
Pada tahun 2020, pembelajaran mesin di platform seluler bukan lagi merupakan inovasi revolusioner. Integrasi fitur pintar ke dalam aplikasi telah menjadi praktik standar.
Untungnya, ini tidak berarti Apple telah berhenti mengembangkan teknologi inovatif.
Dalam postingan kali ini, saya akan membagikan secara singkat berita terkait platform Core ML dan AI lainnya serta teknologi pembelajaran mesin di ekosistem Apple.
Core ML
Tahun lalu, platform Core ML menerima pembaruan besar. Tahun ini, semuanya jauh lebih sederhana: beberapa jenis lapisan baru telah ditambahkan, dukungan untuk model enkripsi, dan kemampuan untuk mengirim pembaruan model ke CloudKit.
Sepertinya keputusan telah dibuat untuk menghapus nomor versi. Setelah update tahun lalu, platform tersebut kemudian dikenal sebagai Core ML 3, tetapi sekarang menggunakan nama Core ML tanpa nomor versi. Namun, paket coremltools telah diupdate ke versi 4.
Catatan . Spesifikasi internal mlmodel sekarang adalah versi 5 yang artinya model baru akan muncul di Netron dengan nama "Core ML v5".
Jenis lapisan baru di Core ML
Lapisan berikut telah ditambahkan:
Convolution3DLayer, Pooling3DLayer, GlobalPooling3DLayer: — Vision ( Core ML - , ).OneHotLayer: .ClampedReLULayer: ReLU ( ReLU6).- ArgSortLayer: . . , GatherLayer, argsort.
CumSumLayer: .SliceBySizeLayer: Beberapa jenis lapisan terbagi telah tersedia di Core ML. Lapisan ini memungkinkan Anda untuk melewatkan tensor yang berisi indeks tempat partisi akan dimulai. Pada saat yang sama, ukuran sektor selalu tetap.
Jenis lapisan ini dapat digunakan mulai dari versi 5, yaitu di iOS 14 dan macOS 11.0 atau lebih baru.
Peningkatan lain yang berguna: operasi terkuantisasi 8-bit untuk lapisan berikut:
InnerProductLayerBatchedMatMulLayer
Di versi Core ML sebelumnya, bobot dikuantisasi, tetapi setelah memuat model, bobot diubah kembali ke format floating point. Fitur baru ini
int8DynamicQuantizememungkinkan bobot untuk disimpan sebagai nilai integer 8-bit dan untuk melakukan penghitungan aktual menggunakan integer juga.
Perhitungan menggunakan INT8 bisa jauh lebih cepat daripada operasi floating point. Ini memberikan beberapa keuntungan pada CPU, tetapi tidak pasti apakah kinerja GPU akan meningkat, karena operasi floating point sangat efisien untuk mereka. Mungkin, dalam pembaruan Neural Engine di masa mendatang, dukungan bawaan untuk operasi INT8 akan diterapkan (bagaimanapun juga, Apple baru-baru ini mengakuisisi Xnor.ai ...).
Di sisi CPU, Core ML sekarang juga dapat menggunakan floating point 16-bit, bukan 32-bit (pada A11 Bionic dan yang lebih baru). Seperti yang kita bahas dalam video Jelajahi komputasi numerik di Swift , Float16 sekarang menjadi tipe data kelas pertama Swift. Dengan dukungan asli untuk operasi floating point 16-bit, Core ML dapat menggandakan kecepatan!
Catatan . Dalam Core ML, tipe data Float16 sudah digunakan pada GPU dan Neural Engine, sehingga perbedaannya hanya akan terlihat saat digunakan pada CPU.
Perubahan (kecil) lainnya:
UpsampleLayer. BILINEAR ( align-corners). , , .-
ReorganizeDataLayerParamsPIXEL_SHUFFLE. , . , . -
SliceStaticLayerSliceDynamicLayersqueezeMasks, . -
TileLayer, .
Tampaknya tidak ada perubahan terkait pembelajaran lokal di perangkat: masih hanya lapisan konvolusional yang terhubung sepenuhnya dan didukung. Kelas
MLParameterKeydi CoreML.framework sekarang berisi parameter konfigurasi untuk pengoptimal RMSprop , tetapi peningkatan ini belum disertakan di NeuralNetwork.proto . Mungkin itu akan ditambahkan dalam versi beta berikutnya. Jenis model baru
berikut telah ditambahkan :
VisionFeaturePrint.Object- Unit ekstraksi fitur dioptimalkan untuk pengenalan objek.
SerializedModel... Saya tidak tahu persis untuk apa ini. Ini adalah definisi "pribadi" dan "dapat berubah tanpa pemberitahuan atau kewajiban." Mungkin ini cara Apple menanamkan format model berpemilik ke dalam mlmodel?
Memposting pembaruan model ke CloudKit

Komponen Core ML baru ini memungkinkan Anda mengupdate model secara terpisah dari aplikasi.
Daripada mengupdate seluruh aplikasi, Anda cukup memuat instance yang di-deploy dengan versi baru mlmodel. Sejujurnya, ide ini bukanlah hal baru, dan beberapa vendor pihak ketiga telah mengembangkan SDK yang sesuai. Juga tidak sulit untuk membuat paket seperti itu sendiri. Keuntungan dari solusi Apple dalam hal ini adalah kemampuan untuk menghosting model di Apple Cloud .
Karena aplikasi dapat memiliki banyak model, konsep baru dari kumpulan model memungkinkan Anda menggabungkan model dalam satu paket sehingga aplikasi dapat memperbarui semuanya pada saat yang bersamaan. Koleksi tersebut dapat dibuat menggunakan dasbor CloudKit.
Aplikasi menggunakan kelas untuk mengunduh dan mengelola pembaruan model
MLModelCollection. The WWDC Video menunjukkan potongan kode untuk menyelesaikan tugas ini.
Untuk mempersiapkan model Core ML untuk penerapan, tombol Buat Arsip Model sekarang tersedia di Xcode. Mengkliknya akan menulis ke file .mlarchive . Versi model ini dapat dikirimkan ke dasbor CloudKit dan kemudian ditambahkan ke koleksi model (mlarchive terlihat seperti arsip ZIP biasa dengan konten folder mlmodelc ditambahkan).
Sangat mudah bahwa Anda dapat menyebarkan koleksi model yang berbeda ke pengguna yang berbeda. Misalnya, kamera iPhone berbeda dari kamera iPad, jadi Anda mungkin perlu membuat dua versi model dan mengirimkan satu ke pengguna iPhone dan yang lainnya ke pengguna iPad.
Anda dapat menentukan aturan penyesuaian untuk berbagai kelas perangkat (iPhone, iPad, TV, Watch), sistem operasi yang berbeda dan versinya, kode wilayah, kode bahasa, dan versi aplikasi.
Tampaknya tidak ada mekanisme untuk membagi pengguna ke dalam grup berdasarkan kriteria lain, seperti pengujian A / B untuk pembaruan model atau penyesuaian untuk jenis perangkat tertentu - iPhone X atau versi lebih lama. Namun, ini masih dapat dilakukan secara manual dengan membuat koleksi dengan nama berbeda dan kemudian secara eksplisit meminta dari
MLModelCollectionmenyediakan koleksi yang sesuai dengan nama yang ditentukan pada waktu proses.
Menerapkan versi baru suatu model tidak selalu cepat . Pada titik tertentu, aplikasi mendeteksi model baru yang tersedia dan secara otomatis mendownload dan menempatkannya di lingkungan pengujian aplikasi. Namun, Anda tidak diberi kemampuan untuk menentukan di mana dan bagaimana ini terjadi: Core ML dapat mengunduh di latar belakang, misalnya, saat Anda tidak sedang menggunakan ponsel.
Karenanya, dalam semua kasus, disarankan untuk menambahkan model bawaan ke aplikasi sebagai cadangan - misalnya, model universal yang mendukung iPhone dan iPad.
Meskipun solusi praktis ini memungkinkan pengguna untuk tidak khawatir tentang model hosting mandiri, perlu diingat bahwa aplikasi Anda sekarang menggunakan CloudKit. Seperti yang saya pahami, koleksi model diperhitungkan terhadap kuota penyimpanan total, dan beban model diperhitungkan terhadap kuota lalu lintas jaringan.
Lihat juga:
- Menerapkan Model dan Mengamankan Core ML (Video WWDC)
- Membuat dan menerapkan koleksi model
- Mengambil Koleksi Model yang Diperluas
Catatan . Sayangnya, kemampuan pembaruan baru menggunakan CloudKit cukup sulit untuk digabungkan dengan personalisasi model lokal. Tidak ada cara mudah untuk mentransfer pengetahuan yang diperoleh dari model yang dipersonalisasi ke model baru atau menggabungkannya.
Mengenkripsi model
Hingga saat ini, setiap penyerang dapat dengan mudah mencuri model Core ML Anda dan mengintegrasikannya ke dalam aplikasi mereka sendiri. Dimulai dengan iOS 14 / macOS 11.0, Core ML mendukung enkripsi otomatis dan dekripsi model, membatasi akses penyerang ke folder mlmodelc Anda. Enkripsi dapat digunakan bersama dengan fitur penerapan baru melalui CloudKit atau secara terpisah.

Xcode mengenkripsi model yang dikompilasi ( mlmodelc ), bukan mlmodel asli. Model selalu dienkripsi di perangkat pengguna. Dan hanya jika aplikasi membuat instance model, Core ML secara otomatis mendekripsinya. Versi model yang didekripsi hanya ada di memori dan tidak disimpan sebagai file.
Pertama, Anda sekarang membutuhkan kunci enkripsi. Kabar baiknya adalah Anda tidak perlu mengelola kunci ini sendiri! Tombol Buat Kunci Enkripsi sekarang tersedia di Penampil Model Core ML Xcode(Buat kunci enkripsi). Saat Anda mengklik tombol ini, Xcode membuat kunci enkripsi baru dan mengaitkannya dengan akun tim pengembangan Apple Anda. Anda tidak harus berurusan dengan permintaan penandatanganan sertifikat dan kunci akses fisik.
Prosedur ini membuat file .mlmodelkey baru . Kuncinya disimpan di server Apple, namun Anda juga mendapatkan salinan lokal untuk mengenkripsi model di Xcode. Anda tidak perlu menyematkan kunci enkripsi ini ke dalam aplikasi, terutama karena Anda tidak perlu melakukannya!
Untuk mengenkripsi model Core ML, Anda dapat menambahkan flag compiler
--encrypt YourModel.mlmodelkeyuntuk model tersebut. Dan jika Anda berencana untuk menerapkan model menggunakan CloudKit, Anda perlu menentukan kunci enkripsi saat membuat arsip model.
Untuk mendekripsi model setelah aplikasi membuatnya, Core ML perlu mengambil kunci enkripsi dari server Apple melalui jaringan . Ini tentu saja membutuhkan koneksi jaringan. Core ML hanya melakukan prosedur ini saat pertama kali Anda menggunakan model.
Jika tidak ada koneksi jaringan dan kunci enkripsi belum dimuat, aplikasi tidak akan dapat membuat contoh model Core ML. Untuk alasan ini, disarankan untuk menggunakan fungsi baru
YourModel.load(). Ini berisi penangan akhir yang memungkinkan Anda menanggapi kesalahan unduhan. Misalnya, kode kesalahan modelKeyFetchmengatakan bahwa Core ML tidak dapat mengunduh kunci enkripsi dari server Apple.
Ini adalah fitur yang sangat berguna jika Anda khawatir seseorang akan mencuri teknologi Anda yang telah dipatenkan. Plus, mudah untuk diintegrasikan ke dalam aplikasi Anda.
Lihat juga:
- Menerapkan Model dan Mengamankan Core ML (Video WWDC)
- Menghasilkan kunci enkripsi model
- Mengenkripsi model dalam aplikasi
Catatan . Menurut informasi yang diberikan dalam posting forum pengembang ini , model terenkripsi tidak mendukung personalisasi lokal. Kedengarannya masuk akal.
CoreML.framework
API iOS untuk bekerja dengan model Core ML tidak banyak berubah. Namun saya ingin mencatat beberapa poin menarik.
Satu-satunya kelas baru di sini adalah kelas
MLModelCollectionyang dimaksudkan untuk diterapkan dengan CloudKit.
Seperti yang telah Anda ketahui, saat Anda menambahkan file mlmodel ke proyek Anda, Xcode secara otomatis menghasilkan file sumber Swift atau Objective-C yang berisi kelas untuk mempermudah bekerja dengan model. Anda dapat melihat beberapa perubahan di kelas yang dihasilkan ini:
-
init(). ,let model = YourModel().YourModel(configuration:)YourModel.load(), (, ). - ,
CVPixelBufferYourModelInput,CGImageURL-, PNG- JPG-, . ,cropAndScalecropRect. , , .
Ada peringatan baru dalam dokumentasi MLModel :
Gunakan contoh MLModel hanya dalam satu utas atau satu antrian kirim. Untuk melakukan ini, Anda dapat membuat serialisasi panggilan metode ke model, atau membuat instance model terpisah untuk setiap thread dan antrian pengiriman.
Oh maafkan saya. Tampak bagi saya bahwa di dalam MLModel antrian berurutan digunakan untuk memproses permintaan, tetapi saya bisa saja salah - atau ada yang berubah. Bagaimanapun, yang terbaik adalah tetap berpegang pada rekomendasi ini di masa mendatang.
The
MLMultiArraydilaksanakan initializer baruinit(concatenating:axis:dataType:), yang membuat multi-array baru dengan menggabungkan beberapa multi-array yang sudah ada. Semuanya harus memiliki bentuk yang sama kecuali untuk sumbu yang ditentukan di mana penyatuan dilakukan. Sepertinya fitur ini ditambahkan secara khusus untuk membuat prediksi dari data video, seperti pada model pengklasifikasi tindakan baru di Create ML. Nyaman!
Catatan . Pencacahan
MLMultiArrayDataTypesekarang berisi properti statis .floatdan .float64. Saya tidak tahu persis untuk apa, karena pencacahan ini sudah memiliki properti .float32dan .double. Bug beta?
Penampil Model Xcode
Xcode sekarang menampilkan lebih banyak informasi tentang model, seperti label kelas dan metadata kustom yang ditambahkan. Ini juga menampilkan statistik tentang jenis lapisan dalam model.
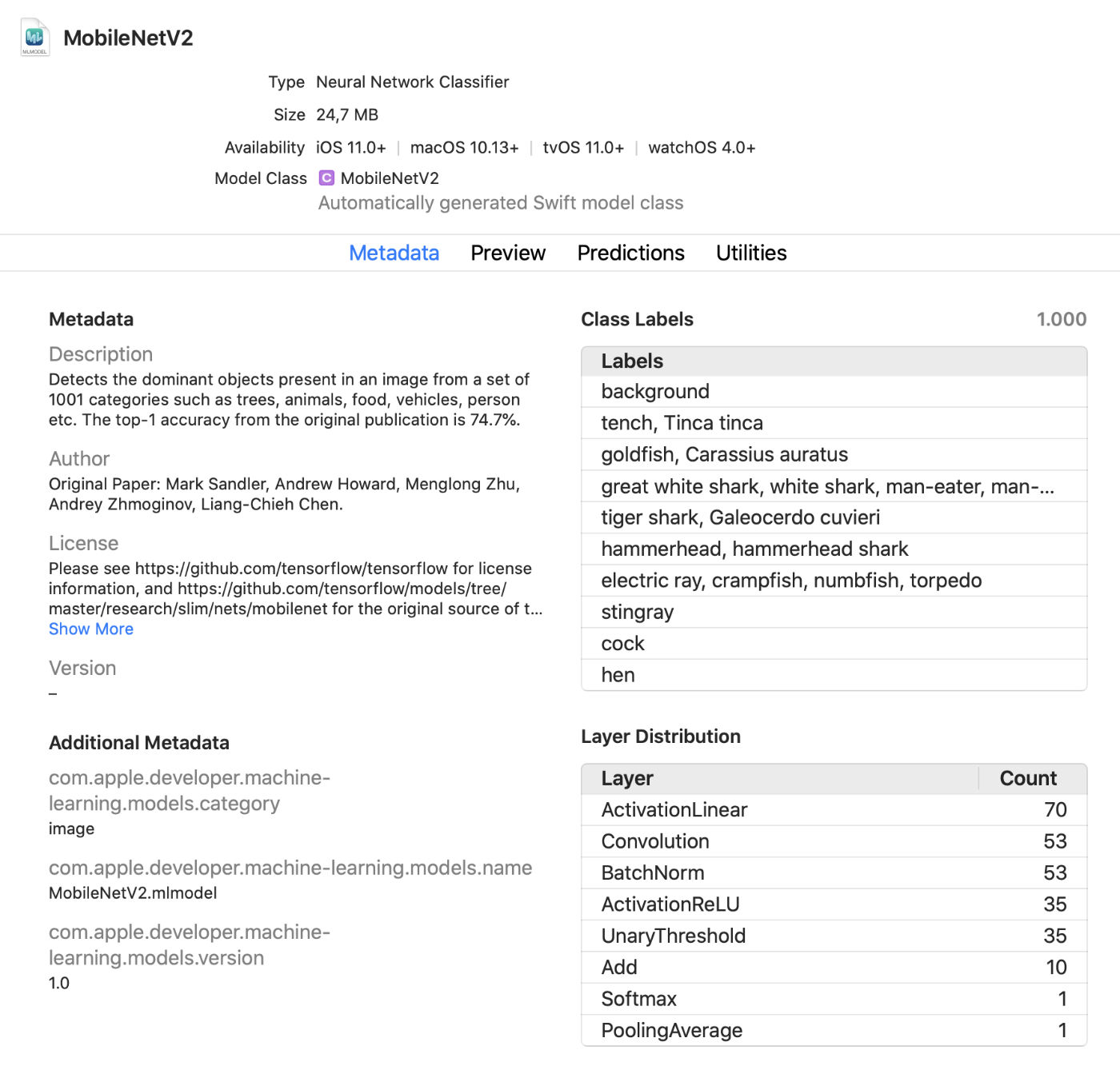
Ini adalah penampil langsung praktis yang memungkinkan Anda membuat perubahan pada model dalam mode pengujian tanpa menjalankan aplikasi. Anda dapat menarik gambar, video, atau teks ke dalam jendela pratinjau ini dan segera melihat prediksi model. Pembaruan hebat!
Selain itu, Anda sekarang dapat menggunakan model Core ML dalam lingkungan interaktif . Xcode secara otomatis menghasilkan kelas untuk ini, yang dapat Anda gunakan secara normal. Ini adalah cara lain untuk menguji model secara interaktif sebelum menambahkannya ke aplikasi.
coremltools 4
Meskipun membuat model Anda sendiri untuk project sederhana nyaman dengan Create ML, TensorFlow dan PyTorch lebih umum digunakan untuk pelatihan. Untuk menggunakan model seperti itu di Core ML, Anda harus mengonversinya terlebih dahulu ke format mlmodel. Untuk apa kotak alat coremltools digunakan.
Berita bagus: dokumentasinya jauh lebih baik . Saya menganjurkan agar Anda membiasakan diri dengannya. Mudah-mudahan, manual pengguna akan diperbarui secara berkala karena dokumentasinya tidak selalu mutakhir di masa lalu.
Catatan . Sayangnya, sampel notebook Jupyter tidak ada. Mereka sekarang disertakan dalam manual pengguna, tetapi tidak sebagai notebook.
The cara model transformasi telah berubah secara dramatis... Pengonversi jaringan neural yang digunakan sebelumnya sudah usang dan telah diganti dengan versi yang lebih baru dan lebih fleksibel.
Ada tiga jenis konverter yang tersedia saat ini:
- Konverter modern untuk TensorFlow (1.x dan 2.x), tf.keras, dan PyTorch. Semua konverter ini didasarkan pada teknologi yang sama dan menggunakan apa yang disebut bahasa model perantara (MIL). Anda tidak perlu lagi menggunakan tfcoreml atau onnx-coreml untuk model seperti itu.
- Konverter lama untuk jaringan saraf Keras 1.x, Caffe, dan ONNX. Konverter khusus disediakan untuk masing-masingnya. Pengembangan lebih lanjut telah dihentikan, dan hanya perbaikan yang direncanakan akan dirilis di masa mendatang. Tidak lagi disarankan menggunakan ONNX untuk mengonversi model PyTorch.
- Pengonversi untuk model jaringan non-neural seperti scikit-learn dan XGBoost.
API konversi seragam baru digunakan untuk mengubah model TensorFlow 1.x, 2.x, PyTorch, atau tf.keras . Ini diterapkan sebagai berikut:
import coremltools as ct
class_labels = [ "cat", "dog" ]
image_input = ct.ImageType(shape=(1, 224, 224, 3),
bias=[-1, -1, -1],
scale=2/255.)
model = ct.convert(
keras_model,
inputs=[ image_input ],
classifier_config=ct.ClassifierConfig(class_labels)
)
model.save("YourModel.mlmodel")
Fungsi ini
ct.convert()memeriksa file model untuk menentukan formatnya dan kemudian secara otomatis memilih konverter yang sesuai. Argumennya sedikit berbeda dari yang digunakan sebelumnya: argumen pra-pemrosesan diteruskan menggunakan objek ImageType, label pengklasifikasi diteruskan menggunakan objek , ClassifierConfigdan seterusnya.
API transformasi baru mengubah model menjadi representasi perantara - yang disebut. MIL . Saat ini tersedia konverter untuk mengonversi TensorFlow 1.x ke MIL, TensorFlow 2.x ke MIL (termasuk tf.keras) dan PyTorch ke MIL. Jika platform pembelajaran mendalam baru mendapatkan popularitas, ia akan menerima konverternya sendiri ke MIL.

Setelah mengonversi model ke format MIL, itu dapat dioptimalkan sesuai dengan aturan umum, misalnya, menghapus operasi yang tidak perlu atau menggabungkan beberapa lapisan berbeda. Model tersebut kemudian diubah dari MIL ke format mlmodel.
Saya belum mempelajari semua ini secara mendetail, tetapi pendekatan baru ini memberi saya harapan bahwa coremtools 4 akan dapat membuat file mlmodel yang lebih efisien daripada sebelumnya - terutama untuk grafik TF 2.x.
Di MIL, saya terutama menyukai kemampuan konverter untuk menangani lapisan yang belum dianalisis . Jika model Anda berisi lapisan yang tidak didukung secara langsung di Core ML, Anda mungkin perlu membaginya menjadi operasi MIL yang lebih sederhana seperti perkalian matriks atau operasi aritmatika lainnya.
Setelah itu, konverter akan dapat menggunakan apa yang disebut "operasi gabungan" untuk semua lapisan jenis ini. Ini jauh lebih mudah daripada menambahkan operasi yang tidak didukung menggunakan lapisan khusus, meskipun itu memungkinkan. Dokumentasi memberikan contoh yang baik untuk menggunakan operasi gabungan tersebut.
Lihat juga:
Platform Apple Lain yang Menggunakan Pembelajaran Mesin
Beberapa kerangka kerja tingkat tinggi lainnya di iOS dan macOS SDK juga digunakan untuk tugas pembelajaran mesin. Mari kita lihat apa yang baru di area ini.
Penglihatan
Platform visi komputer Vision telah menerima sejumlah fungsi baru.
Platform Vision telah menggunakan model untuk mengenali wajah, fitur khas, dan tubuh manusia. Versi baru menambahkan fitur-fitur berikut:
Pengenalan posisi tangan (
VNDetectHumanHandPoseRequest)
Pengenalan pose beberapa orang (
VNDetectHumanBodyPoseRequest)
Sangat bagus bahwa Apple telah memasukkan fungsi pengenalan pose di OS. Beberapa model open source mendukung fitur ini, tetapi mereka tidak seefisien atau secepat itu. Solusi komersial itu mahal. Alat pengenalan pose berkualitas tinggi sekarang tersedia secara gratis!
Sekarang, berbeda dengan melihat gambar statis, lebih banyak perhatian diberikanpengenalan objek pada rekaman video baik offline maupun real time. Untuk kenyamanan, Anda dapat menggunakan objek
CMSampleBufferlangsung dari kamera menggunakan penangan permintaan.
Juga,
VNImageBasedRequestsubclass telah ditambahkan ke kelas VNStatefulRequest, yang bertanggung jawab untuk konfirmasi cepat dari penemuan objek yang diinginkan. Berbeda dengan kelas standar, VNImageBasedRequestia menggunakan kembali kueri stateful yang mencakup banyak bingkai. Permintaan ini melakukan analisis setiap N frame video.
Setelah objek pencarian ditemukan, penangan terakhir dipanggil, berisi objek
VNObservation, yang sekarang memiliki properti timeRangeyang menunjukkan waktu mulai dan berhenti pengamatan dalam video.
Kelas
VNStatefulRequesttidak digunakan secara langsung . Ini adalah kelas dasar abstrak dan saat ini hanya disubkelas oleh kueri VNDetectTrajectoriesRequestuntuk tujuan pengenalan jalur. Hal ini memungkinkan pengenalan bentuk yang bergerak di sepanjang jalur parabola, seperti saat melempar atau menendang bola (ini tampaknya satu-satunya tugas terkait video bawaan saat ini).
Untuk analisis video offline, Anda dapat menggunakan
VNVideoProcessor.Objek ini menambahkan URL ke video lokal dan membuat satu atau beberapa permintaan Vision setiap N frame atau N detik.
Salah satu teknik penglihatan komputer tradisional yang paling penting untuk menganalisis rekaman video adalah aliran optik... Kueri sekarang tersedia di Vision
VNGenerateOpticalFlowRequestyang menghitung arah pergerakan setiap piksel dari satu bingkai ke bingkai lainnya (aliran optik padat). Akibatnya, sebuah objek dibuat VNPixelBufferObservationberisi gambar baru, di mana setiap piksel sesuai dengan dua nilai floating point 32-bit atau 16-bit.
Selain itu, kueri baru telah ditambahkan
VNDetectContoursRequestuntuk mengenali garis besar objek dalam gambar. Jalur tersebut dikembalikan sebagai jalur vektor. VNGeometryUtilsmenyediakan alat bantu untuk pemrosesan lebih lanjut dari kontur yang dikenali, misalnya, menyederhanakannya menjadi bentuk geometris dasar.
Dan inovasi terakhir dalam Vision adalah versi baru dari ekstraktor fitur built-in VisionFeaturePrint. IOS telah menerapkan blok tersebutVisionFeaturePrint.Scene , yang sangat berguna untuk membuat pengklasifikasi gambar. Selain itu, model VisionFeaturePrint.Object baru sekarang tersedia, yang dioptimalkan untuk menyoroti fitur yang digunakan dalam pengenalan objek.
Model ini mendukung gambar input 299x299 dan menampilkan dua multi-array bentuk (288, 35, 35) dan (768, 17, 17). Ini belum menjadi framework pembatas yang jelas, tetapi hanya fitur "mentah". Untuk pengenalan objek yang lengkap, Anda perlu menambahkan logika yang mengubah fitur ini menjadi kotak pembatas dan label kelas. Create ML melakukan tugas ini jika Anda melatih alat pengenalan objek menggunakan transfer pelatihan.
Lihat juga:
- Jelajahi Computer Vision API (video WWDC)
- Deteksi Pose Tubuh dan Tangan dengan Visi (video WWDC)
- Jelajahi aplikasi Action & Vision (video WWDC)
Pemrosesan bahasa alami
Untuk tugas pemrosesan bahasa natural, Anda dapat menggunakan platform Natural Language. Dia secara aktif menggunakan model yang dilatih di Membuat ML.
Sangat sedikit fitur baru yang ditambahkan tahun ini:
NLTaggerdanNLModelsekarang temukan beberapa tag dan prediksi validitasnya. Sebelumnya, validitas suatu tag hanya ditentukan oleh jumlah poin yang dicetak.- Memasukkan kalimat. Penyisipan kata dapat digunakan sebelumnya, tetapi sekarang
NLEmbeddingmendukung seluruh kalimat.
Saat memasukkan kalimat, jaringan saraf bawaan digunakan untuk menyandikan seluruh kalimat ke dalam vektor berdimensi 512. Ini memungkinkan Anda untuk mendapatkan konteks di mana kata-kata digunakan dalam sebuah kalimat (penyisipan kata tidak mendukung fitur ini).
Lihat juga:
Analisis pidato dan suara
Tidak ada perubahan di area ini.
Pelatihan model
Melatih model menggunakan Apple API pertama kali tersedia di iOS 11.3 dan di platform Metal Performance Shaders. Selama beberapa tahun terakhir, banyak API pelatihan baru telah ditambahkan, dan tahun ini tidak terkecuali: menurut perhitungan saya, kami sekarang memiliki sebanyak 7 API berbeda untuk melatih jaringan saraf di platform iOS dan macOS!
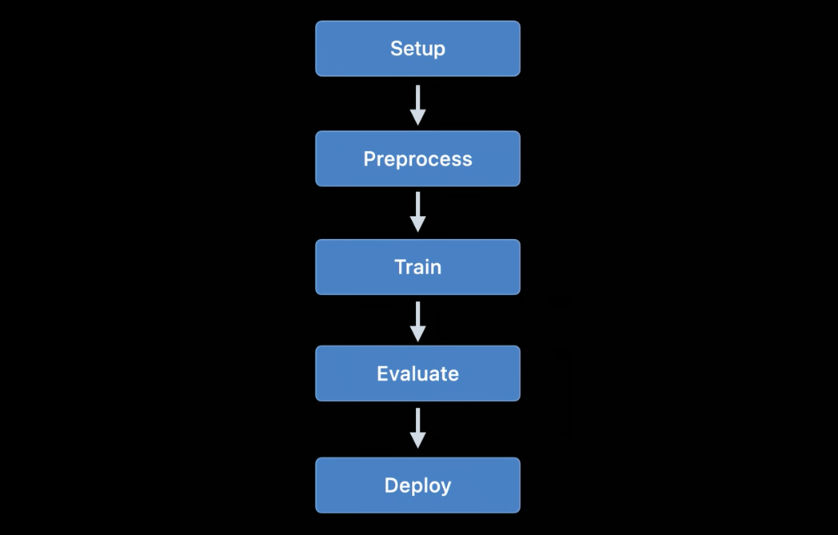
Saat ini, Apple API berikut dapat digunakan untuk melatih model pembelajaran mesin - di jaringan neural tertentu - di iOS dan macOS:
- Pembelajaran lokal di Core ML.
- Buat ML : Antarmuka ini mungkin Anda kenal sebagai aplikasi, tetapi ini juga merupakan platform yang tersedia di macOS.
- Metal Performance Shaders : API untuk inferensi dan pelatihan pada GPU. Faktanya, ini adalah dua API yang berbeda, cukup sulit digunakan jika Anda baru mengenal Metal. Selain itu, kerangka kerja Grafik Shaders Kinerja Logam baru juga tersedia yang tampaknya menggantikan API lama ini.
- BNNS : Bagian dari platform Accelerate. Sebelumnya, hanya inferensi rutin yang tersedia di BNNS, tetapi dukungan pelatihan juga telah ditambahkan tahun ini.
- ML Compute : Platform yang pada dasarnya baru dan terlihat sangat menjanjikan.
- Turi Create : Ini sebenarnya adalah Create ML versi Python. Baru-baru ini, pembuatnya telah melupakannya, meskipun dukungan platform belum dihentikan.
Mari kita lihat lebih dekat inovasi dalam API ini.
Pembelajaran lokal di Core ML
Nyatanya, tidak ada perubahan besar di sini. Dukungan pembaruan dapat ditambahkan untuk beberapa jenis lapisan lagi, tetapi saya belum melihat dokumentasi apa pun tentang ini.
Salah satu inovasi penting yang diharapkan dalam versi beta mendatang adalah pengoptimal RMSprop. Itu tidak termasuk dalam versi beta saat ini.
Buat ML
Platform Create ML awalnya hanya tersedia untuk macOS. Ini dapat dijalankan di Swift Playground sehingga dapat digunakan untuk melatih model hanya dengan beberapa baris kode.

Tahun lalu, Create ML diubah menjadi aplikasi yang cukup terbatas, dan saya senang melihat peningkatan yang signifikan tahun ini. Karena itu, Create ML tetap menjadi platform yang masih dapat digunakan dari belakang kode. Faktanya, aplikasi ini hanyalah antarmuka grafis yang nyaman untuk bekerja dengan platform.
Di Create ML versi sebelumnya, Anda dapat melatih model hanya sekali. Untuk mengubah sesuatu, Anda harus melatihnya kembali dari awal, dan ini membutuhkan banyak waktu.
Versi baru Xcode 12 memungkinkanjeda pelatihan dan lanjutkan di lain waktu , simpan titik pemeriksaan model (snapshot), dan lihat hasil pelatihan model awal. Kami sekarang memiliki lebih banyak alat untuk mengelola proses pembelajaran. Dengan update ini, Create ML sangat berguna!
API baru juga tersedia di platform CreateML.framework untuk menyiapkan sesi pelatihan, menangani titik putus model, dan banyak lagi. Saya kira kebanyakan orang hanya akan menggunakan aplikasi Buat ML, tetapi masih menyenangkan melihat fitur ini sekarang tersedia di platform.
Fitur Create ML baru (baik di platform maupun di aplikasi):
- Mentransfer Gaya untuk Gambar dan Video
- Klasifikasi tindakan manusia dalam rekaman video
Mari kita lihat lebih dekat model klasifikasi tindakan baru. Ini menggunakan model pengenalan postur yang tersedia di platform Vision. Pengklasifikasi tindakan adalah jaringan neural yang mengambil form (
window_size, 3, 18) sebagai masukan , dengan nilai pertama mewakili durasi fragmen video, ditunjukkan dalam jumlah bingkai (biasanya digunakan fragmen sekitar 2 detik), dan (3, 18) mewakili poin-poin penting dari pose.
Alih-alih mengulang lapisan, jaringan neural menggunakan konvolusi satu dimensi. Ini kemungkinan besar adalah variasi dari Jaringan Konvolusional Grafik Ruang Waktu (STGCN) - jenis model yang dirancang khusus untuk perkiraan deret waktu. Detail ini tidak perlu membuat Anda khawatir saat menggunakan model seperti itu dalam aplikasi. Namun, saya selalu ingin tahu bagaimana semuanya bekerja.
Sedangkan untuk model pengenalan objek, Anda dapat memilih untuk melatih seluruh jaringan berdasarkan TinyYOLOv2, atau menggunakan mode transfer pelatihan baru, yang menggunakan unit ekstraksi fitur VisionFeaturePrint.Object baru . Model lainnya masih menyerupai YOLO dan SSD, namun, berkat transfer tersebut, pelatihannya akan jauh lebih cepat daripada melatih seluruh model berbasis YOLO.
Lihat juga:
- Buat Pengklasifikasi Tindakan dengan Create ML (video WWDC)
- Membuat model Transfer Gaya Gambar dan Video di Create ML (video WWDC)
- Control training in Create ML with Swift ( Create ML Swift) ( WWDC)
Metal Performance Shaders
Metal Performance Shaders (MPS) adalah platform berdasarkan core komputasi kinerja Metal, yang terutama digunakan untuk pemrosesan gambar, tetapi sejak 2016 juga menawarkan dukungan untuk jaringan saraf. Saya sudah banyak membuat blog tentang ini.
Saat ini, sebagian besar pengguna akan memilih Core ML daripada MPS. Tentu saja, Core ML masih memanfaatkan kekuatan MPS saat menjalankan model pada GPU. Namun, MPS juga dapat digunakan secara langsung, terutama jika pengguna berencana untuk melakukan pelatihan sendiri (ngomong-ngomong, platform baru ML Compute sekarang tersedia, yang direkomendasikan untuk digunakan sebagai pengganti MPS. Penjelasannya diberikan di bawah).
Ada beberapa fitur baru di MPSCNN tahun ini, tetapi beberapa perbaikan telah dilakukan pada yang sudah ada.
Menambahkan kelas baru
MPSImageCannyuntuk pengenalan tepi dan MPSImageEDLines untuk pengenalan segmen garis. Mereka sangat berguna saat menangani masalah penglihatan komputer.
Sejumlah perubahan lain juga perlu diperhatikan:
- Sebuah
MPSCNNConvolutionDataSourceproperti baru telah ditambahkankernelWeightsDataTypeyang memungkinkan Anda untuk menggunakan tipe data yang berbeda untuk koefisien pembobotan dari itu digunakan untuk konvolusi. Menariknya, bobot tidak boleh dari tipe data INT8, meskipun Core ML memungkinkan tipe data ini digunakan untuk lapisan individual. - Jika
kernelWeightsDataTypekembali.float32, lapisan konvolusional dan terhubung sepenuhnya dilakukan menggunakan titik mengambang 32-bit, bukan 16-bit. Sebelumnya, hanya didukung 16-bit. - Fungsi kerugian sekarang dapat menggunakan parameter
reduceAcrossBatch.
Anda masih dapat menggunakan MPSCNN jika Metal tidak membuat Anda takut. Namun, kini tersedia platform baru yang sangat menyederhanakan pembuatan dan eksekusi grafik seperti: MPS Graph.
Catatan . The WWDC Video menyatakan bahwa MPSNDArray adalah API baru, namun ternyata keluar tahun lalu. Ini adalah struktur data yang jauh lebih fleksibel daripada MPSImage karena tidak semua tensor dalam model Anda dapat berupa gambar.
Baru: Grafik Metal Performance Shaders

API telah lama tersedia di MPS
MPSNNGraph, tetapi grafik seperti itu, pada kenyataannya, hanya menjelaskan jaringan neural. Namun, tidak semua grafik harus jaringan saraf, dan dalam hal ini platform Grafik Shaders Kinerja Logam akan berguna.
Platform baru ini dapat digunakan untuk membuat grafik komputasi GPU tujuan umum. Platform Grafik MPS tidak bergantung pada Metal Performance Shaders, meskipun dibangun atas dasar itu.
Pada versi sebelumnya dari API yang tidak digunakan lagi
MPSNNGraph, tidak mungkin menambahkan operasi khusus ke grafik. Platform baru jauh lebih fleksibel dalam hal ini. Namun, Anda tidak dapat menambahkan inti Logam Anda sendiri. Anda perlu mengungkapkan semua perhitungan menggunakan primitif yang ada.
Untungnya kompilernya
MPSGraphmendukung integrasi primitif tersebut ke dalam inti komputasi tunggal, yang memastikan operasi paling efisien pada prosesor grafis. Namun, skema ini tidak akan berfungsi jika tidak mungkin atau sulit untuk menggunakan primitif yang disediakan untuk beberapa operasi. Saya hanya tidak mengerti mengapa Apple, saat membuat API baru seperti ini, tidak pernah mengizinkan fungsi kustom lengkap! Tapi tidak ada yang bisa dilakukan.
Platform baru
MPSGraphadalah struktur yang cukup sederhana dan logis yang menggambarkan hubungan antar operasi dalam satu set MPSGraphOperationsmenggunakan tensorMPSGraphTensorsberisi hasil operasi. Selain itu, Anda dapat menentukan dependensi kontrol untuk memaksa node individu untuk memulai sebelum yang lain. Setelah mengkonfigurasi grafik, itu harus dijalankan atau ditransfer ke buffer perintah, dan kemudian menunggu hasilnya.
MPSGraphmenyediakan seluruh rangkaian metode instance yang memungkinkan Anda menambahkan operasi jaringan matematika atau neural apa pun ke grafik.
Selain itu, pelatihan didukung, yang melibatkan penambahan operasi pemrosesan kerugian ke grafik dan kemudian melakukan operasi gradien untuk semua lapisan dalam urutan terbalik - seperti dalam urutan sebelumnya
MPSNNGraph. Untuk kenyamanan, mode diferensiasi otomatis juga tersedia, di mana mode tersebut MPSGraphsecara otomatis melakukan operasi gradien untuk grafik. Ini menghemat banyak tenaga.
Saya suka bahwa sekarang ada API baru, sederhana dan mudah untuk membuat grafik komputasi semacam itu. Ini jauh lebih mudah digunakan daripada versi sebelumnya. Dan Anda tidak perlu menjadi ahli Metal untuk bekerja dengannya. Omong-omong, ini sangat mirip grafik TensorFlow 1.x, tetapi memiliki keuntungan besar dalam hal pengoptimalan, yang memungkinkan Anda meminimalkan biaya. Namun, tidak ada cukup kemampuan untuk menambahkan inti komputasi arbitrer ke grafik.
Lihat juga:
- Buat model ML yang disesuaikan dengan Metal Performance Shaders Graph (video WWDC)
- Menambahkan Fungsi Kustom ke Grafik Shader
BNNS (Basic Neural Network Subrutin)
Jika Core ML berjalan pada CPU, maka itu menggunakan rutinitas BNSS yang merupakan bagian dari platform Accelerate. Saya sudah menulis tentang BNNS di artikel ini . Sebagian besar fitur BNNS sekarang sebagian besar dihentikan dan diganti dengan rangkaian fitur baru.
Sebelumnya, hanya lapisan yang terhubung sepenuhnya, fungsi pelipatan, pengelompokan, dan aktivasi yang didukung. Pembaruan ini menambahkan dukungan untuk larik n-dimensi ke BNNS, hampir semua jenis lapisan Core ML, dan versi kompatibilitas mundur dari lapisan pelatihan tersebut (termasuk lapisan yang saat ini tidak mendukung pelatihan Core ML, seperti LSTM).
Perlu juga diperhatikan adanya lapisan perhatian ganda.... Lapisan ini sering digunakan dalam model Transformer seperti BERT. Hal menarik lainnya adalah konvolusi tensor.
Anda mungkin tidak menggunakan fitur BNNS ini sendiri - sama seperti Anda tidak akan menggunakan MPS untuk berlatih dengan GPU. Sebagai gantinya, platform ML Compute tingkat yang lebih tinggi sekarang tersedia yang mengabstraksi prosesor yang digunakan. ML Compute didasarkan pada BNNS dan MPS, tetapi pengembang tidak perlu khawatir tentang hal-hal kecil seperti itu.
Lihat juga: dokumentasi platform BNNS
Baru: ML Compute
ML Compute adalah platform yang pada dasarnya baru untuk melatih jaringan neural pada CPU atau GPU (tetapi tampaknya tidak pada prosesor Neural Engine). Di Mac Pro dengan beberapa GPU, platform ini dapat secara otomatis menggunakan semuanya untuk berlatih.
Saya sedikit terkejut dengan hadirnya platform pembelajaran lain, tetapi platform ini sangat menyederhanakan segalanya, karena memungkinkan Anda untuk menyembunyikan komponen tingkat rendah dari BNNS dan MPS, dan di masa mendatang, mungkin dari Neural Engine.
Yang terbaik dari semuanya, ML Compute juga didukung oleh sistem iOS, bukan hanya Mac. Lucu sekali bahwa Core ML tidak disebutkan di mana pun. ML Compute sepertinya dibuat sepenuhnya terpisah. Framework ini tidak dapat digunakan untuk membuat model Core ML.
Dari pengalaman saya sendiri, saya dapat mengatakan bahwa tugas ML Compute adalah, pertama-tama, mempercepat kerja alat deep learning pihak ketiga . Anda tidak perlu menulis kode apa pun untuk bekerja langsung dengan ML Compute. Sepertinya seharusnya (atau pengembang berharap) bahwa alat seperti TensorFlow akan mulai menggunakan platform ini untuk mengaktifkan pembelajaran yang dipercepat perangkat keras di Mac.
Tersedia sekumpulan lapisan yang kurang lebih sama seperti di BNNS. Lapisan harus ditambahkan ke grafik, dan kemudian dijalankan (di sini, mode "menunggu sibuk" tidak digunakan).
Untuk membuat grafik, Anda harus terlebih dahulu membuat instance objek
MLCGraphdan menambahkan node ke dalamnya. Node adalah subclass MLCLayer. Node terhubung satu sama lain melalui objekMLCTensoryang berisi keluaran dari lapisan lain.
Menariknya, operasi pembagian, penggabungan, pemformatan ulang, dan transfer bukanlah jenis lapisan yang terpisah, tetapi operasi langsung pada grafik.
Fitur debug yang sangat baik -
summarizedDOTDescription. Ini mengembalikan deskripsi DOT untuk grafik, dari mana Anda kemudian dapat membuat grafik menggunakan, misalnya, Graphviz atau OmniGraffle (omong-omong, Keras membuat grafik model dengan cara ini).
ML Compute membedakan antara grafik inferensi dan grafik pembelajaran. Yang terakhir berisi node tambahan, misalnya, lapisan kerugian dan pengoptimal.
Sepertinya tidak ada cara untuk membuat lapisan khusus di sini, jadi Anda hanya perlu mengikuti jenis yang tersedia di ML Compute.
Aneh kalau tidak ada sesi WWDC di platform baru ini, dan dokumentasinya juga cukup tersebar. Pokoknya saya akan terus ikuti perkembangannya, karena sepertinya ini adalah API yang paling cocok untuk model training di perangkat Apple.
Lihat juga: Dokumentasi Platform Komputasi ML
Kesimpulan
The Inti ML menambahkan sejumlah fitur baru yang berguna, seperti pembaruan otomatis model dan enkripsi. Jenis lapisan baru sebenarnya tidak terlalu dibutuhkan, karena lapisan yang ditambahkan tahun lalu dapat menyelesaikan hampir semua masalah. Secara keseluruhan, saya suka pembaruan ini.
Di coremltools 4 menambahkan peningkatan penting - arsitektur konverter baru dan dukungan bawaan TensorFlow 2 dan PyTorch. Saya senang kami tidak lagi harus menggunakan ONNX untuk mengubah model PyTorch.
Dalam Visimenambahkan banyak fitur praktis baru. Dan saya suka bahwa Apple telah menambahkan fungsionalitas analisis video. Meskipun sistem pembelajaran mesin dapat diterapkan ke bingkai video individual, dalam hal ini, waktu tidak dihitung. Karena perangkat seluler saat ini cukup cepat untuk melakukan pembelajaran mesin berdasarkan data video secara real time, saya yakin video akan memainkan peran yang lebih penting dalam pengembangan teknologi computer vision dalam waktu dekat.
Berkenaan dengan pelatihan... tidak yakin apakah kami memerlukan tujuh API berbeda untuk tugas ini. Saya kira Apple tidak ingin menghentikan antarmuka yang sudah ketinggalan zaman sampai yang baru sepenuhnya disempurnakan. Sedikit yang diketahui tentang platform ML Compute. Namun, pada saat penulisan ini, hanya versi beta pertama yang dirilis. Siapa yang tahu apa yang ada di depan ...
Gambar kuliah menggunakan Freepik ikon dari flaticon.com.