pengantar
Artikel ini menjelaskan algoritme pengurutan gabungan adaptif non-rekursif stabil yang disebut quadsort.
Pertukaran empat kali lipat
Quadsort didasarkan pada pertukaran empat kali lipat. Secara tradisional, sebagian besar algoritme pengurutan didasarkan pada pertukaran biner, di mana dua variabel diurutkan menggunakan variabel sementara ketiga. Biasanya terlihat seperti ini:
if (val[0] > val[1])
{
tmp[0] = val[0];
val[0] = val[1];
val[1] = tmp[0];
}Dalam pertukaran empat kali lipat, pengurutan terjadi menggunakan empat variabel substitusi (swap). Pada langkah pertama, keempat variabel tersebut sebagian diurutkan menjadi empat variabel swap, pada langkah kedua, keempat variabel tersebut diurutkan kembali sepenuhnya menjadi empat variabel asli.
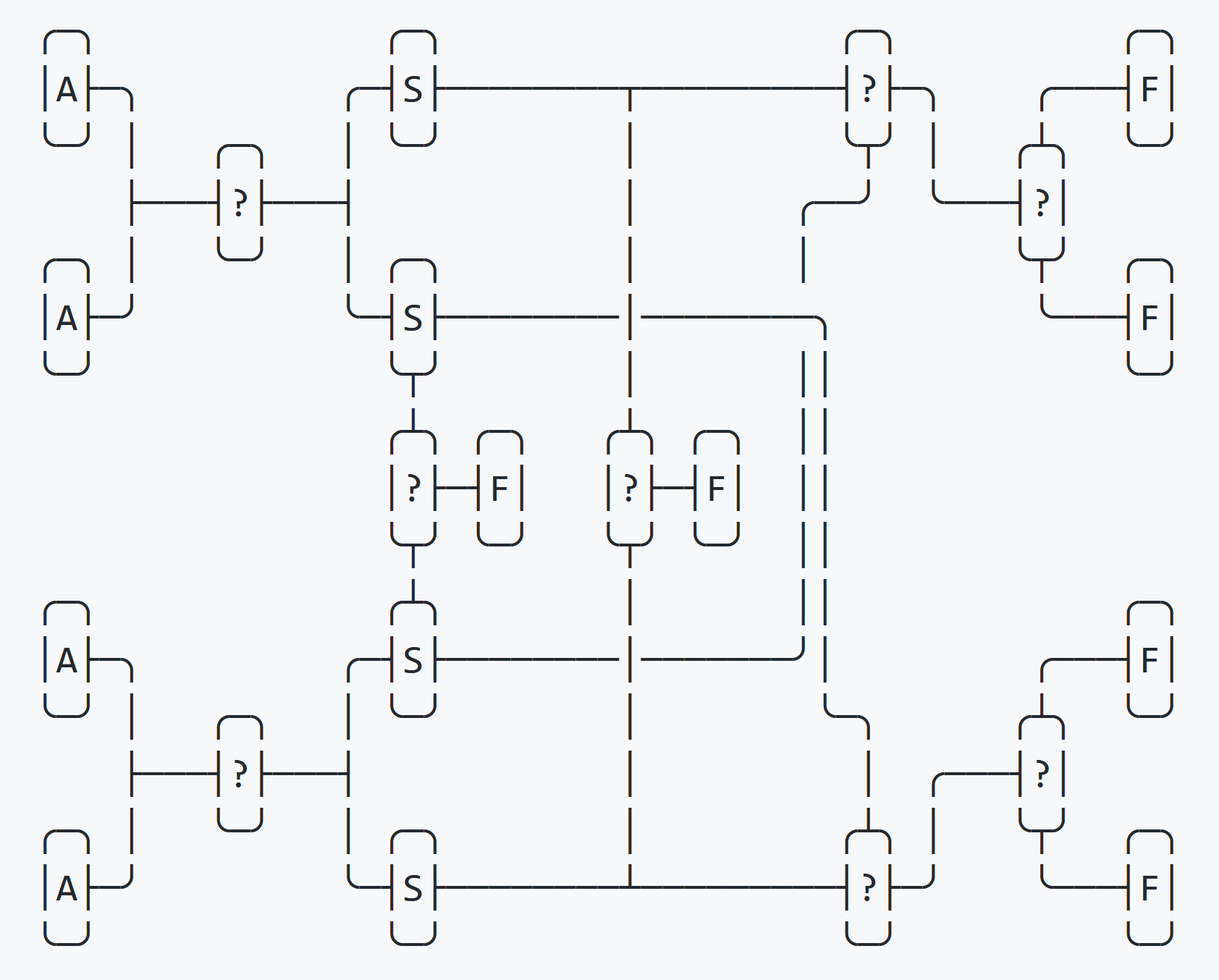
Proses ini ditunjukkan pada diagram di atas.
Setelah putaran pertama pengurutan, cek satu jika menentukan apakah empat variabel swap diurutkan secara berurutan. Jika demikian, pertukaran akan segera berakhir. Ia kemudian memeriksa untuk melihat apakah variabel swap diurutkan dalam urutan terbalik. Jika demikian, pengurutan akan segera berakhir. Jika kedua pengujian gagal, lokasi akhir diketahui dan dua pengujian tersisa untuk menentukan urutan akhir.
Ini menghilangkan satu perbandingan yang tidak perlu untuk urutan yang berurutan. Pada saat yang sama, satu perbandingan tambahan dibuat untuk urutan acak. Namun, di dunia nyata, kami jarang membandingkan data yang benar-benar acak. Jadi, ketika data diurutkan dan tidak berantakan, pergeseran probabilitas ini menguntungkan.
Ada juga peningkatan kinerja secara keseluruhan karena penghapusan swap yang boros. Di C, pertukaran empat kali lipat dasar terlihat seperti ini:
if (val[0] > val[1])
{
tmp[0] = val[1];
tmp[1] = val[0];
}
else
{
tmp[0] = val[0];
tmp[1] = val[1];
}
if (val[2] > val[3])
{
tmp[2] = val[3];
tmp[3] = val[2];
}
else
{
tmp[2] = val[2];
tmp[3] = val[3];
}
if (tmp[1] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[1];
val[2] = tmp[2];
val[3] = tmp[3];
}
else if (tmp[0] > tmp[3])
{
val[0] = tmp[2];
val[1] = tmp[3];
val[2] = tmp[0];
val[3] = tmp[1];
}
else
{
if (tmp[0] <= tmp[2])
{
val[0] = tmp[0];
val[1] = tmp[2];
}
else
{
val[0] = tmp[2];
val[1] = tmp[0];
}
if (tmp[1] <= tmp[3])
{
val[2] = tmp[1];
val[3] = tmp[3];
}
else
{
val[2] = tmp[3];
val[3] = tmp[1];
}
}Jika larik tidak dapat dibagi secara sempurna menjadi empat bagian, ekor 1-3 elemen diurutkan menggunakan pertukaran biner tradisional.
Pertukaran empat kali lipat yang dijelaskan di atas diimplementasikan dalam quadsort.
Penggabungan empat kali lipat
Pada tahap pertama, pertukaran empat kali lipat pra-sortir array menjadi blok empat elemen, seperti dijelaskan di atas.
Tahap kedua menggunakan pendekatan serupa untuk mendeteksi pesanan yang dipesan dan dibalik, tetapi dalam blok yang terdiri dari 4, 16, 64, atau lebih elemen, tahap ini diperlakukan seperti jenis gabungan tradisional.
Ini dapat direpresentasikan sebagai berikut:
main memory: AAAA BBBB CCCC DDDD
swap memory: ABABABAB CDCDCDCD
main memory: ABCDABCDABCDABCDBaris pertama menggunakan pertukaran empat kali lipat untuk membuat empat blok yang masing-masing terdiri dari empat item. Baris kedua menggunakan penggabungan quad untuk digabungkan menjadi dua blok yang masing-masing terdiri dari delapan item yang diurutkan dalam memori swap. Pada baris terakhir, blok-blok tersebut digabungkan kembali ke dalam memori utama, dan kita memiliki satu blok dengan 16 elemen yang diurutkan. Di bawah ini adalah visualisasinya.

Operasi ini sebenarnya membutuhkan penggandaan memori swap. Lebih lanjut tentang ini nanti.
Melewatkan
Perbedaan lainnya adalah karena meningkatnya biaya operasi penggabungan, ada baiknya untuk memeriksa apakah empat blok dalam urutan maju atau mundur.
Jika keempat blok sudah beres, operasi penggabungan akan dilewati, karena tidak ada artinya. Namun, ini memerlukan tambahan if check, dan untuk data yang diurutkan secara acak, ini jika pemeriksaan menjadi semakin tidak mungkin seiring dengan bertambahnya ukuran blok. Untungnya, frekuensi pemeriksaan ini menjadi empat kali lipat setiap siklus, sedangkan manfaat potensial berlipat empat setiap siklus.
Jika keempat blok berada dalam urutan terbalik, pertukaran di tempat yang stabil dilakukan.
Jika hanya dua dari empat blok yang dipesan atau berada dalam urutan terbalik, perbandingan dalam penggabungan itu sendiri tidak diperlukan dan selanjutnya dihilangkan. Data masih perlu disalin ke memori swap, tetapi ini adalah prosedur komputasi yang kurang.
Hal ini memungkinkan algoritme quadsort untuk mengurutkan urutan dalam urutan maju dan mundur menggunakan
nperbandingan, bukan n * log nperbandingan.
Pemeriksaan batas
Masalah lain dengan jenis gabungan tradisional adalah pemborosan sumber daya pada pemeriksaan batas yang tidak perlu. Ini terlihat seperti ini:
while (a <= a_max && b <= b_max)
if (a <= b)
[insert a++]
else
[insert b++]Untuk pengoptimalan, algoritme kami membandingkan elemen terakhir dari urutan A dengan elemen terakhir dari urutan B. Jika elemen terakhir dari urutan A kurang dari elemen terakhir dari urutan B, maka kita tahu bahwa pengujian
b < b_maxakan selalu salah, karena urutan A adalah yang pertama untuk digabungkan sepenuhnya.
Demikian juga, jika elemen terakhir dari urutan A lebih besar dari elemen terakhir dari urutan B, kita tahu bahwa pengujiannya
a < a_maxakan selalu salah. Ini terlihat seperti ini:
if (val[a_max] <= val[b_max])
while (a <= a_max)
{
while (a > b)
[insert b++]
[insert a++]
}
else
while (b <= b_max)
{
while (a <= b)
[insert a++]
[insert b++]
}Ekor fusi
Saat Anda mengurutkan 65 elemen larik, Anda akan mendapatkan larik yang diurutkan 64 elemen dan larik yang diurutkan satu elemen di bagian akhir. Ini tidak akan menghasilkan operasi swap (pertukaran) tambahan jika seluruh urutannya teratur. Bagaimanapun, untuk ini, program harus memilih ukuran array yang optimal (64, 256 atau 1024).
Masalah lainnya adalah ukuran array yang tidak optimal menyebabkan operasi pertukaran yang tidak perlu. Untuk mengatasi kedua masalah ini, prosedur penggabungan empat kali lipat dibatalkan ketika ukuran blok mencapai 1/8 dari ukuran array dan sisa array diurutkan menggunakan penggabungan ekor. Keuntungan utama dari fusi ekor adalah dapat mengurangi volume swap quadsort menjadi n / 2 tanpa mempengaruhi kinerja secara signifikan.
Big O
| Nama | Terbaik | Tengah | Terburuk | Stabil | Penyimpanan |
|---|---|---|---|---|---|
| quadsort | n | n log n | n log n | Iya | n |
Ketika data sudah diurutkan atau diurutkan dalam urutan terbalik, quadsort membuat n perbandingan.
Cache
Karena quadsort menggunakan n / 2 swap, penggunaan cache tidak ideal seperti in-place sort. Namun, pengurutan data acak di tempat menghasilkan pertukaran yang kurang optimal. Berdasarkan tolok ukur saya, quadsort selalu lebih cepat daripada in-place sort, selama array tidak meluap cache L1, yang bisa mencapai 64KB pada prosesor modern.
Wolfsort
Wolfsort adalah algoritme penyortiran radixsort / quadsort hybrid yang meningkatkan kinerja saat bekerja dengan data acak. Ini pada dasarnya adalah bukti konsep yang hanya bekerja dengan unsigned 32 dan 64 bit integer.
Visualisasi
Visualisasi di bawah ini menjalankan empat tes. Tes pertama didasarkan pada distribusi acak, yang kedua pada distribusi menaik, yang ketiga pada distribusi menurun, dan yang keempat pada distribusi menaik dengan ekor acak.
Setengah bagian atas menunjukkan swap dan bagian bawah menunjukkan memori utama. Warna bervariasi untuk operasi lewati, tukar, gabung, dan salin.
Tolok ukur: quadsort, std :: stable_sort, timsort, pdqsort, dan wolfsort
Tolok ukur berikut ini dijalankan pada konfigurasi gcc WSL versi 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). Kode sumber dikompilasi oleh tim
g++ -O3 quadsort.cpp. Setiap pengujian dijalankan seratus kali dan hanya pengujian terbaik yang dilaporkan.
Absis adalah waktu eksekusi.
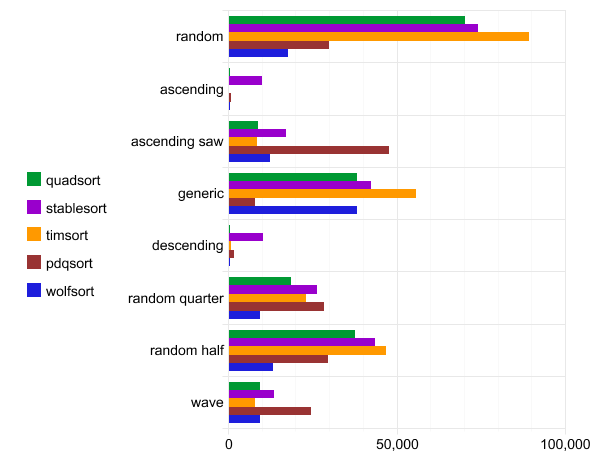
Lembar data Quadsort, std :: stable_sort, timsort, pdqsort dan wolfsort
| Nama | Elemen | Sebuah tipe | Terbaik | Tengah | Perbandingan | Memesan |
|---|---|---|---|---|---|---|
| quadsort | 1.000.000 | i32 | 0,070469 | 0,070635 | pesanan acak | |
| stablesort | 1000000 | i32 | 0.073865 | 0.074078 | ||
| timsort | 1000000 | i32 | 0.089192 | 0.089301 | ||
| pdqsort | 1000000 | i32 | 0.029911 | 0.029948 | ||
| wolfsort | 1000000 | i32 | 0.017359 | 0.017744 | ||
| quadsort | 1000000 | i32 | 0.000485 | 0.000511 | ||
| stablesort | 1000000 | i32 | 0.010188 | 0.010261 | ||
| timsort | 1000000 | i32 | 0.000331 | 0.000342 | ||
| pdqsort | 1000000 | i32 | 0.000863 | 0.000875 | ||
| wolfsort | 1000000 | i32 | 0.000539 | 0.000579 | ||
| quadsort | 1000000 | i32 | 0.008901 | 0.008934 | () | |
| stablesort | 1000000 | i32 | 0.017093 | 0.017275 | () | |
| timsort | 1000000 | i32 | 0.008615 | 0.008674 | () | |
| pdqsort | 1000000 | i32 | 0.047785 | 0.047921 | () | |
| wolfsort | 1000000 | i32 | 0.012490 | 0.012554 | () | |
| quadsort | 1000000 | i32 | 0.038260 | 0.038343 | ||
| stablesort | 1000000 | i32 | 0.042292 | 0.042388 | ||
| timsort | 1000000 | i32 | 0.055855 | 0.055967 | ||
| pdqsort | 1000000 | i32 | 0.008093 | 0.008168 | ||
| wolfsort | 1000000 | i32 | 0.038320 | 0.038417 | ||
| quadsort | 1000000 | i32 | 0.000559 | 0.000576 | ||
| stablesort | 1000000 | i32 | 0.010343 | 0.010438 | ||
| timsort | 1000000 | i32 | 0.000891 | 0.000900 | ||
| pdqsort | 1000000 | i32 | 0.001882 | 0.001897 | ||
| wolfsort | 1000000 | i32 | 0.000604 | 0.000625 | ||
| quadsort | 1000000 | i32 | 0.006174 | 0.006245 | ||
| stablesort | 1000000 | i32 | 0.014679 | 0.014767 | ||
| timsort | 1000000 | i32 | 0.006419 | 0.006468 | ||
| pdqsort | 1000000 | i32 | 0.016603 | 0.016629 | ||
| wolfsort | 1000000 | i32 | 0.006264 | 0.006329 | ||
| quadsort | 1000000 | i32 | 0.018675 | 0.018729 | ||
| stablesort | 1000000 | i32 | 0.026384 | 0.026508 | ||
| timsort | 1000000 | i32 | 0.023226 | 0.023395 | ||
| pdqsort | 1000000 | i32 | 0.028599 | 0.028674 | ||
| wolfsort | 1000000 | i32 | 0.009517 | 0.009631 | ||
| quadsort | 1000000 | i32 | 0.037593 | 0.037679 | ||
| stablesort | 1000000 | i32 | 0.043755 | 0.043899 | ||
| timsort | 1000000 | i32 | 0.047008 | 0.047112 | ||
| pdqsort | 1000000 | i32 | 0.029800 | 0.029847 | ||
| wolfsort | 1000000 | i32 | 0.013238 | 0.013355 | ||
| quadsort | 1000000 | i32 | 0.009605 | 0.009673 | ||
| stablesort | 1000000 | i32 | 0.013667 | 0.013785 | ||
| timsort | 1000000 | i32 | 0.007994 | 0.008138 | ||
| pdqsort | 1000000 | i32 | 0.024683 | 0.024727 | ||
| wolfsort | 1000000 | i32 | 0.009642 | 0.009709 |
Perlu dicatat bahwa pdqsort bukanlah jenis yang stabil, sehingga ia bekerja lebih cepat dengan data dalam urutan normal (urutan umum).
Benchmark berikutnya dijalankan pada WSL gcc versi 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). Kode sumber dikompilasi oleh tim
g++ -O3 quadsort.cpp. Setiap pengujian dijalankan seratus kali dan hanya pengujian terbaik yang dilaporkan. Ini mengukur kinerja pada array mulai dari 675 hingga 100.000 elemen.
Sumbu X dari grafik di bawah ini adalah kardinalitas, sumbu Y adalah waktu eksekusi.

Lembar data Quadsort, std :: stable_sort, timsort, pdqsort dan wolfsort
| quadsort | 100000 | i32 | 0.005800 | 0.005835 | ||
| stablesort | 100000 | i32 | 0.006092 | 0.006122 | ||
| timsort | 100000 | i32 | 0.007605 | 0.007656 | ||
| pdqsort | 100000 | i32 | 0.002648 | 0.002670 | ||
| wolfsort | 100000 | i32 | 0.001148 | 0.001168 | ||
| quadsort | 10000 | i32 | 0.004568 | 0.004593 | ||
| stablesort | 10000 | i32 | 0.004813 | 0.004923 | ||
| timsort | 10000 | i32 | 0.006326 | 0.006376 | ||
| pdqsort | 10000 | i32 | 0.002345 | 0.002373 | ||
| wolfsort | 10000 | i32 | 0.001256 | 0.001274 | ||
| quadsort | 5000 | i32 | 0.004076 | 0.004086 | ||
| stablesort | 5000 | i32 | 0.004394 | 0.004420 | ||
| timsort | 5000 | i32 | 0.005901 | 0.005938 | ||
| pdqsort | 5000 | i32 | 0.002093 | 0.002107 | ||
| wolfsort | 5000 | i32 | 0.000968 | 0.001086 | ||
| quadsort | 2500 | i32 | 0.003196 | 0.003303 | ||
| stablesort | 2500 | i32 | 0.003801 | 0.003942 | ||
| timsort | 2500 | i32 | 0.005296 | 0.005322 | ||
| pdqsort | 2500 | i32 | 0.001606 | 0.001661 | ||
| wolfsort | 2500 | i32 | 0.000509 | 0.000520 | ||
| quadsort | 1250 | i32 | 0.001767 | 0.001823 | ||
| stablesort | 1250 | i32 | 0.002812 | 0.002887 | ||
| timsort | 1250 | i32 | 0.003789 | 0.003865 | ||
| pdqsort | 1250 | i32 | 0.001036 | 0.001325 | ||
| wolfsort | 1250 | i32 | 0.000534 | 0.000655 | ||
| quadsort | 675 | i32 | 0.000368 | 0.000592 | ||
| stablesort | 675 | i32 | 0.000974 | 0.001160 | ||
| timsort | 675 | i32 | 0.000896 | 0.000948 | ||
| pdqsort | 675 | i32 | 0.000489 | 0.000531 | ||
| wolfsort | 675 | i32 | 0.000283 | 0.000308 |
Tolok ukur: quadsort dan qsort (mergesort)
Benchmark berikutnya dijalankan pada WSL gcc versi 7.4.0 (Ubuntu 7.4.0-1ubuntu1 ~ 18.04.1). Kode sumber dikompilasi oleh tim
g++ -O3 quadsort.cpp. Setiap pengujian dijalankan seratus kali dan hanya pengujian terbaik yang dilaporkan.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)MO menunjukkan jumlah perbandingan yang dilakukan pada 1 juta item.
Tolok ukur di atas membandingkan quadsort dengan glibc qsort () melalui antarmuka tujuan umum yang sama dan tanpa keuntungan tidak adil yang diketahui seperti sebaris.
random order: 635, 202, 47, 229, etc
ascending order: 1, 2, 3, 4, etc
uniform order: 1, 1, 1, 1, etc
descending order: 999, 998, 997, 996, etc
wave order: 100, 1, 102, 2, 103, 3, etc
stable/unstable: 100, 1, 102, 1, 103, 1, etc
random range: time to sort 1000 arrays ranging from size 0 to 999 containing random dataTolok ukur: quadsort dan qsort (quicksort)
Tes khusus ini dilakukan menggunakan implementasi qsort () Cygwin, yang menggunakan quicksort. Kode sumber dikompilasi oleh tim
gcc -O3 quadsort.c. Setiap pengujian dijalankan ratusan kali, hanya proses terbaik yang dilaporkan.
quadsort: sorted 1000000 i32s in 0.119437 seconds. MO: 19308657 ( )
qsort: sorted 1000000 i32s in 0.133077 seconds. MO: 21083741 ( )
quadsort: sorted 1000000 i32s in 0.002071 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.007265 seconds. MO: 3000004 ()
quadsort: sorted 1000000 i32s in 0.019239 seconds. MO: 4007580 ( )
qsort: sorted 1000000 i32s in 0.071322 seconds. MO: 20665677 ( )
quadsort: sorted 1000000 i32s in 0.076605 seconds. MO: 19242642 ( )
qsort: sorted 1000000 i32s in 0.038389 seconds. MO: 6221917 ( )
quadsort: sorted 1000000 i32s in 0.002305 seconds. MO: 999999 ()
qsort: sorted 1000000 i32s in 0.009659 seconds. MO: 4000015 ()
quadsort: sorted 1000000 i32s in 0.022940 seconds. MO: 9519209 ( )
qsort: sorted 1000000 i32s in 0.042135 seconds. MO: 13152042 ( )
quadsort: sorted 1000000 i32s in 0.034456 seconds. MO: 6787656 ( )
qsort: sorted 1000000 i32s in 0.098691 seconds. MO: 20584424 ( )
quadsort: sorted 1000000 i32s in 0.066240 seconds. MO: 11383441 ( )
qsort: sorted 1000000 i32s in 0.118086 seconds. MO: 20572142 ( )
quadsort: sorted 1000000 i32s in 0.038116 seconds. MO: 15328606 ( )
qsort: sorted 1000000 i32s in 4.471858 seconds. MO: 1974047339 ( )
quadsort: sorted 1000000 i32s in 0.060989 seconds. MO: 15328606 ()
qsort: sorted 1000000 i32s in 0.043175 seconds. MO: 10333679 ()
quadsort: sorted 1023 i32s in 0.016126 seconds. (random 1-1023)
qsort: sorted 1023 i32s in 0.033132 seconds. (random 1-1023)Dalam tolok ukur ini, menjadi jelas mengapa quicksort lebih disukai daripada penggabungan tradisional, quicksort melakukan lebih sedikit perbandingan untuk data dalam urutan menaik, terdistribusi seragam, dan untuk data dalam urutan menurun. Namun, di sebagian besar tes, kinerjanya lebih buruk daripada quadsort. Quicksort juga menunjukkan kecepatan pengurutan yang sangat lambat untuk data berurutan gelombang. Uji data acak menunjukkan bahwa quadsort lebih dari dua kali lebih cepat saat mengurutkan array kecil.
Quicksort lebih cepat pada pengujian tujuan umum dan stabil, tetapi hanya karena ini adalah algoritme yang tidak stabil.
Lihat juga: