Pendekatan motivasi
Pendekatan yang diterima secara umum untuk tugas computer vision adalah dengan menggunakan gambar sebagai larik 3D (tinggi, lebar, jumlah saluran) dan menerapkan konvolusi padanya. Pendekatan ini memiliki beberapa kelemahan:
- tidak semua piksel dibuat sama. Misalnya, jika kita memiliki tugas klasifikasi, maka objek itu sendiri lebih penting bagi kita daripada latar belakang. Menarik bahwa penulis tidak mengatakan bahwa Perhatian sudah digunakan dalam masalah penglihatan komputer;
- Konvolusi tidak berfungsi cukup baik dengan piksel yang berjauhan. Ada pendekatan dengan konvolusi yang melebar dan penggabungan rata-rata global, tetapi mereka tidak menyelesaikan masalah itu sendiri;
- Konvolusi tidak cukup efisien di jaringan neural yang sangat dalam.
Oleh karena itu, penulis mengusulkan hal berikut: ubah gambar menjadi semacam token visual dan kirimkan ke transformator.

- Pertama, tulang punggung biasa digunakan untuk mendapatkan peta fitur
- Selanjutnya, peta fitur diubah menjadi token visual
- Token diumpankan ke transformer
- Keluaran transformator dapat digunakan untuk masalah klasifikasi
- Dan jika Anda menggabungkan output transformator dengan peta fitur, Anda bisa mendapatkan prediksi untuk tugas segmentasi
Di antara karya-karya dalam arah yang sama, penulis masih menyebutkan Attention, tetapi perhatikan bahwa biasanya Attention diterapkan pada piksel, oleh karena itu, sangat meningkatkan kompleksitas komputasi. Mereka juga berbicara tentang pekerjaan untuk meningkatkan efisiensi jaringan saraf, tetapi mereka percaya bahwa dalam beberapa tahun terakhir mereka telah memberikan perbaikan yang semakin sedikit, sehingga pendekatan lain harus dicari.
Transformator visual
Sekarang mari kita lihat lebih dekat bagaimana model itu bekerja.
Seperti disebutkan di atas, tulang punggung mengambil peta fitur, dan mereka diteruskan ke lapisan transformator visual.
Setiap transformator visual terdiri dari tiga bagian: tokenizer, transformator, dan proyektor.
Tokenizer

Tokenizer mengambil token visual. Faktanya, kami mengambil peta fitur, melakukan bentuk ulang di (H * W, C) dan dari sini kami mendapatkan token.

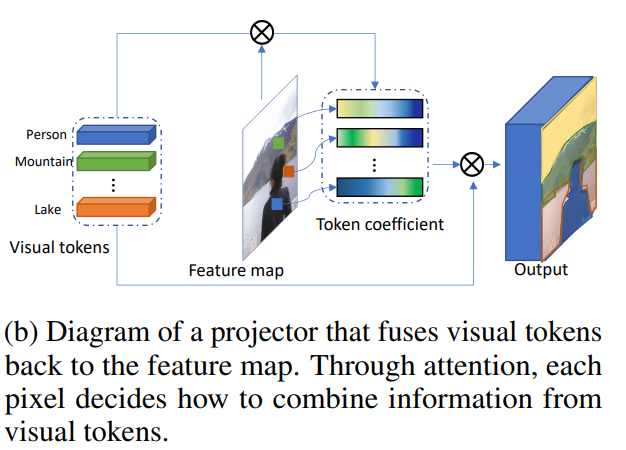
Visualisasi koefisien untuk token terlihat seperti ini:

Pengkodean posisi
Seperti biasa, transformer tidak hanya membutuhkan token, tetapi juga informasi tentang posisinya.

Pertama, kita melakukan downsample, kemudian kita mengalikan dengan bobot pelatihan dan menggabungkannya dengan token. Untuk mengatur jumlah saluran, Anda dapat menambahkan konvolusi 1D.
Transformator
Terakhir, trafo itu sendiri.

Menggabungkan token visual dan peta fitur
Ini membuat proyektor.

Tokenisasi dinamis
Setelah lapisan pertama transformator, kita tidak hanya dapat mengekstrak token visual baru, tetapi juga menggunakan yang diekstrak dari langkah sebelumnya. Anak timbangan terlatih digunakan untuk menggabungkannya:

Menggunakan transformer visual untuk membangun model computer vision
Selanjutnya penulis menjelaskan bagaimana model tersebut diterapkan pada masalah computer vision. Blok transformator memiliki tiga hyperparameter: jumlah saluran di peta fitur C, jumlah saluran di token visual Ct, dan jumlah token visual L.
Jika jumlah saluran ternyata tidak sesuai saat beralih antar blok model, maka konvolusi 1D dan 2D digunakan untuk mendapatkan jumlah saluran yang diperlukan.
Untuk mempercepat penghitungan dan mengurangi ukuran model, gunakan konvolusi grup.
Penulis melampirkan blok ** pseudocode ** di artikel. Kode lengkap dijanjikan akan diposting di masa mendatang.
Klasifikasi gambar
Kami mengambil ResNet dan membuat visual-transformer-ResNets (VT-ResNet) berdasarkan itu.
Kami meninggalkan tahap 1-4, tetapi alih-alih yang terakhir kami menempatkan transformator visual.
Keluar tulang punggung - peta fitur 14 x 14, jumlah saluran 512 atau 1024 tergantung pada kedalaman VT-ResNet. 8 token visual untuk 1024 saluran dibuat dari peta fitur. Output dari trafo menuju ke head untuk klasifikasi.

Segmentasi semantik
Untuk tugas ini, jaringan piramida fitur panoptik (FPN) diambil sebagai model dasar.
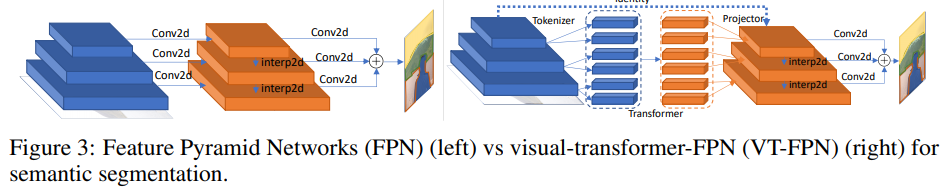
Di FPN, konvolusi berfungsi pada gambar resolusi tinggi, jadi modelnya berat. Penulis mengganti operasi tersebut dengan trafo visual. Sekali lagi, 8 token dan 1024 saluran.
Eksperimen
Klasifikasi ImageNet
Latih 400 epoch dengan RMSProp. Mereka mulai dengan kecepatan pembelajaran 0,01, meningkat menjadi 0,16 selama 5 periode pemanasan, lalu mengalikan setiap periode dengan 0,9875. Normalisasi batch dan ukuran batch 2048 digunakan.Label smoothing, AutoAugment, probabilitas kelangsungan hidup kedalaman stokastik 0,9, putus sekolah 0,2, EMA 0,999985.
Ini adalah berapa banyak percobaan yang harus saya jalankan untuk menemukan semua ini ...
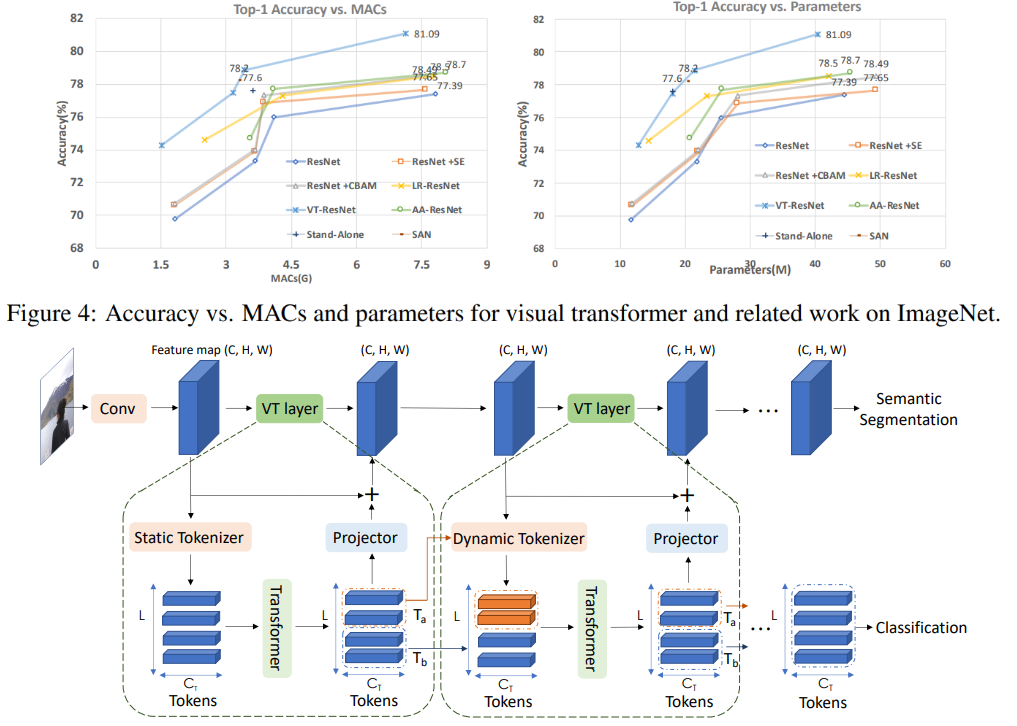
Pada grafik ini Anda dapat melihat bahwa pendekatan memberikan kualitas yang lebih tinggi dengan pengurangan jumlah perhitungan dan ukuran model.
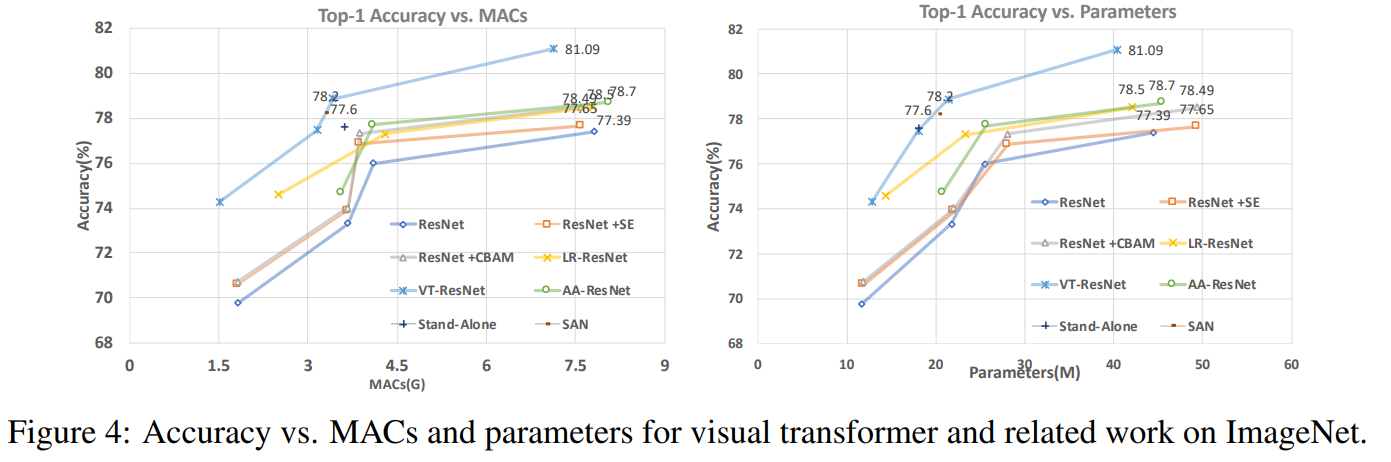
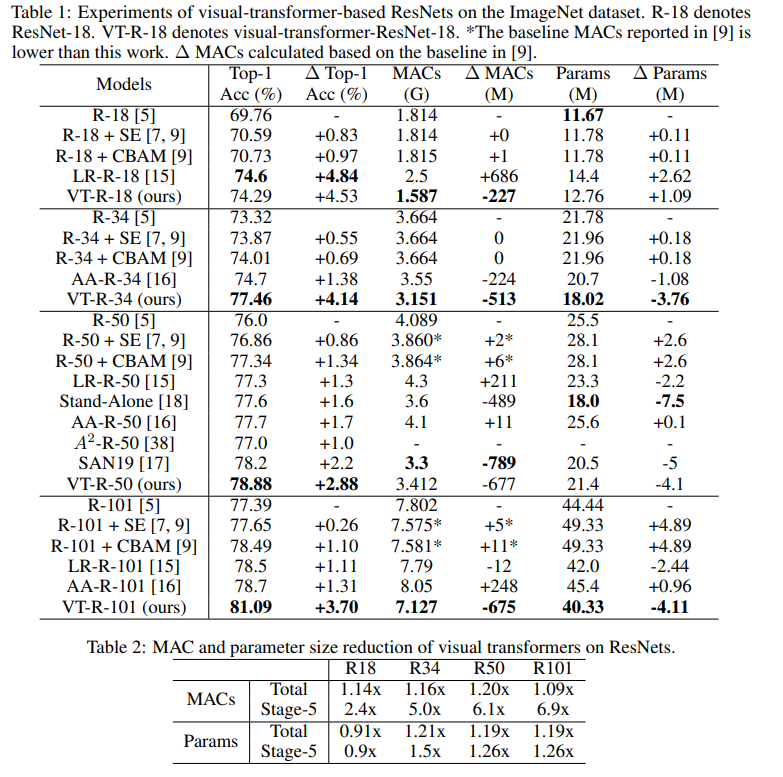
Judul artikel untuk model yang dibandingkan:
ResNet + CBAM - Modul perhatian blok konvolusional
ResNet + SE - Jaringan pemerasan dan eksitasi
LR-ResNet - Jaringan relasi lokal untuk pengenalan gambar
StandAlone - Perhatian diri yang berdiri sendiri dalam model penglihatan
AA-ResNet - Jaringan konvolusional yang ditingkatkan perhatian
SAN - Menjelajahi perhatian diri untuk pengenalan gambar
Studi ablasi
Untuk mempercepat eksperimen, kami menggunakan VT-ResNet- {18, 34} dan melatih 90 epoch.
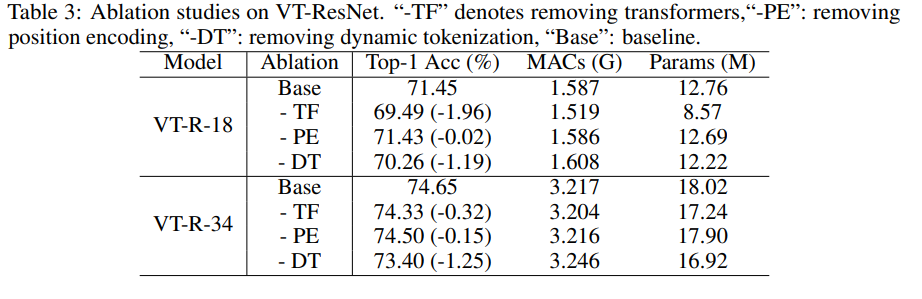
Menggunakan transformator sebagai pengganti konvolusi memberikan keuntungan terbesar. Tokenisasi dinamis, bukan tokenisasi statis, juga memberikan dorongan besar. Pengkodean posisi hanya memberikan sedikit perbaikan.
Hasil segmentasi

Seperti yang Anda lihat, metrik hanya tumbuh sedikit, tetapi model tersebut mengkonsumsi MAC 6,5 kali lebih sedikit.
Potensi masa depan dari pendekatan tersebut
Eksperimen telah menunjukkan bahwa pendekatan yang diusulkan memungkinkan Anda membuat model yang lebih efisien (dalam hal biaya komputasi), yang pada saat yang sama mencapai kualitas yang lebih baik. Arsitektur yang diusulkan berhasil berfungsi untuk berbagai tugas computer vision, dan diharapkan aplikasinya dapat membantu meningkatkan sistem yang menggunakan comuter vision - AR / VR, mobil otonom, dan lain-lain.
Tinjauan tersebut disiapkan oleh Andrey Lukyanenko, pengembang terkemuka MTS.