
Artikel ini akan menjelaskan pengalaman membuat jaringan saraf untuk pengenalan wajah, untuk menyortir semua foto dari percakapan VK untuk menemukan orang tertentu. Tanpa pengalaman dalam menulis jaringan saraf dan pengetahuan minimal tentang Python.
pengantar
Kami memiliki seorang teman, bernama Sergei, yang suka memotret dirinya sendiri dengan cara yang tidak biasa dan mengirim percakapan, dan juga membumbui foto-foto ini dengan frasa perusahaan. Jadi salah satu malam tentang perselisihan itu, kami punya ide - untuk membuat publik di VK, di mana kami dapat memposting Sergey dengan kutipannya. Sepuluh pos pertama dalam penundaan itu mudah, tetapi kemudian menjadi jelas bahwa tidak ada gunanya membahas semua lampiran dalam percakapan dengan tangan Anda. Jadi diputuskan untuk menulis jaringan saraf untuk mengotomatiskan proses ini.
Rencana
- Dapatkan tautan ke foto dari percakapan
- Unduh foto
- Menulis jaringan saraf
Sebelum memulai pengembangan
, Python pip. , 0, ,
1. Mendapatkan link ke foto
Jadi kami ingin mendapatkan semua foto dari percakapan, metode messages.getHistoryAttachments cocok untuk kami , yang mengembalikan materi dialog atau percakapan.
Sejak 15 Februari 2019, Vkontakte menolak akses ke pesan untuk aplikasi yang belum lolos moderasi. Dari opsi solusi, saya dapat menawarkan vkhost , yang akan membantu Anda mendapatkan token dari messenger pihak ketiga
Dengan token yang diterima di vkhost, kami dapat mengumpulkan permintaan API yang kami butuhkan menggunakan Postman . Anda dapat, tentu saja, mengisi segala sesuatu dengan pena tanpa itu, tapi untuk kejelasan kami akan menggunakan
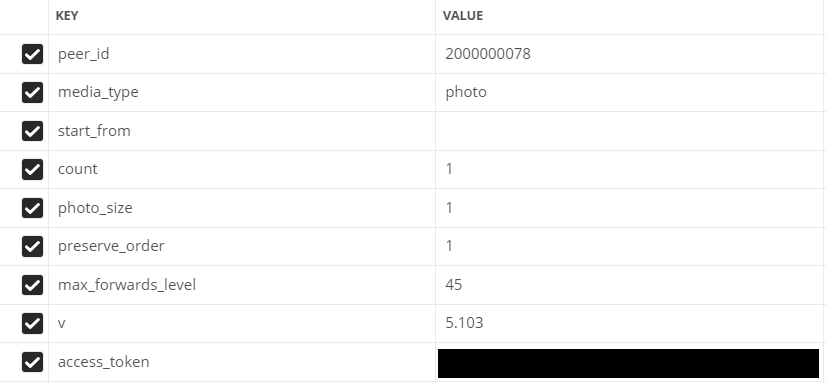
it.Fill dalam parameter:
- peer_id - pengidentifikasi tujuan
Untuk percakapan: 2.000.000.000 + id percakapan (bisa dilihat di address bar).
Untuk pengguna: id pengguna. - media_type - jenis media
Dalam kasus kami, foto
- start_from - offset untuk memilih beberapa item.
Biarkan kosong untuk saat ini.
- hitung - jumlah objek yang diterima
Maksimal 200, itulah yang akan kami gunakan
- photo_sizes - bendera untuk mengembalikan semua ukuran dalam larik
1 atau 0. Kami menggunakan 1
- save_order - bendera yang menunjukkan apakah lampiran harus dikembalikan dalam urutan aslinya
1 atau 0. Kami menggunakan 1
- v - versi api vk
1 atau 0. Kami menggunakan 1
Kolom yang diisi di Postman
Pergi ke penulisan kode
Untuk kenyamanan, semua kode akan dipecah menjadi beberapa skrip terpisah.
Akan menggunakan modul json (untuk memecahkan kode data) dan perpustakaan permintaan (untuk membuat permintaan http)
Daftar kode jika ada kurang dari 200 foto dalam percakapan / dialog
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
Jika ada lebih dari 200 foto
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()Saatnya mengunduh tautan
2. Mendownload gambar
Untuk mengunduh foto kami menggunakan perpustakaan urllib
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
Proses mendownload semua gambar bukanlah yang tercepat, apalagi jika fotonya 8330. Space untuk case ini juga diperlukan, jika jumlah foto sama dengan milik saya atau lebih, saya sarankan untuk membebaskan 1,5 - 2 GB untuk ini . Pekerjaan

kasar sudah selesai, sekarang kamu bisa mulai sendiri menarik - menulis jaringan saraf
3. Menulis jaringan saraf
Setelah melihat banyak pustaka dan opsi yang berbeda, diputuskan untuk menggunakan pustaka
Pengenalan Wajah
Apa yang bisa dilakukannya?
Dari dokumentasi, pertimbangkan fitur paling dasar dari
pencarian wajah di foto
dapat menemukan sejumlah orang di foto, bahkan mengatasi

identifikasi kabur pada foto individu
dapat mengenali siapa milik orang dalam gambar

bagi kami metode yang paling cocok adalah identifikasi orang
Latihan
Dari persyaratan untuk pustaka, diperlukan Python 3.3+ atau Python 2.7 .
Mengenai pustaka, Pengenalan Wajah dan PIL yang disebutkan di atas akan digunakan untuk bekerja dengan gambar.
Pustaka Pengenalan Wajah tidak secara resmi didukung di Windows , tetapi berfungsi untuk saya. Semuanya bekerja secara stabil dengan macOS dan Linux.
Penjelasan tentang apa yang terjadi
Untuk memulainya, kita perlu mengatur pengklasifikasi untuk mencari seseorang yang dengannya verifikasi foto lebih lanjut akan dilakukan.
Saya merekomendasikan memilih foto orang yang paling jelas dalam tampilan depan.Saat mengunggah foto, perpustakaan memecah gambar menjadi koordinat fitur wajah seseorang (hidung, mata, mulut, dan dagu)

Nah, masalahnya kecil, yang tersisa hanyalah menerapkan metode serupa pada foto yang ingin kita bandingkan dengan pengklasifikasi kita. Kemudian kami membiarkan jaringan saraf membandingkan fitur wajah dengan koordinat.
Nah, kode sebenarnya itu sendiri:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
Dimungkinkan juga untuk menjalankan semuanya melalui analisis mendalam pada kartu video, untuk ini Anda perlu menambahkan parameter model = "cnn" dan mengubah fragmen kode untuk gambar yang ingin kita cari orang yang tepat:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Hasil
Tanpa GPU. Berdasarkan waktu, jaringan saraf melewati dan menyortir 8.330 foto dalam 1 jam 40 menit dan pada saat yang sama menemukan 142 foto, 62 di antaranya dengan gambar orang yang diinginkan. Tentu saja ada kesalahan positif pada meme dan orang lain.
C GPU. Waktu pemrosesan memakan waktu lebih lama, 17 jam dan 22 menit, dan saya menemukan 230 foto yang 99 di antaranya adalah orang yang kami butuhkan.
Kesimpulannya, kita dapat mengatakan bahwa pekerjaan itu tidak dilakukan dengan sia-sia. Kami telah mengotomatiskan proses penyortiran 8330 foto, yang jauh lebih baik daripada menyortirnya sendiri.
Anda juga dapat mengunduh seluruh kode sumber dari github