
Selama tiga tahun terakhir, Nvidia telah membuat chip grafis di mana, selain inti yang biasa digunakan untuk shader, juga dipasang inti tambahan. Inti-inti ini, yang disebut inti tensor, sudah ditemukan di ribuan desktop, laptop, workstation, dan pusat data di seluruh dunia. Tapi apa yang mereka lakukan dan untuk apa mereka digunakan? Apakah mereka bahkan dibutuhkan dalam kartu grafis?
Hari ini kami akan menjelaskan apa itu tensor dan bagaimana kernel tensor digunakan dalam dunia grafis dan pembelajaran mendalam.
Pelajaran matematika singkat
Untuk memahami apa yang dilakukan kernel tensor dan kegunaannya, pertama-tama kita mencari tahu apa itu tensor. Semua mikroprosesor, apa pun tugas yang mereka lakukan, melakukan operasi matematika pada angka (penjumlahan, perkalian, dll.).
Terkadang angka-angka ini perlu dikelompokkan karena memiliki arti khusus satu sama lain. Misalnya, saat chip memproses data untuk membuat grafik, chip dapat menangani nilai integer tunggal (katakanlah, +2 atau +115) sebagai faktor penskalaan, atau sekelompok float (+0.1, -0.5, +0.6) sebagai a koordinat titik dalam ruang 3D. Dalam kasus kedua, ketiga item data diperlukan untuk posisi titik.
TensorMerupakan suatu benda matematika yang menggambarkan hubungan antara benda matematika lainnya yang saling berkaitan. Mereka biasanya ditampilkan sebagai deretan angka, yang dimensinya ditunjukkan di bawah ini.

Jenis tensor paling sederhana memiliki dimensi nol dan terdiri dari satu nilai; jika tidak, ini disebut skalar . Ketika jumlah dimensi bertambah, kita menemukan struktur matematika umum lainnya:
- 1 dimensi = vektor
- 2 dimensi = matriks
Sebenarnya, skalar adalah tensor 0 x 0, vektor 1 x 0, dan matriks 1 x 1, tetapi demi kesederhanaan dan referensi ke inti tensor GPU, kita akan mempertimbangkan tensor hanya dalam bentuk matriks.
Salah satu operasi matematika terpenting yang dilakukan pada matriks adalah perkalian (atau perkalian). Mari kita lihat bagaimana dua matriks dengan empat baris dan kolom data dikalikan satu sama lain:
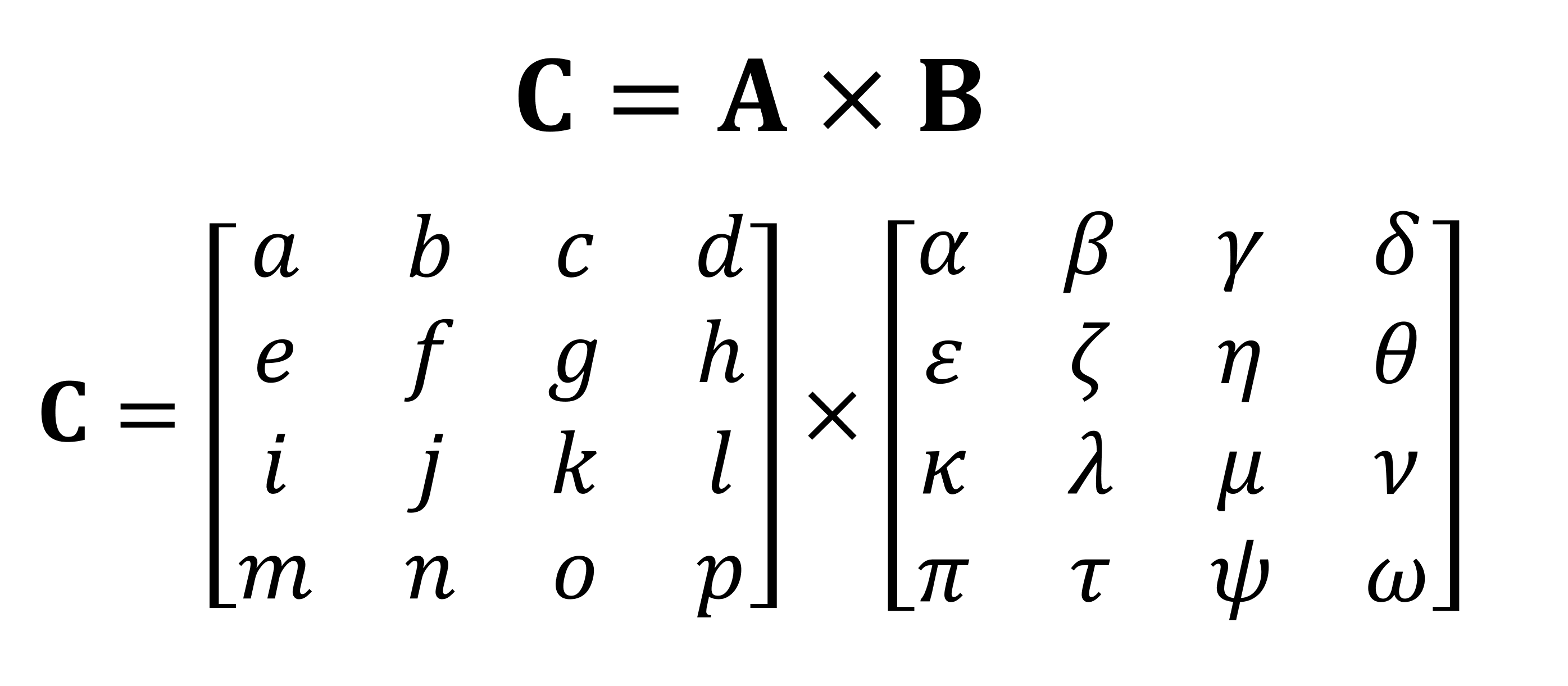
Hasil akhir perkalian akan selalu menjadi jumlah baris yang sama seperti pada matriks pertama, dan jumlah kolom yang sama seperti pada matriks kedua. Bagaimana Anda mengalikan dua larik ini? Seperti ini:
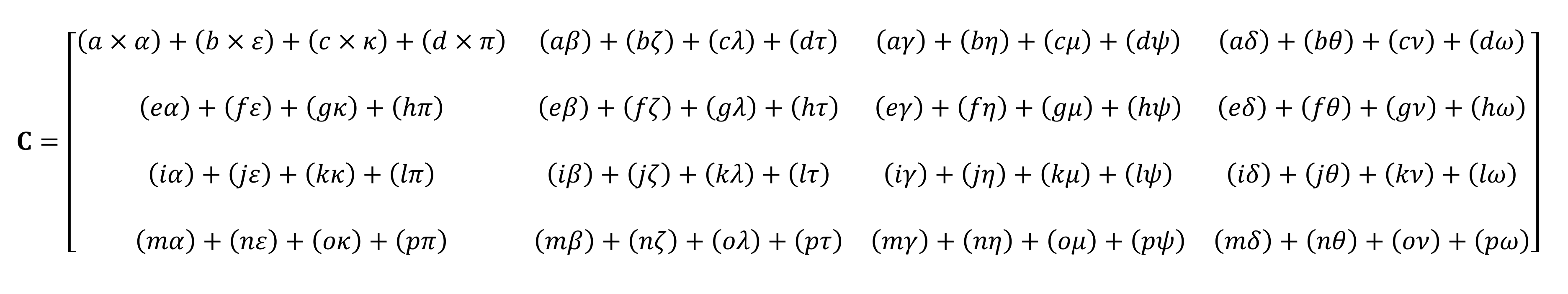
Tidak akan mungkin untuk menghitungnya dengan jari
Seperti yang Anda lihat, perhitungan dari perkalian "sederhana" dari matriks terdiri dari sejumlah perkalian kecil dan penjumlahan. Karena unit pemrosesan pusat modern dapat melakukan kedua operasi ini, tensor paling sederhana dapat dilakukan oleh setiap desktop, laptop, atau tablet.
Namun, contoh di atas mengandung 64 perkalian dan 48 penjumlahan; setiap produk kecil memberikan nilai yang perlu disimpan di suatu tempat sebelum dapat ditambahkan ke tiga produk kecil lainnya sehingga nilai tensor akhir dapat disimpan nanti. Oleh karena itu, terlepas dari kesederhanaan matematis dari perkalian matriks, perkalian matriks itu mahal secara komputasi . - perlu menggunakan banyak register, dan cache harus mampu menangani banyak operasi baca dan tulis.

Arsitektur Intel Sandy Bridge, yang pertama kali memperkenalkan ekstensi AVX
Selama bertahun-tahun, prosesor AMD dan Intel memiliki berbagai ekstensi (MMX, SSE, dan sekarang AVX - yang semuanya adalah SIMD, instruksi tunggal dengan banyak data ), memungkinkan prosesor untuk memproses banyak angka secara bersamaan titik mengambang; inilah yang dibutuhkan untuk perkalian matriks.
Tetapi ada jenis prosesor khusus yang dirancang khusus untuk menangani operasi SIMD: unit pemrosesan grafis (GPU).
Lebih pintar dari kalkulator biasa?
Dalam dunia grafik, penting untuk secara bersamaan mengirimkan dan memproses informasi dalam jumlah besar dalam bentuk vektor. Karena kemampuan pemrosesan paralelnya, GPU ideal untuk pemrosesan tensor; semua GPU modern mendukung fungsi yang disebut GEMM ( General Matrix Multiplication ).
Ini adalah operasi "terpaku" di mana dua matriks dikalikan dan hasilnya kemudian diakumulasikan dengan matriks lain. Ada batasan penting dalam format matriks, dan semuanya terkait dengan jumlah baris dan kolom dari setiap matriks.

Persyaratan baris dan kolom GEMM: matriks A (mxk), matriks B (kxn), matriks C (mxn)
Algoritme yang digunakan untuk melakukan operasi pada matriks biasanya bekerja paling baik saat matriks berbentuk persegi (misalnya, array 10 x 10 akan berfungsi lebih baik dari 50 x 2) dan ukurannya cukup kecil. Tetapi mereka masih akan berkinerja lebih baik jika diproses pada peralatan yang dirancang khusus untuk operasi semacam itu.
Pada Desember 2017, Nvidia merilis kartu grafis dengan GPU yang menampilkan arsitektur Volta baru . Itu ditujukan untuk pasar profesional, jadi chip ini tidak digunakan dalam model GeForce. Itu unik karena itu adalah GPU pertama dengan inti hanya untuk komputasi tensor.

Kartu grafis Nvidia Titan V dengan chip GV100 Volta. Ya, Anda dapat menjalankan Crysis di atasnya .
Inti tensor Nvidia dirancang untuk menjalankan 64 GEMM per siklus clock dengan matriks 4 x 4 yang berisi nilai FP16 (bilangan floating point 16 bit) atau perkalian FP16 dengan penambahan FP32. Tensor semacam itu berukuran sangat kecil, jadi saat memproses kumpulan data nyata, kernel memproses bagian kecil dari matriks besar, membangun jawaban akhir.
Kurang dari setahun kemudian, Nvidia merilis arsitektur Turing . Kali ini, inti tensor juga dipasang di model GeForcetingkat konsumen. Sistem ditingkatkan untuk mendukung format data lain, seperti INT8 (nilai integer 8-bit), tetapi selain itu berfungsi sama seperti di Volta.

Awal tahun ini, arsitektur Ampere memulai debutnya di GPU pusat data A100 , dan kali ini Nvidia meningkatkan kinerja (256 GEMM per siklus, bukan 64), menambahkan format data baru, dan kemampuan untuk memproses tensor jarang yang sangat cepat (matriks dengan banyak nol).
Pemrogram dapat mengakses inti tensor chip Volta, Turing, dan Ampere dengan sangat mudah: kode hanya perlu menggunakan tanda yang memberi tahu API dan driver untuk menggunakan inti tensor, tipe data harus didukung oleh inti, dan dimensi matriks harus kelipatan 8. Saat dijalankan Semua kondisi ini akan diurus oleh peralatan.
Itu semua bagus, tetapi seberapa baik Tensor Core dalam memproses GEMM daripada core GPU biasa?
Ketika Volta keluar, Anandtech menjalankan tes matematika pada tiga kartu Nvidia: Volta baru, yang paling kuat dari jajaran Pascal, dan kartu Maxwell yang lama.
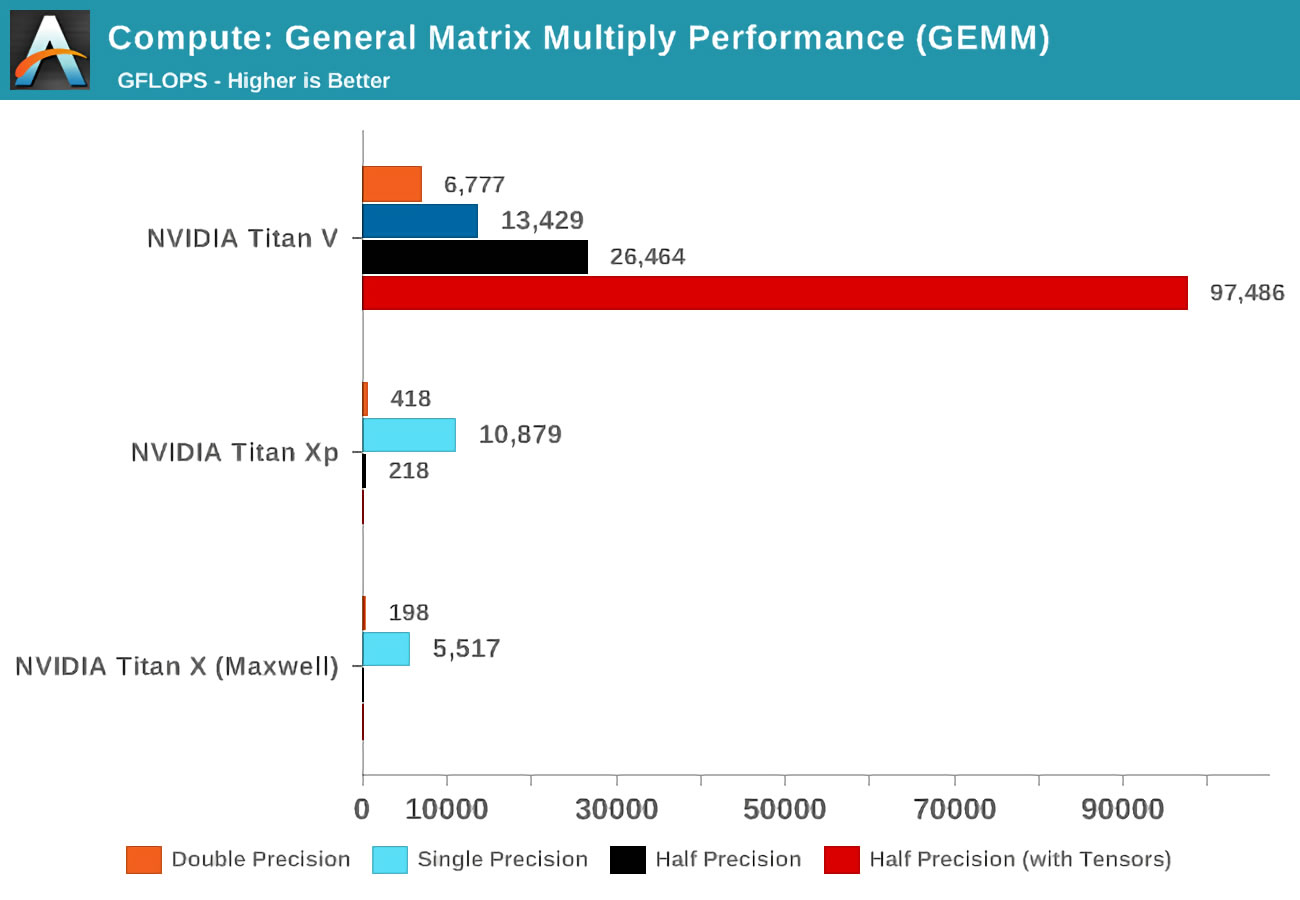
Konsep akurasi (presisi) mengacu pada jumlah bit yang digunakan untuk bilangan floating-point dalam matriks: ganda (ganda) menunjukkan 64, tunggal (tunggal) - 32, dan seterusnya. Sumbu horizontal adalah jumlah maksimum operasi floating point yang dilakukan per detik, atau singkatnya FLOP (ingat bahwa satu GEMM adalah 3 FLOP).
Lihat saja hasilnya saat menggunakan kernel tensor alih-alih yang disebut kernel CUDA! Jelas, mereka luar biasa dalam pekerjaan ini, tetapi apa yang dapat kita lakukan dengan kernel tensor?
Matematika yang membuat segalanya lebih baik
Komputasi tensor sangat berguna dalam fisika dan teknik, digunakan untuk menyelesaikan semua jenis masalah kompleks dalam mekanika fluida , elektromagnetisme, dan astrofisika , namun, komputer yang digunakan untuk memproses bilangan tersebut biasanya melakukan operasi pada matriks dalam cluster besar dari unit pemrosesan pusat.
Area lain di mana tensor populer adalah pembelajaran mesin , terutama subbagiannya "pembelajaran mendalam". Artinya bermuara pada pemrosesan kumpulan data besar dalam array raksasa yang disebut jaringan saraf . Koneksi antara nilai data yang berbeda diberi bobot tertentu - angka yang menyatakan pentingnya koneksi tertentu.
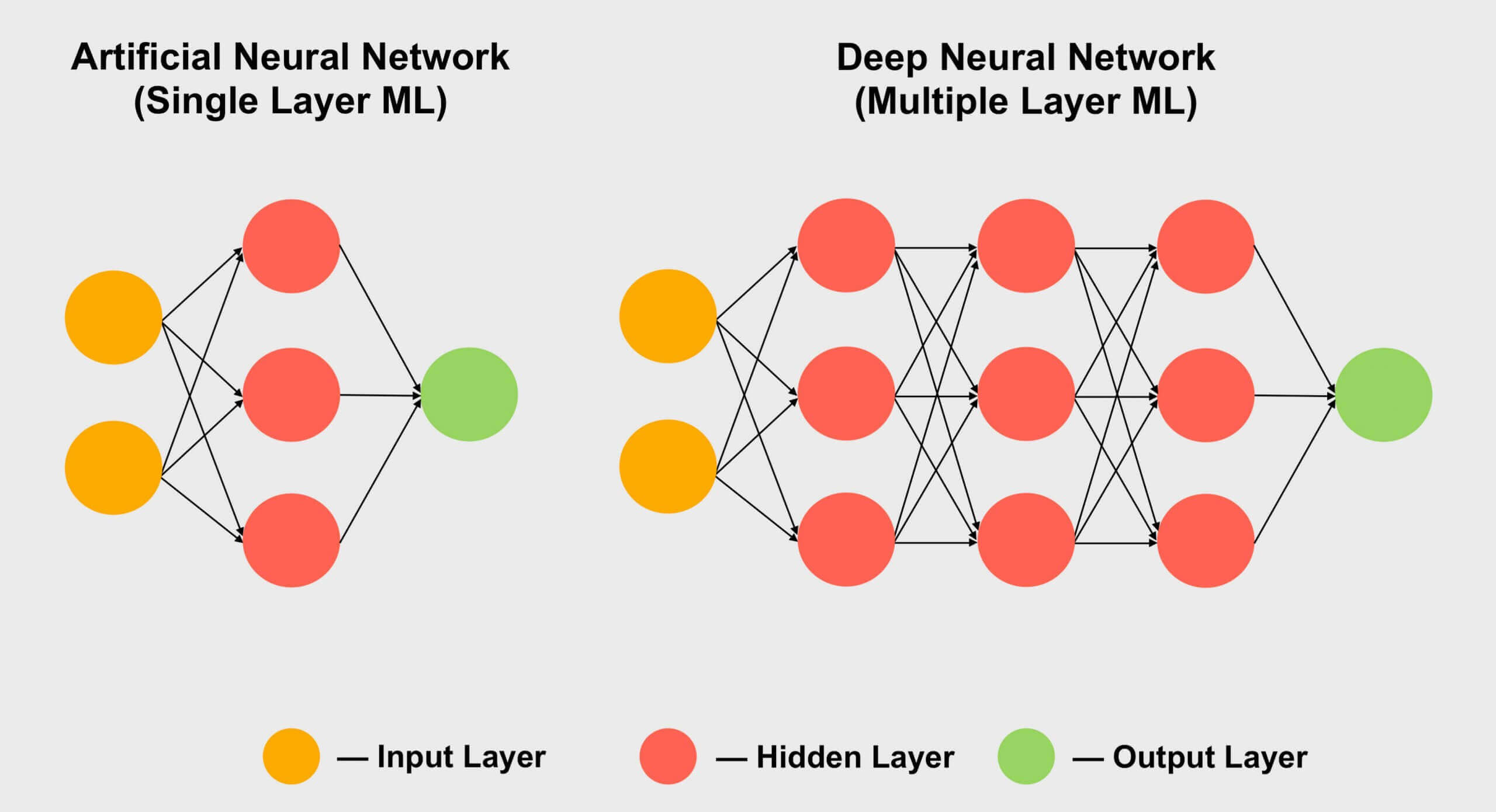
Jadi, saat kita perlu mencari tahu bagaimana ratusan, bahkan ribuan koneksi ini berinteraksi, kita perlu mengalikan setiap bagian data di jaringan dengan semua bobot koneksi yang memungkinkan. Dengan kata lain, kalikan dua matriks, yang merupakan matematika tensor klasik!

Chip Google TPU 3.0 dilindungi oleh sistem pendingin air.
Inilah sebabnya mengapa semua superkomputer pembelajaran mendalam menggunakan GPU, dan hampir selalu Nvidia. Namun, beberapa perusahaan bahkan telah mengembangkan prosesor mereka sendiri dari inti tensor. Google, misalnya, mengumumkan pengembangan TPU ( unit pemrosesan tensor ) pertamanya pada tahun 2016 , tetapi chip ini sangat terspesialisasi sehingga tidak dapat melakukan apa pun selain operasi dengan matriks.
Tensor Cores dalam GPU Konsumen (GeForce RTX)
Tetapi bagaimana jika saya membeli kartu grafis Nvidia GeForce RTX, bukan ahli astrofisika yang memecahkan masalah berjenis Riemannian, atau ahli yang bereksperimen dengan kedalaman jaringan saraf konvolusional ...? Bagaimana cara menggunakan kernel tensor?
Lebih sering daripada tidak, mereka tidak berlaku untuk rendering video biasa, encoding, atau decoding, jadi sepertinya Anda telah membuang-buang uang untuk fitur yang tidak berguna. Namun, Nvidia telah membangun inti tensor ke dalam produk konsumennya pada tahun 2018 (Turing GeForce RTX) saat mengimplementasikan DLSS - Deep Learning Super Sampling .

Prinsipnya sederhana: render bingkai pada resolusi yang cukup rendah, dan setelah selesai, tingkatkan resolusi hasil akhir agar sesuai dengan dimensi layar "asli" monitor (misalnya, render pada 1080p, lalu ubah ukurannya menjadi 1400p). Ini meningkatkan kinerja karena lebih sedikit piksel yang diproses dan masih menghasilkan gambar yang indah di layar.
Konsol telah memiliki fitur ini selama bertahun-tahun, dan banyak game PC modern menyediakan fitur ini juga. Dalam Assassin's Creed: Odyssey dari Ubisoft, Anda dapat mengurangi resolusi render menjadi hanya 50% dari resolusi monitor. Sayangnya, hasilnya tidak terlalu bagus. Seperti inilah tampilan game dalam 4K dengan pengaturan grafis maksimal:

Tekstur terlihat lebih bagus pada resolusi tinggi karena mempertahankan lebih banyak detail. Namun, dibutuhkan banyak pemrosesan untuk menampilkan piksel ini di layar. Sekarang lihat apa yang terjadi jika render disetel ke 1080p (25% dari jumlah piksel sebelumnya), menggunakan shader di bagian akhir untuk meregangkan gambar menjadi 4K.

Karena kompresi jpeg, perbedaannya mungkin tidak langsung terlihat, tetapi Anda dapat melihat bahwa pelindung karakter dan batu di kejauhan terlihat buram. Mari perbesar bagian gambar untuk melihat lebih dekat:

Gambar di sebelah kiri ditampilkan dalam 4K; gambar di sebelah kanan adalah 1080p dengan resolusi 4K. Perbedaannya jauh lebih terlihat pada gerakan, karena pelunakan semua detail dengan cepat berubah menjadi kekacauan yang kabur. Sebagian dari ketajaman dapat dipulihkan berkat efek penajaman driver kartu grafis, tetapi kami berharap kami tidak perlu melakukan ini sama sekali.
Di sinilah DLSS berperan - di versi pertamateknologi ini Nvidia menganalisis beberapa game terpilih; mereka berjalan pada resolusi tinggi, resolusi rendah, dengan dan tanpa anti-aliasing. Dalam semua mode ini, sekumpulan gambar dibuat dan kemudian dimuat ke superkomputer perusahaan, yang menggunakan jaringan saraf untuk menentukan cara terbaik mengubah gambar 1080p menjadi gambar resolusi tinggi yang ideal.

Saya harus mengatakan bahwa DLSS 1.0 tidak sempurna : detail sering hilang dan kedipan aneh muncul di beberapa tempat. Selain itu, ia tidak menggunakan inti tensor kartu grafis itu sendiri (ia berjalan di jaringan Nvidia) dan setiap game yang mendukung DLSS memerlukan penelitian Nvidia terpisah untuk menghasilkan algoritme peningkatan.

Ketika versi 2.0 dirilis pada awal tahun 2020, perbaikan besar dilakukan padanya. Yang terpenting, superkomputer Nvidia sekarang hanya digunakan untuk membuat algoritme peningkatan umum - versi baru DLSS menggunakan data dari bingkai yang dirender untuk memproses piksel menggunakan model saraf (inti tensor GPU).

Kami terkesan dengan kemampuan DLSS 2.0 , tetapi sejauh ini sangat sedikit game yang mendukungnya - pada saat penulisan ini, hanya ada 12. Semakin banyak pengembang ingin menerapkannya di game masa depan mereka, dan untuk alasan yang baik.
Setiap peningkatan skala dapat mencapai peningkatan produktivitas yang signifikan, sehingga Anda dapat yakin bahwa DLSS akan terus berkembang.
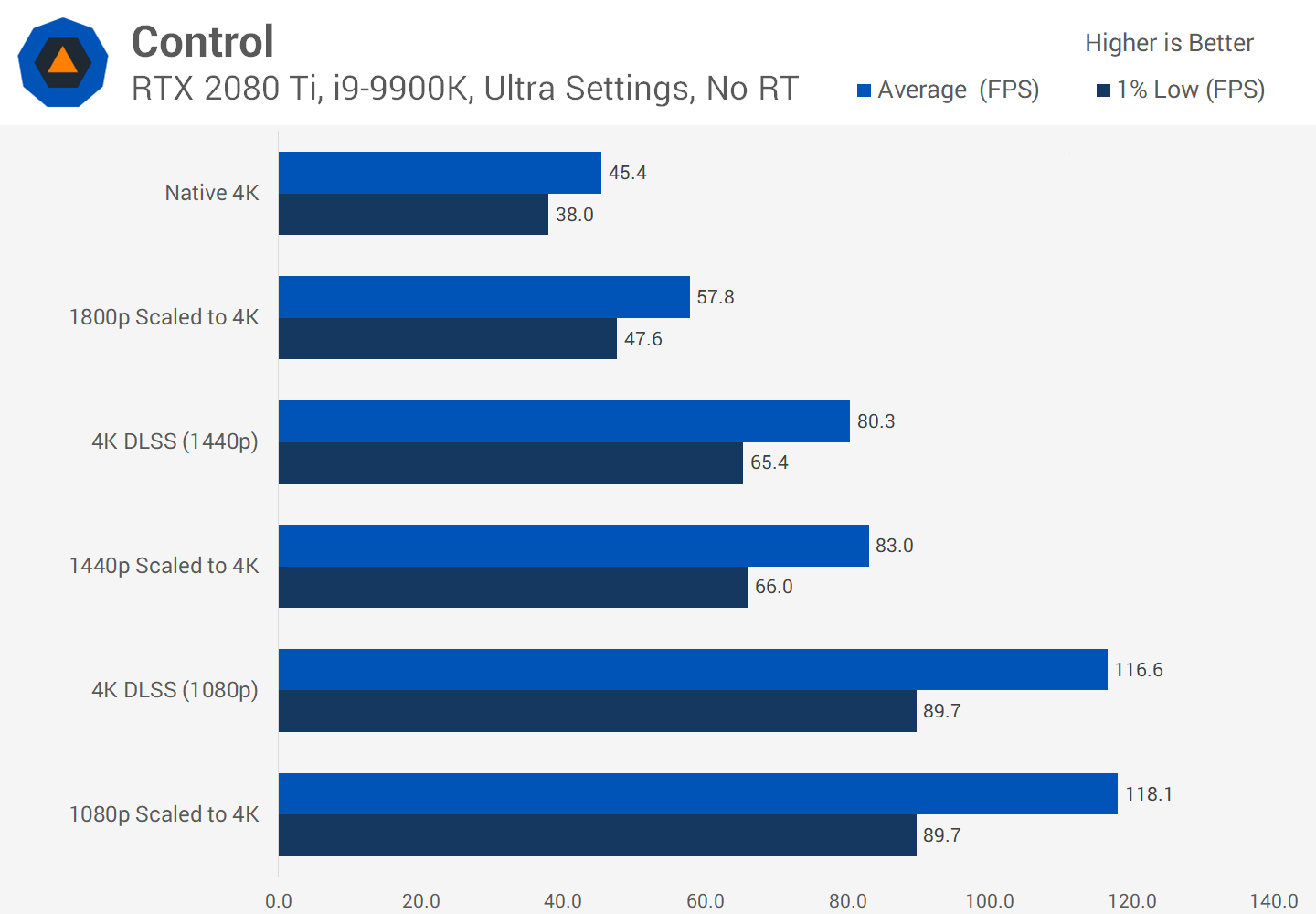
Meskipun hasil visual DLSS tidak selalu sempurna, dengan membebaskan resource rendering, developer dapat menambahkan lebih banyak efek visual atau menyediakan satu level grafik di berbagai platform yang lebih luas.
Misalnya, DLSS sering diiklankan bersama pelacakan sinar di game yang "mendukung RTX". Kartu GeForce RTX berisi blok komputasi tambahan yang disebut inti RT, yang merupakan blok logika khusus untuk mempercepat persimpangan sinar-segitiga dan traversal hierarki volume pembatas (BVH). Kedua proses ini merupakan prosedur yang sangat memakan waktu yang menentukan bagaimana cahaya berinteraksi dengan objek lain di tempat kejadian.
Seperti yang kami temukan, penelusuran sinarMerupakan proses yang sangat memakan waktu, jadi untuk memastikan tingkat frekuensi gambar yang dapat diterima dalam game, pengembang harus membatasi jumlah sinar dan pantulan yang dilakukan di tempat kejadian. Proses ini dapat membuat gambar berbintik, sehingga algoritma pengurangan kebisingan harus diterapkan, yang meningkatkan kompleksitas pemrosesan. Diharapkan kernel tensor akan meningkatkan kinerja proses ini dengan menghilangkan derau menggunakan AI, tetapi ini belum terwujud: sebagian besar aplikasi modern masih menggunakan kernel CUDA untuk tugas ini. Di sisi lain, karena DLSS 2.0 menjadi teknik peningkatan ukuran yang sangat praktis, Kernel Tensor dapat digunakan secara efektif untuk meningkatkan frekuensi gambar setelah penelusuran sinar dalam sebuah adegan.
Ada rencana lain untuk menggunakan inti tensor kartu GeForce RTX, seperti meningkatkan animasi karakter atau menyimulasikan kain . Tetapi seperti halnya DLSS 1.0, akan sangat lama sebelum ada ratusan game yang menggunakan komputasi matriks khusus pada GPU.
Awal yang menjanjikan
Jadi, situasinya seperti ini - inti tensor, unit perangkat keras yang sangat baik, yang, bagaimanapun, hanya ditemukan di beberapa kartu kelas konsumen. Akankah ada perubahan di masa depan? Karena Nvidia telah meningkatkan kinerja setiap Tensor Core dalam arsitektur Ampere secara signifikan, ada kemungkinan besar Nvidia juga akan dipasang di model kelas bawah dan menengah.
Meskipun core tersebut belum ada di GPU AMD dan Intel, mungkin di masa depan kita akan melihatnya. AMD memiliki sistem untuk mempertajam atau meningkatkan detail dalam bingkai jadi dengan biaya sedikit penurunan kinerja, sehingga perusahaan dapat tetap menggunakan sistem ini, terutama karena tidak perlu diintegrasikan oleh pengembang, itu cukup untuk mengaktifkannya di driver.
Ada juga persepsi bahwa ruang pada kristal di chip grafis akan lebih baik dihabiskan untuk inti shader tambahan - inilah yang dilakukan Nvidia saat membuat versi anggaran dari chip Turing-nya. Pada produk seperti GeForce GTX 1650 , perusahaan telah sepenuhnya membuang inti tensor dan menggantinya dengan shader FP16 tambahan.
Tetapi untuk saat ini, jika Anda ingin menyediakan pemrosesan GEMM ultra cepat dan memanfaatkannya sepenuhnya, Anda memiliki dua opsi: membeli sekumpulan CPU multicore besar atau hanya satu GPU dengan inti tensor.
Lihat juga: