Halo! Sulit untuk menemukan programmer mikrokontroler yang tidak pernah mengalami kegagalan yang parah. Sangat sering itu tidak diproses dengan cara apapun, tetapi tetap tergantung dalam loop tak berujung dari handler yang disediakan dalam file startup pabrikan. Pada saat yang sama, programmer mencoba untuk secara intuitif menemukan alasan kegagalan tersebut. Menurut saya, ini bukanlah cara terbaik untuk menyelesaikan masalah.
Pada artikel ini, saya ingin menjelaskan teknik untuk menganalisis kegagalan parah mikrokontroler populer dengan inti Cortex M3 / M4. Meskipun, mungkin, "teknik" adalah kata yang terlalu keras. Sebaliknya, saya hanya akan mengambil contoh bagaimana saya menganalisis terjadinya kegagalan parah dan menunjukkan apa yang dapat dilakukan dalam situasi serupa. Saya akan menggunakan perangkat lunak IAR dan papan debug STM32F4DISCOVERY, karena banyak calon programmer memiliki alat ini. Namun, ini sama sekali tidak relevan, contoh ini dapat diadaptasi untuk prosesor keluarga dan lingkungan pengembangan apa pun.

Jatuh ke HardFault
Sebelum Anda mencoba menganalisis HatdFault, Anda perlu memahaminya. Ada banyak cara untuk melakukan ini. Segera terpikir oleh saya untuk mencoba mengalihkan prosesor dari status Thumb ke status ARM dengan menyetel alamat instruksi lompat tanpa syarat ke bilangan genap.
Penyimpangan kecil. Seperti yang Anda ketahui, mikrokontroler dari keluarga Cortex M3 / M4 menggunakan set instruksi perakitan Thumb-2 dan selalu berfungsi dalam mode Thumb. Mode ARM tidak didukung. Jika Anda mencoba menyetel nilai alamat lompat tanpa syarat (BX reg) dengan bit paling tidak signifikan dihapus, pengecualian UsageFault akan terjadi, karena prosesor akan mencoba mengalihkan statusnya ke ARM. Anda dapat membaca lebih lanjut tentang ini di [1] (klausul 2.8 SET INSTRUKSI; 4.3.4 Bahasa Assembler: Panggilan dan Cabang Tanpa Syarat).
Untuk memulainya, saya mengusulkan untuk mensimulasikan lompatan tanpa syarat ke alamat genap di C / C ++. Untuk melakukan ini, saya akan membuat fungsi func_hard_fault, lalu saya akan mencoba memanggilnya dengan pointer, setelah mengurangi alamat pointer satu per satu. Hal ini dapat dilakukan sebagai berikut:
void func_hard_fault(void);
void main(void)
{
void (*ptr_hard_fault_func) (void); //
ptr_hard_fault_func = reinterpret_cast<void(*)()>(reinterpret_cast<uint8_t *>(func_hard_fault) - 1); //
ptr_hard_fault_func(); //
while(1) continue;
}
void func_hard_fault(void) //,
{
while(1) continue;
}
Mari kita lihat dengan debugger apa yang saya lakukan.

Dengan warna merah, saya menyoroti instruksi lompat saat ini di alamat di RON R1, yang berisi alamat lompat genap. Hasilnya:

Operasi ini dapat dilakukan dengan lebih sederhana menggunakan sisipan assembler:
void main(void)
{
//
asm("LDR R1, =0x0800029A"); //- f
asm("BX r1"); // R1
while(1) continue;
}
Hore, kita masuk ke HardFault, misi selesai!
Analisis HardFault
Di mana kami mendapatkan HardFault?
Menurut pendapat saya, yang paling penting adalah mencari tahu dari mana kami mendapatkan HardFault. Ini tidak sulit dilakukan. Pertama, mari tulis penangan kita sendiri untuk situasi HardFault.
extern "C"
{
void HardFault_Handler(void)
{
}
}Sekarang mari kita bicara tentang cara mencari tahu bagaimana kita sampai di sini. Inti prosesor Cortex M3 / M4 memiliki hal yang luar biasa seperti pelestarian konteks [1] (klausul 9.1.1 Penumpukan). Sederhananya, ketika ada pengecualian, konten register R0-R3, R12, LR, PC, PSR disimpan di stack.

Di sini register terpenting bagi kami adalah register PC, yang berisi informasi tentang instruksi yang sedang dijalankan. Karena nilai register didorong ke stack pada saat pengecualian, ini akan berisi alamat dari instruksi terakhir yang dieksekusi. Register lainnya kurang penting untuk analisis, tetapi sesuatu yang berguna dapat diambil darinya. LR adalah alamat balik dari transisi terakhir, R0-R3, R12 adalah nilai yang dapat menunjukkan ke arah mana harus bergerak, PSR hanyalah register umum dari status program.
Saya mengusulkan untuk mengetahui nilai register di handler. Untuk melakukan ini, saya menulis kode berikut (saya melihat kode serupa di salah satu file pabrikan):
extern "C"
{
void HardFault_Handler(void)
{
struct
{
uint32_t r0;
uint32_t r1;
uint32_t r2;
uint32_t r3;
uint32_t r12;
uint32_t lr;
uint32_t pc;
uint32_t psr;
}*stack_ptr; // (SP)
asm(
"TST lr, #4 \n" // 3 ( )
"ITE EQ \n" // 3?
"MRSEQ %[ptr], MSP \n" //,
"MRSNE %[ptr], PSP \n" //,
: [ptr] "=r" (stack_ptr)
);
while(1) continue;
}
}
Hasilnya, kami memiliki nilai dari semua register yang disimpan:
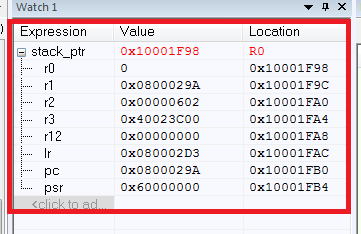
Apa yang terjadi di sini? Pertama, kami mendapatkan stack pointer stack_ptr, semuanya jelas di sini. Kesulitan muncul dengan penyisipan assembler (jika ada kebutuhan untuk memahami instruksi assembler untuk Cortex, maka saya merekomendasikan [2]).
Mengapa kita tidak menyimpan tumpukan melalui MRS stack_ptr, MSP? Faktanya adalah bahwa inti Cortex M3 / M4 memiliki dua penunjuk tumpukan [1] (item 3.1.3 Penunjuk Tumpukan R13) - penunjuk tumpukan MSP utama dan penunjuk tumpukan proses PSP. Mereka digunakan untuk mode prosesor yang berbeda. Saya tidak akan membahas lebih dalam untuk apa ini dilakukan dan bagaimana cara kerjanya, tetapi saya akan memberikan sedikit penjelasan.
Untuk mengetahui mode operasi prosesor (digunakan dalam MSP atau PSP ini), Anda perlu memeriksa bit ketiga dari register komunikasi. Bit ini menentukan penunjuk tumpukan mana yang digunakan untuk kembali dari pengecualian. Jika bit ini disetel, maka itu adalah MSP, jika tidak, maka PSP. Secara umum, sebagian besar aplikasi yang ditulis dalam C / C ++ hanya menggunakan MSP, dan pemeriksaan ini dapat dihilangkan.
Jadi apa intinya? Memiliki daftar register yang disimpan, kita dapat dengan mudah menentukan dari mana program itu jatuh di HardFault dari register PC. PC menunjuk ke alamat 0x0800029A, yang merupakan alamat dari instruksi "melanggar" kami. Jangan lupa tentang pentingnya nilai register yang tersisa.
Penyebab HardFault
Faktanya, kami juga bisa mengetahui penyebab HardFault. Dua register akan membantu kami dalam hal ini. Register status kesalahan keras (HFSR) dan register status kesalahan yang dapat dikonfigurasi (CFSR; UFSR + BFSR + MMFSR). Register CFSR terdiri dari tiga register: Register status kesalahan penggunaan (UFSR), Register status kesalahan bus (BFSR), Register alamat kesalahan manajemen memori (MMFSR). Anda dapat membaca tentang mereka, misalnya, di [1] dan [3].
Saya mengusulkan untuk melihat apa yang dihasilkan register ini dalam kasus saya:

Pertama, bit HFSR FORCED disetel. Ini berarti telah terjadi kegagalan yang tidak dapat diproses. Untuk diagnosa lebih lanjut, register status kesalahan yang tersisa harus diperiksa.
Kedua, bit CFSR INVSTATE disetel. Ini berarti UsageFault telah terjadi karena prosesor mencoba menjalankan instruksi yang menggunakan EPSR secara ilegal.
Apa itu EPSR? EPSR - Register status program eksekusi. Ini adalah register PSR internal - register status program khusus (yang, seingat kami, disimpan di stack). Bit kedua puluh empat dari register ini menunjukkan status prosesor saat ini (Thumb atau ARM). Ini dapat menentukan alasan kegagalan kami. Mari kita coba menghitungnya:
volatile uint32_t EPSR = 0xFFFFFFFF;
asm(
"MRS %[epsr], PSP \n"
: [epsr] "=r" (EPSR)
);
Dari hasil eksekusi didapatkan nilai EPSR = 0.

Ternyata register menunjukkan status ARM dan kita temukan penyebab kegagalannya? Tidak juga. Memang, menurut [3] (p. 23), membaca register ini menggunakan perintah MSR khusus selalu mengembalikan nol. Tidak begitu jelas bagi saya mengapa cara kerjanya seperti ini, karena register ini sudah hanya-baca, tetapi di sini tidak dapat dibaca sepenuhnya (hanya beberapa bit yang dapat digunakan melalui xPSR). Mungkin ini adalah beberapa batasan arsitektural.
Akibatnya, sayangnya, semua informasi ini praktis tidak memberikan apa-apa kepada programmer MK biasa. Itulah mengapa saya menganggap semua register ini hanya sebagai tambahan untuk analisis konteks yang disimpan.
Namun, sebagai contoh, jika kegagalan disebabkan oleh pembagian oleh nol (kegagalan ini diperbolehkan dengan mengatur bit DIV_0_TRP dari register CCR), maka bit DIVBYZERO akan diatur dalam register CFSR, yang akan menunjukkan kepada kami alasan dari kegagalan yang sangat besar ini.
Apa berikutnya?
Apa yang bisa dilakukan setelah kita menganalisis penyebab kegagalan? Prosedur berikut tampaknya menjadi pilihan yang baik:
- Cetak nilai dari semua register yang dianalisis ke konsol debug (printf). Ini hanya dapat dilakukan jika Anda memiliki debugger JTAG.
- Simpan informasi kegagalan ke flash internal atau eksternal (jika tersedia). Juga dimungkinkan untuk menampilkan nilai register PC pada layar perangkat (jika tersedia).
- Muat ulang prosesor NVIC_SystemReset ().

Sumber
- Joseph Yiu. Panduan definitif untuk ARM Cortex-M3.
- Panduan Pengguna Umum Perangkat Cortex-M3.
- STM32 Cortex-M4 MCU dan panduan pemrograman MPU.