 Halo para Penduduk! Kami telah menerbitkan panduan praktis untuk memproses dan menghasilkan teks bahasa alami. Buku ini dilengkapi dengan semua alat dan teknik yang diperlukan untuk membuat sistem NLP terapan untuk memastikan pengoperasian asisten virtual (chatbot), filter spam, program moderator forum, penganalisis sentimen, program pembangunan basis pengetahuan, penganalisis teks bahasa alami yang cerdas, atau hampir semua aplikasi NLP lain yang bisa dibayangkan.
Halo para Penduduk! Kami telah menerbitkan panduan praktis untuk memproses dan menghasilkan teks bahasa alami. Buku ini dilengkapi dengan semua alat dan teknik yang diperlukan untuk membuat sistem NLP terapan untuk memastikan pengoperasian asisten virtual (chatbot), filter spam, program moderator forum, penganalisis sentimen, program pembangunan basis pengetahuan, penganalisis teks bahasa alami yang cerdas, atau hampir semua aplikasi NLP lain yang bisa dibayangkan.
Buku ini ditujukan untuk pengembang Python tingkat menengah hingga mahir. Bagian penting dari buku ini akan berguna bagi para pembaca yang telah mengetahui cara merancang dan mengembangkan sistem yang kompleks, karena berisi banyak contoh solusi yang direkomendasikan dan mengungkapkan kemampuan algoritme NLP paling modern. Meskipun pengetahuan tentang pemrograman berorientasi objek dengan Python dapat membantu Anda membangun sistem yang lebih baik, informasi dalam buku ini tidak diwajibkan.
Apa yang akan Anda temukan di buku itu
I . , . , , , , , . -, , 2–4, . , 90%- 1990- — .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
, . , , , ( ). , - , . , .
. II . «» , : , , .
, , . , , . « » , , .
III, , , .
Umpan balik jaringan saraf: jaringan saraf berulang
Bab 7 menunjukkan kemungkinan menganalisis fragmen atau seluruh kalimat menggunakan jaringan saraf konvolusional, melacak kata-kata yang berdekatan dalam kalimat dengan menerapkan filter bobot bersama (melakukan konvolusi) pada kata tersebut. Kata-kata yang muncul dalam kelompok juga dapat ditemukan dalam satu bundel. Jaring juga tahan terhadap perubahan kecil posisi kata-kata ini. Pada saat yang sama, konsep yang berdekatan dapat mempengaruhi jaringan secara signifikan. Tetapi jika Anda perlu melihat gambaran besar tentang apa yang terjadi, pertimbangkan hubungan dalam jangka waktu yang lebih lama, jendela yang mencakup lebih dari 3-4 token dari pasokan? Bagaimana cara memperkenalkan konsep peristiwa masa lalu ke dalam jaringan? Penyimpanan?
Untuk setiap contoh pelatihan (atau kumpulan contoh yang tidak teratur) dan keluaran (atau kumpulan keluaran) jaringan saraf tiruan umpan maju, bobot jaringan saraf perlu disesuaikan untuk neuron individu berdasarkan metode propagasi mundur. Kami telah menunjukkan ini. Tetapi hasil dari tahap pelatihan untuk contoh berikut sebagian besar tidak bergantung pada urutan data masukan. Jaringan neural konvolusional berusaha menangkap hubungan tatanan ini dengan menangkap hubungan lokal, tetapi ada cara lain.
Dalam jaringan neural konvolusional, setiap contoh pelatihan diteruskan ke jaringan sebagai kumpulan token kata yang dikelompokkan. Vektor kata dikelompokkan menjadi matriks dalam bentuk (panjang kata vektor × jumlah kata dalam contoh), seperti yang ditunjukkan pada Gambar. 8.1.

Tapi urutan vektor kata ini dapat dengan mudah disampaikan ke jaringan saraf maju feedforward dari Bab 5 (Gambar 8.2), bukan?
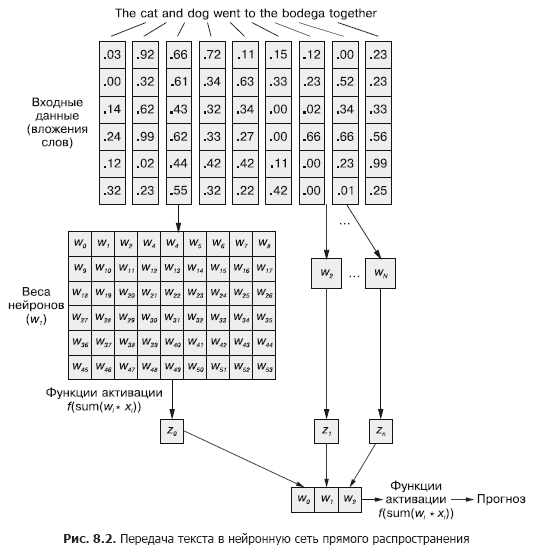
Tentu saja, ini adalah model yang bisa diterapkan dengan sempurna. Dengan metode melewatkan data masukan ini, jaringan saraf maju umpan akan dapat merespons kejadian bersama dari token, yang kita butuhkan. Tetapi pada saat yang sama, itu akan bereaksi terhadap semua kemunculan bersama dengan cara yang sama, terlepas dari apakah mereka dipisahkan oleh teks yang panjang, atau mereka bersebelahan. Selain itu, jaringan neural feedforward, seperti CNN, buruk dalam menangani dokumen dengan panjang variabel. Mereka tidak dapat memproses teks di akhir dokumen jika melebihi lebar web.
Jaringan saraf maju umpan bekerja paling baik dalam memodelkan hubungan sampel data secara keseluruhan dengan labelnya yang sesuai. Kata-kata di awal dan di akhir kalimat memiliki efek yang sama pada sinyal keluaran seperti di tengah, meskipun kata-kata tersebut tidak mungkin terkait satu sama lain secara semantik.
Keseragaman seperti itu (keseragaman pengaruh) jelas dapat menyebabkan masalah dalam kasus, misalnya, token dan pengubah negasi yang keras (kata sifat dan keterangan) seperti "tidak" atau "baik". Dalam jaringan neural feedforward, kata-kata negasi memengaruhi arti semua kata dalam sebuah kalimat, bahkan jika kata-kata tersebut berada jauh dari tempat yang seharusnya mereka pengaruhi.
Konvolusi satu dimensi adalah cara untuk menyelesaikan hubungan antar token ini dengan mengurai beberapa kata di seluruh jendela. Lapisan downsampling yang dibahas dalam Bab 7 dirancang khusus untuk mengakomodasi perubahan kecil dalam urutan kata. Dalam bab ini, kita akan melihat pendekatan berbeda yang akan membantu kita mengambil langkah pertama menuju konsep memori jaringan saraf. Alih-alih membongkar bahasa sebagai bagian besar data, kita akan mulai melihat formasi berurutannya, token demi token, seiring waktu.
8.1. Menghafal di jaringan saraf
Tentu saja, kata-kata dalam kalimat jarang sepenuhnya independen satu sama lain; kemunculannya dipengaruhi atau dipengaruhi oleh kemunculan kata lain dalam dokumen. Misalnya: Mobil curian melaju ke arena dan Mobil badut melaju ke arena.
Anda mungkin memiliki kesan yang sangat berbeda dari kedua kalimat tersebut ketika Anda membaca sampai akhir. Konstruksi frasa di dalamnya sama: kata sifat, kata benda, kata kerja, dan frasa preposisional. Tetapi penggantian kata sifat di dalamnya secara radikal mengubah esensi dari apa yang terjadi dari sudut pandang pembaca.
Bagaimana memodelkan hubungan seperti itu? Bagaimana memahami bahwa arena dan bahkan kecepatan dapat memiliki konotasi yang sedikit berbeda jika ada kata sifat di depannya dalam kalimat yang bukan merupakan definisi langsung dari salah satunya?
Jika ada cara untuk mengingat apa yang terjadi sesaat sebelumnya (terutama mengingat apa yang terjadi pada langkah t pada langkah t + 1), maka akan mungkin untuk mengidentifikasi pola yang muncul saat token tertentu muncul dalam urutan pola yang terkait dengan token lain. Jaringan neural berulang (RNN) memungkinkan jaringan neural menghafal kata-kata urutan sebelumnya.
Seperti yang Anda lihat di gbr. 8.3, neuron berulang yang terpisah dari lapisan tersembunyi menambahkan loop berulang ke jaringan untuk "menggunakan kembali" output dari lapisan tersembunyi pada waktu t. Keluaran pada waktu t ditambahkan ke masukan berikutnya pada waktu t + 1. Jaringan memproses masukan baru ini pada langkah waktu t + 1 untuk menghasilkan keluaran lapisan tersembunyi pada waktu t + 1. Keluaran ini pada waktu t + 1 kemudian digunakan kembali oleh jaringan dan termasuk dalam sinyal input pada langkah waktu t + 2, dll.
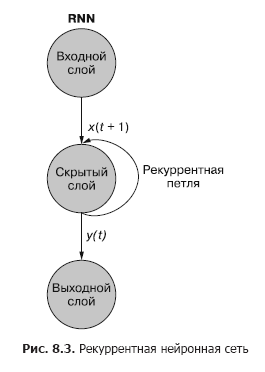
Meskipun gagasan untuk memengaruhi suatu keadaan melalui waktu terlihat sedikit membingungkan, konsep dasarnya sederhana. Hasil dari setiap sinyal pada input dari jaringan neural feedforward konvensional pada langkah waktu t digunakan sebagai sinyal input tambahan bersama dengan potongan data berikutnya yang diumpankan ke input jaringan pada langkah waktu t + 1. Jaringan menerima informasi tidak hanya tentang apa yang terjadi sekarang, tetapi juga tentang apa yang terjadi sebelumnya ...
. , . , . , . , . , , . . , .
t . , t = 0 — , t + 1 — . () . , . — .
t, — t + 1.
Jaringan saraf berulang dapat divisualisasikan seperti yang ditunjukkan pada Gambar. 8.3: Lingkaran sesuai dengan seluruh lapisan jaringan saraf maju, terdiri dari satu atau lebih neuron. Keluaran dari lapisan tersembunyi disediakan oleh jaringan seperti biasa, tetapi kemudian kembali sebagai masukannya sendiri (lapisan tersembunyi) bersama dengan data masukan biasa pada langkah waktu berikutnya. Dalam diagram, loop umpan balik ini digambarkan sebagai busur yang mengarah dari keluaran lapisan kembali ke masukan.
Cara yang lebih sederhana (dan lebih umum digunakan) untuk menggambarkan proses ini menggunakan penyebaran jaringan. Gambar 8.4 menunjukkan jaringan terbalik dengan dua sapuan dari variabel waktu (t) - lapisan untuk langkah t + 1 dan t + 2.
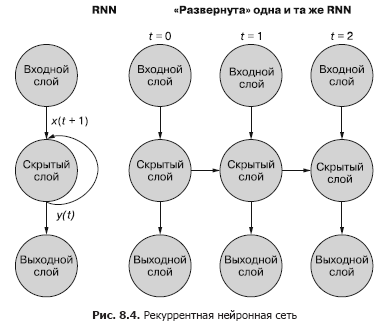
Setiap langkah waktu sesuai dengan versi yang diperluas dari jaringan saraf yang sama dalam bentuk kolom neuron. Ini seperti menonton skrip atau bingkai video individu dari jaringan saraf pada waktu tertentu. Jaring di sebelah kanan menunjukkan versi jala di sebelah kiri. Sinyal keluaran dari lapisan tersembunyi pada waktu (t) diumpankan kembali ke masukan dari lapisan tersembunyi bersama dengan data masukan untuk langkah waktu berikutnya (t + 1) di sebelah kanan. Sekali lagi. Diagram menunjukkan dua iterasi dari penyebaran ini, total tiga kolom neuron untuk t = 0, t = 1, dan t = 2.
Semua rute vertikal dalam diagram ini sepenuhnya analog, mereka menunjukkan neuron yang sama. Mereka mencerminkan jaringan saraf yang sama pada titik waktu yang berbeda. Representasi visual ini berguna untuk mendemonstrasikan pergerakan maju dan mundur informasi melalui jaringan selama propagasi mundur dari suatu kesalahan. Namun ingatlah saat melihat ketiga jaringan yang diterapkan ini: mereka adalah snapshot yang berbeda dari jaringan yang sama dengan kumpulan bobot yang sama.
Mari kita lihat lebih dekat representasi asli dari jaringan neural berulang sebelum menerapkannya dan menunjukkan hubungan antara bobot dan sinyal input. Lapisan individu RNN ini terlihat seperti yang ditunjukkan pada Gambar. 8.5 dan 8.6.

Semua neuron laten memiliki satu set bobot yang diterapkan ke masing-masing elemen dari masing-masing vektor input, seperti dalam jaringan feedforward konvensional. Namun dalam skema ini, satu set tambahan bobot yang dapat dilatih muncul, yang diterapkan pada sinyal keluaran neuron tersembunyi dari langkah waktu sebelumnya. Jaringan, dengan pelatihan, memilih bobot yang sesuai (kepentingan) dari peristiwa sebelumnya saat memasukkan token urutan dengan token.
«», t = 0 t – 1. «» , , . t = 0 . , .
Kembali ke data, bayangkan Anda memiliki sekumpulan dokumen, yang masing-masing adalah contoh berlabel. Dan alih-alih meneruskan seluruh kumpulan vektor kata ke jaringan saraf konvolusional untuk setiap sampel, seperti pada bab sebelumnya (Gambar 8.7), kami mentransfer data sampel ke RNN, satu token pada satu waktu (Gambar 8.8).

Kami meneruskan vektor kata-kata untuk token pertama dan mendapatkan output dari jaringan saraf berulang kami. Kemudian kami mentransfer token kedua, dan dengan itu sinyal keluaran dari yang pertama! Setelah itu, kami mentransfer token ketiga bersama dengan sinyal keluaran dari token kedua! Dll Sekarang dalam jaringan saraf kita terdapat konsep "sebelum" dan "setelah", sebab dan akibat, beberapa, meskipun tidak jelas, gagasan waktu (lihat Gambar 8.8).
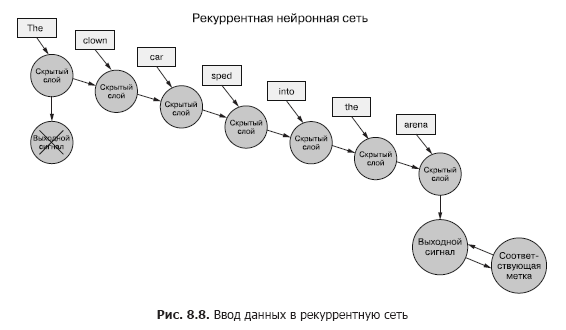
Sekarang jaringan kita sudah mengingat sesuatu! Ya, sampai batas tertentu. Masih ada beberapa hal yang harus dipikirkan. Pertama, bagaimana propagasi balik dari kesalahan terjadi dalam struktur seperti itu?
8.1.1. Propagasi balik dari kesalahan waktu
Semua jaringan yang dibahas di atas memiliki label target (variabel target), dan RNN tidak terkecuali. Tetapi kami tidak memiliki konsep label untuk setiap token, dan hanya ada satu label untuk semua token dari setiap teks contoh. Kami hanya memiliki label untuk dokumen contoh.
Kita berbicara tentang token sebagai masukan ke jaringan di setiap langkah waktu, tetapi jaringan saraf berulang juga dapat bekerja dengan data deret waktu apa pun. Token dapat berupa apa saja, diskrit atau kontinu: pembacaan stasiun cuaca, catatan, simbol dalam kalimat, dll.
Di sini pertama-tama kita membandingkan output jaringan pada langkah waktu terakhir dengan isyarat. Inilah yang akan kami (untuk saat ini) sebut sebagai kesalahan, yaitu, jaringan kami mencoba meminimalkannya. Namun ada sedikit perbedaan dari chapter-chapter sebelumnya. Sampel data yang diberikan dibagi menjadi beberapa bagian kecil yang dimasukkan ke jaringan saraf secara berurutan. Namun, alih-alih langsung menggunakan keluaran untuk masing-masing sub-contoh ini, kami mengirimkannya kembali ke jaringan.
Sejauh ini, kami hanya tertarik pada sinyal keluaran akhir. Setiap token dalam urutan dimasukkan ke dalam jaringan, dan kerugian dihitung berdasarkan keluaran dari langkah terakhir kali (token) (Gambar 8.9).
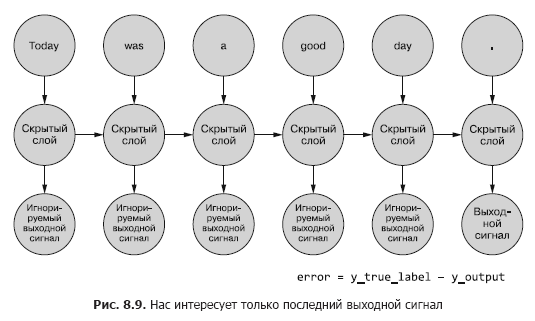
Penting untuk menentukan, jika ada kesalahan untuk contoh yang diberikan, bobot mana yang akan diperbarui dan berapa banyak. Di Bab 5, kami menunjukkan kepada Anda bagaimana melakukan backpropagate kesalahan melalui jaringan normal. Dan kita tahu bahwa jumlah koreksi bobot tergantung pada kontribusinya (bobot ini) terhadap kesalahan. Kita dapat memasukkan token dari urutan sampel ke input jaringan, menghitung kesalahan untuk langkah waktu sebelumnya berdasarkan sinyal outputnya. Di sinilah gagasan propagasi mundur kesalahan waktu tampaknya membingungkan segalanya.
Namun, orang dapat menganggapnya sebagai proses yang terikat waktu. Pada setiap langkah waktu, token, mulai dari yang pertama pada t = 0, diumpankan satu per satu ke input neuron tersembunyi yang terletak di depan - kolom berikutnya pada Gambar. 8.9. Dalam hal ini, jaringan meluas, menampilkan kolom jaringan berikutnya, yang sudah siap menerima token berikutnya dalam urutan tersebut. Neuron laten terungkap satu per satu, seperti kotak musik atau piano mekanis. Pada akhirnya, ketika semua elemen contoh dimasukkan ke dalam jaringan, tidak akan ada lagi yang bisa diterapkan dan kami akan mendapatkan label akhir untuk variabel target yang kami minati, yang dapat digunakan untuk menghitung kesalahan dan menyesuaikan bobot. Kami baru saja menelusuri grafik komputasi untuk jaring yang tidak digulung ini.
Untuk saat ini, kami menganggap data masukan umumnya statis. Anda dapat menelusuri seluruh grafik yang sinyal inputnya memasuki neuron mana. Dan karena kita tahu bagaimana neuron bekerja, kita dapat menyebarkan kesalahan kembali sepanjang rantai, di sepanjang jalur yang sama, seperti dalam kasus jaringan saraf penerus umpan konvensional.
Untuk menyebarkan kesalahan kembali ke lapisan sebelumnya, kita akan menggunakan aturan rantai. Alih-alih lapisan sebelumnya, kami akan menyebarkan kesalahan ke lapisan yang sama di masa lalu, seolah-olah semua varian jaringan yang diterapkan berbeda (Gambar 8.10). Ini tidak mengubah perhitungan matematika.

Kesalahan menyebar kembali dari langkah terakhir. Gradien langkah waktu yang lebih awal relatif terhadap yang lebih baru dihitung. Setelah menghitung semua gradien individu melalui token, hingga langkah t = 0 untuk contoh ini, perubahan akan digabungkan dan diterapkan ke satu set bobot.
8.1.2. Kapan memperbarui apa
Kami telah mengubah RNN aneh kami menjadi sesuatu seperti jaringan neural feedforward biasa, jadi memperbarui bobot harusnya langsung. Namun, ada satu keberatan. Triknya adalah bahwa bobot tidak diperbarui sama sekali di cabang jaringan saraf lain. Setiap cabang mewakili jaringan yang sama pada titik waktu yang berbeda. Bobot untuk setiap langkah waktu adalah sama (lihat Gambar 8.10).
Solusi sederhana untuk masalah ini adalah menghitung koreksi bobot pada setiap langkah waktu dengan penundaan pembaruan. Dalam jaringan feedforward, semua pembaruan bobot dihitung segera setelah penghitungan semua gradien untuk sinyal input tertentu. Dan di sini persis sama, tetapi pembaruan ditunda sampai kita mencapai langkah waktu awal (nol) untuk sampel data masukan tertentu.
Perhitungan gradien harus didasarkan pada nilai bobot di mana mereka memberikan kontribusi pada kesalahan ini. Inilah bagian yang paling luar biasa: bobot pada langkah waktu t berkontribusi dalam beberapa cara untuk kesalahan tersebut. Dan bobot yang sama mendapat sinyal input lain pada langkah waktu t + 1, yang berarti memberikan kontribusi yang berbeda terhadap kesalahan.
Anda dapat menghitung berbagai perubahan bobot di setiap langkah waktu, menjumlahkannya, lalu menerapkan perubahan yang dikelompokkan ke bobot lapisan tersembunyi sebagai langkah terakhir dalam fase pelatihan.
, . , , . , , . , .
Sihir nyata. Dalam kasus propagasi mundur dari kesalahan waktu, bobot individu dapat dikoreksi dalam satu arah pada langkah waktu t (tergantung pada responsnya terhadap sinyal input pada langkah waktu t), dan kemudian ke arah lain pada langkah waktu t - 1 (sesuai dengan bagaimana ia bereaksi terhadap sinyal input pada langkah waktu t - 1) untuk satu sampel data! Ingatlah bahwa jaringan saraf secara umum didasarkan pada meminimalkan fungsi kerugian terlepas dari kerumitan langkah perantara. Secara kolektif, jaringan mengoptimalkan fitur kompleks ini. Karena pembaruan bobot diterapkan hanya sekali untuk data sampel, jaringan (jika konvergen sama sekali, tentu saja) pada akhirnya berhenti pada bobot paling optimal dalam pengertian ini untuk sinyal input tertentu dan neuron tertentu.
Hasil dari langkah sebelumnya masih penting
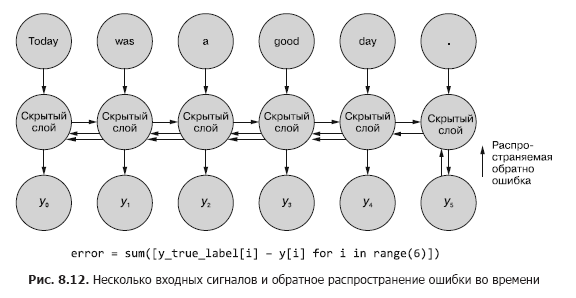
Terkadang seluruh urutan nilai yang dihasilkan di semua langkah waktu menengah adalah penting. Dalam Bab 9, kami akan memberikan contoh situasi di mana keluaran dari langkah waktu tertentu t sama pentingnya dengan keluaran dari langkah waktu terakhir. Dalam gambar. 8.11 menunjukkan metode untuk mengumpulkan data kesalahan untuk setiap langkah waktu dan menyebarkannya kembali untuk memperbaiki semua bobot jaringan.

Proses ini menyerupai propagasi balik biasa dari kesalahan dalam waktu n langkah waktu. Dalam kasus ini, kami menyebarkan bug kembali dari beberapa sumber pada waktu yang sama. Namun, seperti pada contoh pertama, penyesuaian bobot bersifat aditif. Kesalahan menyebar dari langkah terakhir kali di awal ke langkah pertama dengan jumlah perubahan di masing-masing bobot. Kemudian hal yang sama terjadi dengan kesalahan yang dihitung pada langkah waktu kedua dari belakang, menjumlahkan semua perubahan hingga t = 0. Proses ini diulangi sampai kita mencapai langkah waktu nol dengan propagasi balik dari kesalahan itu seolah-olah itu adalah satu-satunya. Kemudian perubahan kumulatif diterapkan sekaligus ke lapisan tersembunyi yang sesuai.
Dalam gambar. Gambar 8.12 menunjukkan bagaimana error menyebar dari setiap sinyal keluaran kembali ke t = 0, kemudian dikumpulkan sebelum koreksi akhir bobot. Ini adalah ide utama dari bagian ini. Seperti dalam kasus jaringan saraf maju umpan konvensional, bobot diperbarui hanya setelah menghitung perubahan yang diusulkan dalam bobot untuk seluruh langkah propagasi mundur untuk sinyal masukan yang diberikan (atau kumpulan sinyal masukan). Dalam kasus RNN, propagasi balik dari kesalahan mencakup pembaruan hingga waktu t = 0.
Memperbarui bobot sebelumnya akan mendistorsi kalkulasi gradien dengan propagasi kesalahan mundur pada titik waktu sebelumnya. Ingat, gradien dihitung relatif terhadap bobot tertentu. Jika bobot ini diperbarui terlalu dini, katakanlah pada langkah waktu t, maka saat menghitung gradien pada langkah waktu t - 1, nilai bobot (ingat bahwa ini adalah posisi bobot yang sama dalam jaringan) akan berubah. Dan saat menghitung gradien berdasarkan sinyal masukan dari langkah waktu t - 1, perhitungan akan terdistorsi. Faktanya, dalam kasus ini, beban akan didenda (atau dihargai) untuk apa yang "tidak bisa disalahkan"!
Tentang Penulis
Hobson Lane(Hobson Lane) memiliki pengalaman 20 tahun membangun sistem otonom yang membuat keputusan penting untuk kepentingan masyarakat. Di Talentpair, Hobson mengajar mesin untuk membaca dan memahami resume dengan cara yang tidak terlalu bias dibandingkan kebanyakan manajer perekrutan. Di Aira, dia membantu membangun chatbot pertama mereka yang dirancang untuk menafsirkan dunia bagi orang buta. Hobson adalah pengagum penuh semangat keterbukaan AI dan orientasi komunitas. Dia memberikan kontribusi aktif untuk proyek open source seperti Keras, scikit-learn, PyBrain, PUGNLP, dan ChatterBot. Dia saat ini terlibat dalam penelitian terbuka dan proyek pendidikan untuk Total Good, termasuk membuat asisten virtual open source. Dia telah menerbitkan banyak artikel, mengajar di AIAA, PyCon,PAIS dan IEEE serta telah memperoleh beberapa hak paten di bidang robotika dan otomasi.
Hannes Max Hapke adalah seorang insinyur listrik yang berubah menjadi insinyur pembelajaran mesin. Di sekolah menengah, ia menjadi tertarik pada jaringan saraf saat mempelajari cara menghitung jaringan saraf di mikrokontroler. Kemudian di perguruan tinggi, ia menerapkan prinsip-prinsip jaringan saraf ke dalam pengelolaan pembangkit listrik energi terbarukan yang efisien. Hannes sangat tertarik dengan otomatisasi pengembangan perangkat lunak dan pipeline machine learning. Dia telah ikut menulis model pembelajaran mendalam dan pipeline pembelajaran mesin untuk industri perekrutan, energi, dan perawatan kesehatan. Hannes telah memberikan presentasi tentang pembelajaran mesin di berbagai konferensi termasuk OSCON, Open Source Bridge dan Hack University.
Cole Howard(Cole Howard) adalah praktisi pembelajaran mesin, praktisi NLP, dan penulis. Seorang pencari pola yang abadi, dia menemukan dirinya di dunia jaringan saraf tiruan. Di antara perkembangannya adalah sistem rekomendasi skala besar untuk perdagangan melalui Internet dan jaringan saraf canggih untuk sistem kecerdasan mesin dimensi ultra-tinggi (jaringan saraf dalam), yang menempati peringkat pertama dalam kompetisi Kaggle. Dia telah memberikan ceramah tentang jaringan saraf konvolusional, jaringan saraf berulang, dan peran mereka dalam pemrosesan bahasa alami di konferensi Open Source Bridge dan Hack University.
Tentang ilustrasi sampul
« -, ». (Balthasar Hacquet) Images and Descriptions of Southwestern and Eastern Wends, Illyrians and Slavs (« - , »), () 2008 . (1739–1815) — , , — , - . .
200 . , , . , . , .
200 . , , . , . , .
»Rincian lebih lanjut tentang buku dapat ditemukan di situs web penerbit
» Daftar Isi
» Kutipan
Untuk Habitants diskon 25% untuk kupon - NLP
Setelah pembayaran untuk versi kertas buku tersebut, sebuah e-book dikirim ke email.