepat, kami menemukan hasil dari beberapa tahun terakhir, 2019 dan 2018 .
Saya dengan hati-hati melihat halaman web, menjadi jelas bahwa datanya cukup mudah didapat - Anda hanya perlu mencari tahu kelas mana yang bertanggung jawab untuk apa, misalnya, kelas "results-table__col-result", tentu saja, untuk hasilnya, dll.
Tetap memahami bagaimana mendapatkan semua data dari sana.
Dan ini ternyata tidak sulit, karena ada penomoran halaman langsung dan kami benar-benar mengulang seluruh segmen angka. Bingo, data yang terkumpul untuk 2019 dan 2018 ini saya posting disini, jika ada yang tertarik untuk analisa lebih lanjut, maka datanya sendiri bisa di download disini: disini dan disini .
Apa yang harus saya mainkan?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- Jenis data: waktu di sini adalah timedelta, tetapi karena restart dan nilai tidak valid, kami harus bekerja dengan filter dan membersihkan nilai waktu sehingga kami beroperasi pada hasil waktu murni untuk menghitung rata-rata - semua hasil di sini dirata-ratakan dari mereka yang selesai dan siapa yang memiliki waktu yang valid.
Dan berikut adalah kode spoilernya jika ada yang memutuskan untuk terus mengumpulkan data berjalan yang menarik.
Kode parser
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
Analisis waktu dan hasil
Mari beralih ke menganalisis data dan hasil balapan yang sebenarnya.
Panda bekas, numpy, matplotlib, dan seaborn - semuanya klasik.
Selain nilai rata-rata untuk semua larik, kami akan mempertimbangkan grup berikut secara terpisah:
- Pria - karena saya termasuk dalam grup ini, hasil ini menarik bagi saya.
- Wanita adalah untuk simetri.
- 35 — «» , — .
- 2018 2019 — ?.
Pertama, mari kita lihat sekilas tabel di bawah ini - di sini lagi, agar tidak bergulir: ada lebih banyak peserta, rata-rata 95% mencapai garis finish dan sebagian besar pesertanya adalah laki-laki. Oke, ini berarti bahwa rata-rata saya berada di grup utama dan data rata-rata harus mewakili waktu rata-rata dengan baik bagi saya. Ayo lanjutkan.
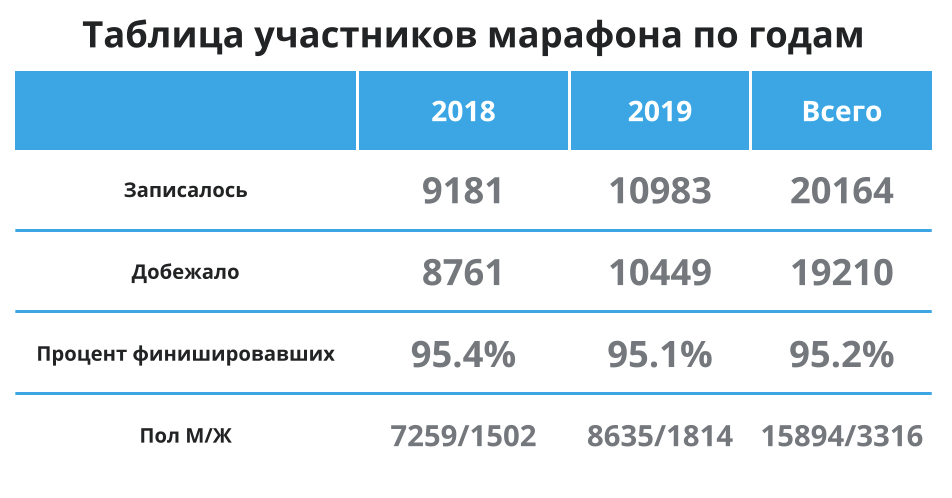

Seperti yang bisa kita lihat, rata-rata untuk 2018 dan 2019 praktis tidak berubah - sekitar 1,5 menit lebih cepat untuk pelari pada 2019. Perbedaan antara kelompok yang menarik bagi saya dapat diabaikan.
Mari beralih ke distribusi secara keseluruhan. Dan pertama sampai total waktu balapan.
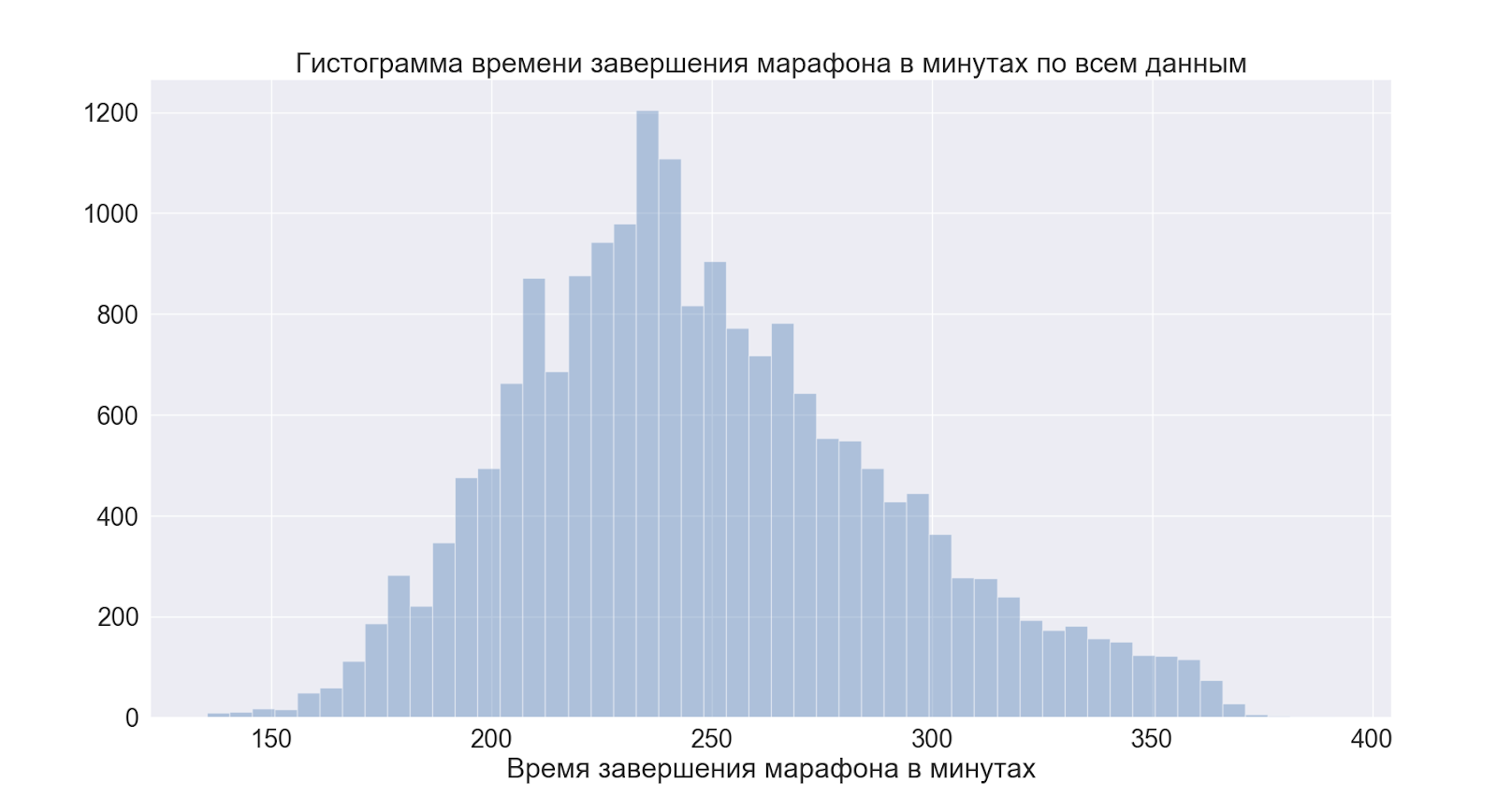
Seperti yang bisa kita lihat puncaknya sebelum pukul 4 - ini adalah tanda bersyarat bagi mereka yang suka "lari dengan baik" = "kehabisan 4 jam", data tersebut mengkonfirmasi rumor populer.
Selanjutnya, mari kita lihat bagaimana situasi telah berubah rata-rata sepanjang tahun.
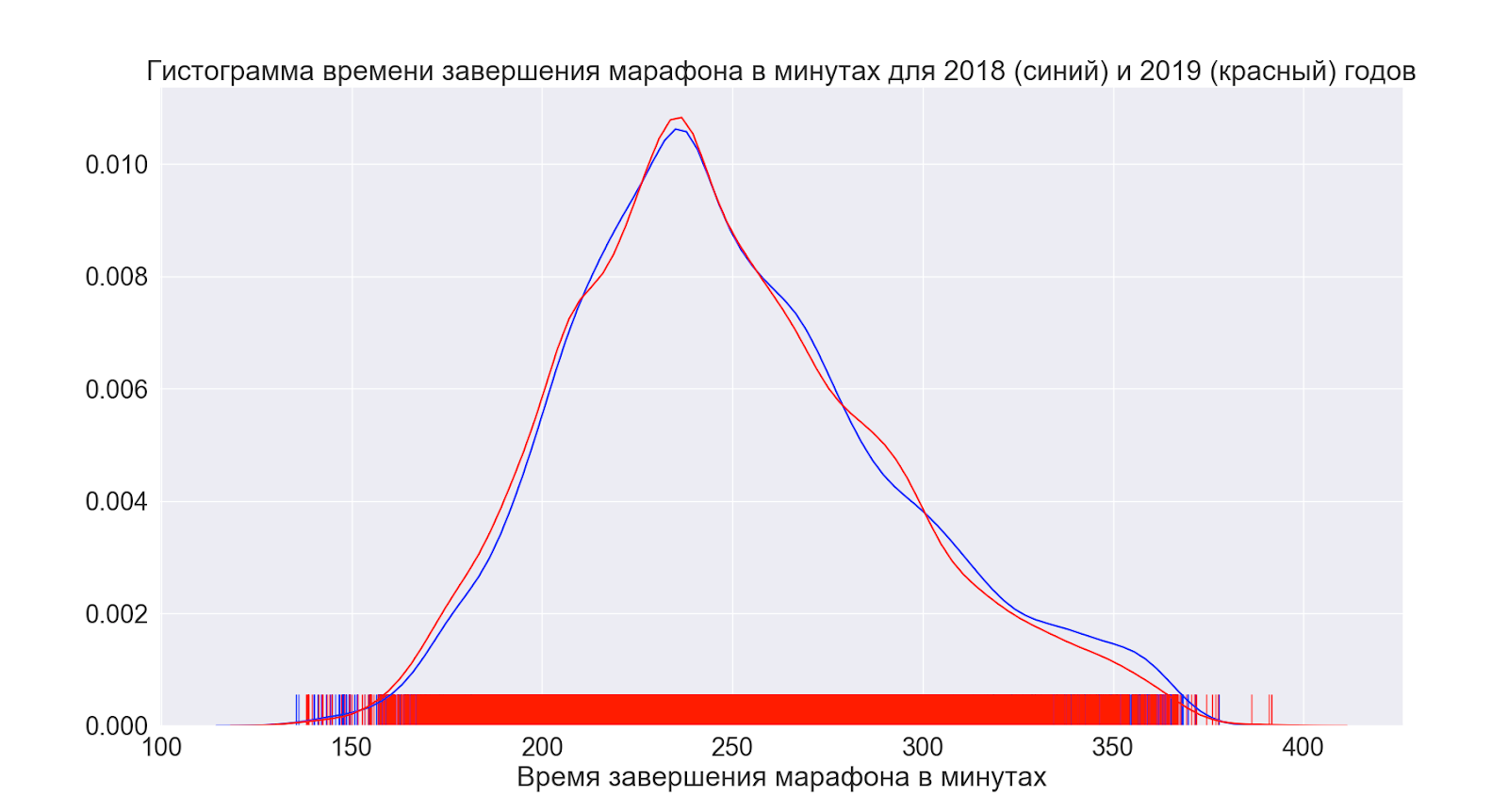
Seperti yang dapat kita lihat, pada kenyataannya, tidak ada yang berubah sama sekali - distribusinya terlihat hampir sama.
Selanjutnya, pertimbangkan distribusi menurut jenis kelamin:

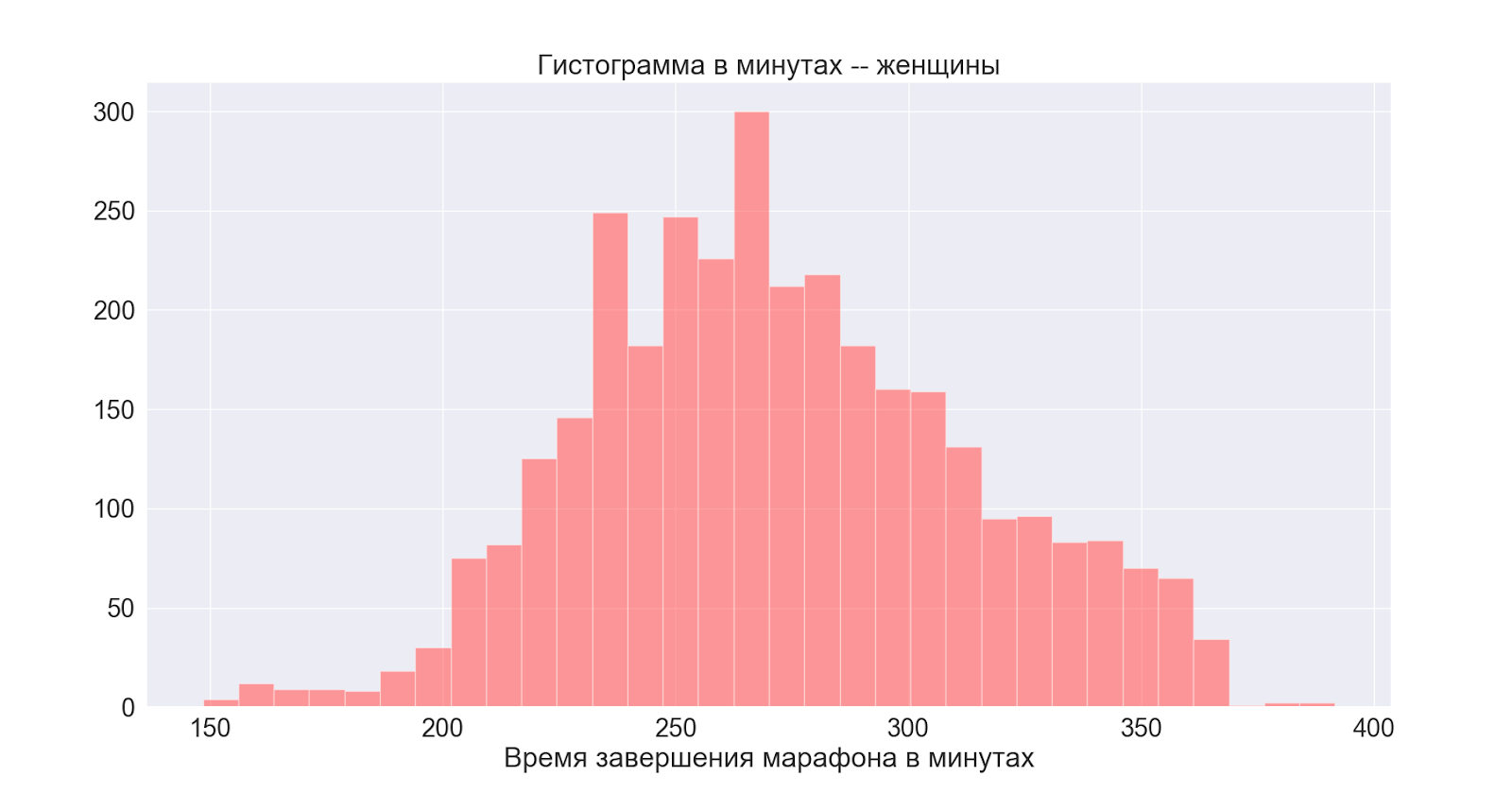
Secara umum, kedua distribusi normal dengan pusat yang sedikit berbeda - kita melihat bahwa puncak pada pria juga memanifestasikan dirinya pada distribusi utama (umum).
Secara terpisah, mari beralih ke grup yang paling menarik bagi saya:
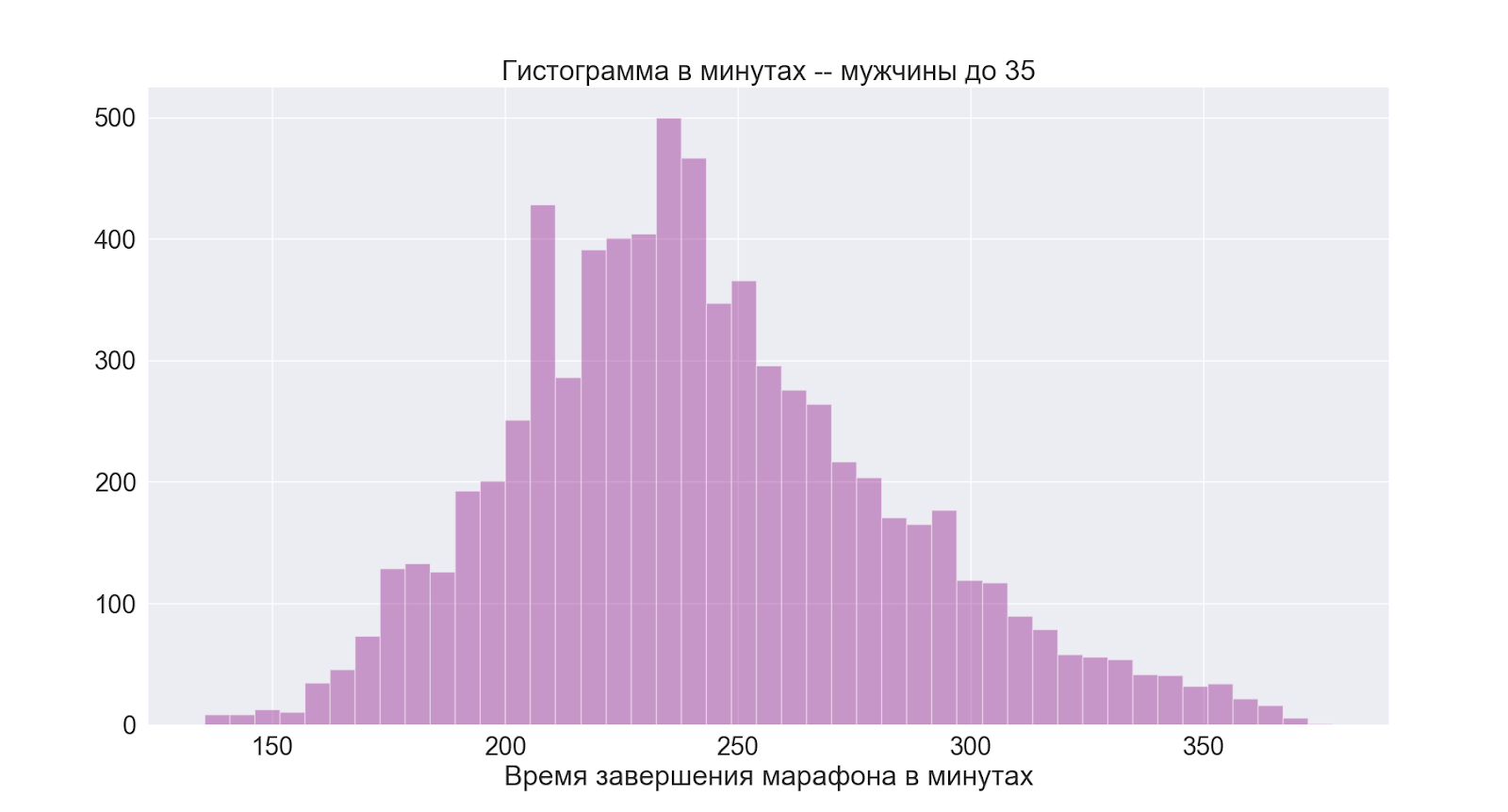
Seperti yang bisa kita lihat, gambarnya pada dasarnya sama dengan grup pria secara keseluruhan.
Dari sini kami menyimpulkan bahwa 4 jam juga merupakan waktu rata-rata yang baik bagi saya.
Mempelajari peningkatan peserta 2018 → 2019
Yang menarik: untuk beberapa alasan saya berpikir bahwa sekarang saya akan segera mengumpulkan data dan saya bisa masuk lebih dalam ke dalam analisis, mencari pola di sana selama berjam-jam, dan seterusnya. Ternyata sebaliknya, mengumpulkan data ternyata lebih sulit daripada analisis itu sendiri - menurut klasik, bekerja dengan jaringan, data mentah, pembersihan, pemformatan, pengecoran, dll., Membutuhkan lebih banyak waktu daripada analisis dan visualisasi. Jangan lupa bahwa hal-hal kecil menyita sedikit waktu - tetapi ada cukup banyak [hal-hal kecil], dan pada akhirnya akan memakan seluruh malam Anda.
Secara terpisah, saya ingin melihat bagaimana orang-orang yang berpartisipasi kedua kali meningkatkan hasil mereka, dengan membandingkan data antara tahun-tahun, saya dapat menetapkan yang berikut ini:
- 14 orang berpartisipasi selama dua tahun dan tidak pernah selesai
- 89 orang berlari pada 18 m, tetapi gagal pada 19
- 124 sebaliknya
- Mereka yang berhasil menjalankan kedua kali meningkatkan hasil mereka dengan rata-rata 4 menit
Tapi di sini semuanya ternyata cukup menarik:
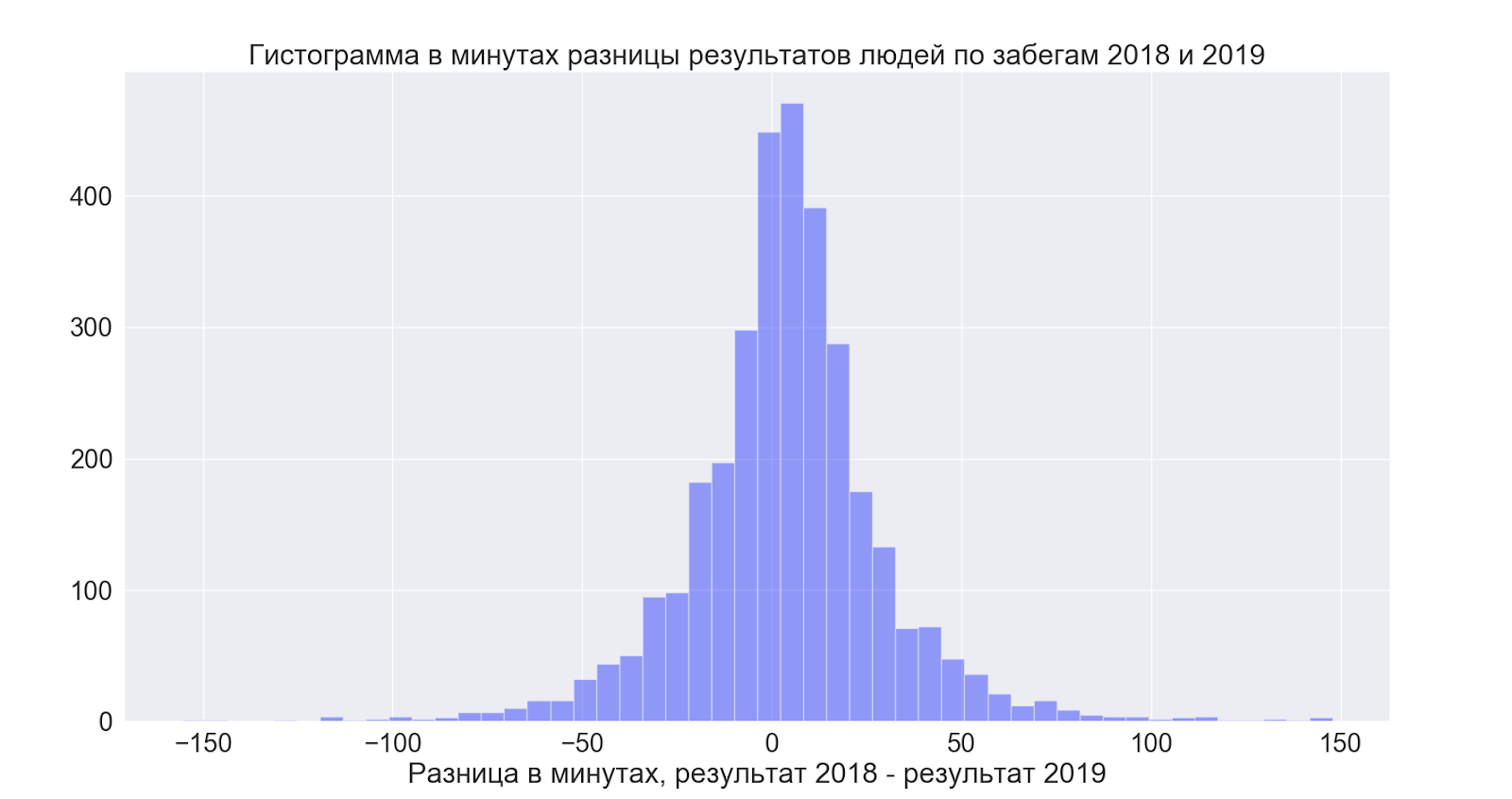
Artinya, rata-rata, orang sedikit meningkatkan hasil - tetapi secara umum penyebarannya luar biasa dan di kedua arah - yaitu, baik untuk berharap akan lebih baik - tetapi dilihat dari data, ternyata secara umum seperti yang Anda suka!
kesimpulan
Saya membuat kesimpulan berikut untuk diri saya sendiri dari data yang dianalisis
- Secara keseluruhan, 4 jam adalah target rata-rata yang baik.
- Kelompok pelari utama sudah pada usia yang sangat kompetitif (dan satu kelompok dengan saya).
- Rata-rata, orang sedikit meningkatkan hasil mereka, tetapi secara umum, dilihat dari datanya, bagaimana mereka sampai di sana.
- Hasil rata-rata untuk seluruh balapan hampir sama untuk kedua tahun.
- Sangat nyaman membicarakan maraton dari sofa.
