
Foto dari situs Unsplash . Oleh Sasha • Stories
Scikit-learn adalah salah satu pustaka pembelajaran mesin Python yang paling banyak digunakan. Antarmuka standarnya yang sederhana memungkinkan pemrosesan awal data, pelatihan, pengoptimalan, dan evaluasi model.
Proyek ini, dirancang oleh David Cournapeau, lahir sebagai bagian dari program Google Summer of Code dan dirilis pada 2010. Sejak awal, library tersebut telah berkembang menjadi infrastruktur yang kaya untuk membuat model pembelajaran mesin. Fitur baru memungkinkan Anda menyelesaikan lebih banyak tugas dan meningkatkan kegunaan. Pada artikel ini, saya akan membagikan sepuluh fitur paling menarik yang mungkin belum Anda ketahui.
1. Set data bawaan
Dalam scikit-learn API, Anda bisa menemukan set data bawaan yang berisi data yang dihasilkan dan sebenarnya . Anda dapat menggunakannya hanya dengan satu baris kode. Data ini sangat berguna jika Anda baru belajar atau hanya ingin menguji sesuatu dengan cepat.
Selain itu, dengan menggunakan alat khusus, Anda dapat membuat sendiri data sintetis untuk tugas regresi
make_regression(), pengelompokan, make_blobs()dan klasifikasi make_classification().
Setiap metode menghasilkan data yang sudah dipecah menjadi X (fitur) dan Y (variabel target) sehingga dapat digunakan secara langsung untuk melatih model.
# Toy regression data set loading
from sklearn.datasets import load_boston
X,y = load_boston(return_X_y = True)
# Synthetic regresion data set loading
from sklearn.datasets import make_regression
X,y = make_regression(n_samples=10000, noise=100, random_state=0)2. Akses ke kumpulan data publik pihak ketiga
Jika Anda ingin mengakses berbagai set data publik secara langsung melalui scikit-learn, lihat fitur praktis yang memungkinkan Anda mengimpor data langsung dari openml.org . Situs ini berisi lebih dari 21.000 kumpulan data berbeda yang dapat digunakan dalam proyek pembelajaran mesin.
from sklearn.datasets import fetch_openml
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)3. Pengklasifikasi siap untuk model dasar pelatihan
Saat membuat model pembelajaran mesin untuk suatu proyek, sebaiknya buat model dasar terlebih dahulu. Ini adalah model dummy yang selalu memprediksi kelas paling umum. Ini akan memberi Anda tolok ukur untuk membandingkan model Anda yang lebih kompleks. Selain itu, Anda dapat yakin dengan kualitas kerjanya, misalnya, bahwa ia menghasilkan lebih dari sekadar sekumpulan data yang dipilih secara acak.
Pustaka scikit-learn memiliki satu
DummyClassifier()untuk masalah klasifikasi dan DummyRegressor()untuk bekerja dengan regresi.
from sklearn.dummy import DummyClassifier
# Fit the model on the wine dataset and return the model score
dummy_clf = DummyClassifier(strategy="most_frequent", random_state=0)
dummy_clf.fit(X, y)
dummy_clf.score(X, y)4. Memiliki API untuk visualisasi
Scikit-learn memiliki API visualisasi bawaan yang memungkinkan Anda untuk memvisualisasikan cara kerja model Anda tanpa mengimpor pustaka lain. Ini menyediakan opsi berikut: plot dependensi, matriks kesalahan, kurva ROC, dan Precision-Recall.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
metrics.plot_roc_curve(clf, X_test, y_test)
plt.show()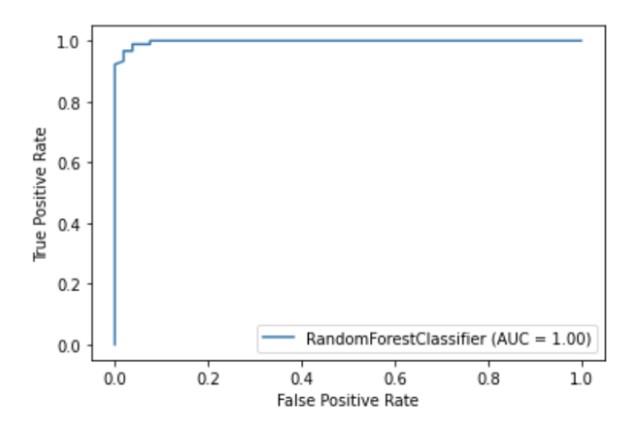
Ilustrasi penulis
5. Metode seleksi fitur bawaan
Salah satu cara untuk meningkatkan kualitas model adalah dengan hanya menggunakan fitur yang paling berguna dalam pelatihan atau menghapus fitur yang paling tidak informatif. Proses ini disebut pemilihan fitur.
Scikit-learn memiliki sejumlah metode untuk melakukan pemilihan fitur , salah satunya adalah
SelectPercentile(). Metode ini memilih persentil-X dari fitur yang paling informatif berdasarkan metode estimasi statistik yang ditentukan.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectPercentile, chi2
X,y = load_wine(return_X_y = True)
X_trasformed = SelectPercentile(chi2, percentile=60).fit_transform(X, y)6. Saluran pipa untuk menghubungkan tahapan dalam proses pembelajaran mesin
Selain dapat menggunakan daftar besar algoritma pembelajaran mesin, scikit-learn juga menyediakan sejumlah fungsi untuk preprocessing dan transformasi data. Untuk memastikan reproduktifitas dan aksesibilitas dalam proses pembelajaran mesin di scikit-learn dibuat , Pipeline , yang menyatukan berbagai langkah dan tahap pra-pemrosesan model pelatihan.
Pipeline menyimpan semua tahapan alur kerja sebagai satu objek yang dapat dipanggil dengan metode fit and predict. Saat Anda menjalankan metode fit pada objek pipeline, langkah-langkah preprocessing dan model training dilakukan secara otomatis.
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Chain together scaling the variables with the model
pipe = Pipeline([('scaler', StandardScaler()), ('rf', RandomForestClassifier())])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)7. ColumnTransformer untuk memvariasikan metode preprocessing untuk fitur yang berbeda
Banyak set data berisi berbagai jenis fitur, yang memerlukan beberapa tahapan berbeda untuk diproses sebelumnya. Misalnya, Anda mungkin dihadapkan pada campuran data kategorikal dan numerik, dan Anda mungkin ingin menskalakan kolom numerik dan mengonversi fitur kategoris ke numerik menggunakan enkode one-hot.
Pipeline scikit-learn dilengkapi dengan fungsi ColumnTransformer , yang memungkinkan Anda dengan mudah menunjukkan metode prapemrosesan yang paling tepat untuk kolom tertentu melalui pengindeksan atau dengan menentukan nama kolom.
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))8. Dapatkan gambar HTML pipeline Anda dengan mudah
Pipeline sering menjadi sangat kompleks, terutama saat bekerja dengan data nyata. Oleh karena itu, sangat mudah jika Anda dapat menggunakan scikit-learn untuk mengeluarkan diagram HTML dari langkah pipeline Anda.
from sklearn import set_config
set_config(display='diagram')
lr
Ilustrasi penulis
9. Fungsi plot untuk memvisualisasikan pohon keputusan
Fungsi ini
plot_tree()memungkinkan Anda membuat diagram langkah-langkah yang ada dalam model pohon keputusan.
import matplotlib.pyplot as plt
from sklearn import metrics, model_selection
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_breast_cancer
X,y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
plot_tree(clf, filled=True)
plt.show()10. Banyak pustaka pihak ketiga yang memperluas fungsi scikit-learn
Ada banyak pustaka pihak ketiga yang kompatibel dengan scikit-learn dan memperluas fungsinya.
Misalnya, pustaka Category Encoders , yang menyediakan pilihan yang lebih luas dari metode prapemrosesan untuk fitur kategorikal, atau pustaka ELI5 , untuk interpretasi model yang lebih mendetail.
Kedua sumber daya juga dapat diakses secara langsung melalui pipeline scikit-learn.
# Pipeline using Weight of Evidence transformer from category encoders
from sklearn import model_selection
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_openml
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import category_encoders as ce
# Load auto93 data set which contains both categorical and numeric features
X,y = fetch_openml("auto93", version=1, as_frame=True, return_X_y=True)
# Create lists of numeric and categorical features
numeric_features = X.select_dtypes(include=['int64', 'float64']).columns
categorical_features = X.select_dtypes(include=['object']).columns
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0)
# Create a numeric and categorical transformer to perform preprocessing steps
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('woe', ce.woe.WOEEncoder())])
# Use the ColumnTransformer to apply to the correct features
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# Append regressor to the preprocessor
lr = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LinearRegression())])
# Fit the complete pipeline
lr.fit(X_train, y_train)
print("model score: %.3f" % lr.score(X_test, y_test))Terima kasih atas perhatian Anda!