
Dari sudut pandang arsitektur, platform IoT membutuhkan tugas-tugas berikut untuk diselesaikan:
- Jumlah data yang diterima, diterima, dan diproses membutuhkan bandwidth, penyimpanan, dan daya komputasi yang tinggi.
- Perangkat dapat didistribusikan ke wilayah geografis yang luas
- Perusahaan membutuhkan arsitektur mereka untuk terus berkembang sehingga layanan baru dapat ditawarkan kepada pelanggan.
Salah satu fitur platform IoT adalah independensi antara objek dan sinyal, yang memungkinkan komputasi paralel, meningkatkan produktivitas.
Data dari sensor dikumpulkan dari sumber: PLC, DCS, mikrokontroler, dll. Dan dapat disimpan dalam domain waktu untuk menghindari kehilangan data karena masalah koneksi. Data dapat berupa deret waktu (peristiwa), data semi-terstruktur (log dan binari), atau data tidak terstruktur (gambar). Data dan peristiwa deret waktu sering dikumpulkan (dari setiap detik hingga beberapa menit). Mereka kemudian dikirim melalui jaringan dan disimpan dalam data lake terpusat dan database time-series TSDB. Danau data bisa berbasis cloud, pusat data lokal, atau penyimpanan pihak ketiga.
Data dapat segera diproses menggunakan analisis aliran data yang disebut "jalur panas" dengan mekanisme pemeriksaan aturan berdasarkan setpoint yang sederhana atau cerdas. Analisis lanjutan dapat mencakup digital twins, machine learning, deep learning, atau analisis berbasis fisika. Sistem seperti itu dapat memproses data dalam jumlah besar (dari sepuluh menit hingga satu bulan) dari berbagai sensor. Data ini disimpan di penyimpanan perantara. Analisis ini disebut "jalur dingin" dan biasanya diluncurkan oleh penjadwal atau saat data tersedia dan membutuhkan banyak sumber daya komputasi. Analisis tingkat lanjut sering kali memerlukan informasi tambahan seperti model kendaraan yang dipantau dan atribut operasional, yang dapat ditemukan di registri aset.Registri Aset berisi informasi tentang jenis aset, termasuk nama, nomor seri, nama simbolik, lokasi, kemampuan operasional, riwayat bagian-bagiannya, dan peran yang dimainkannya dalam proses pembuatan. Di registri aset, kita dapat menyimpan daftar dimensi setiap aset, nama logis, unit ukuran, dan rentang batas. Di sektor industri, informasi statis ini penting untuk model analisis yang benar.Di sektor industri, informasi statis ini penting untuk model analisis yang benar.Di sektor industri, informasi statis ini penting untuk model analisis yang benar.
Alasan mengembangkan platform khusus:
- Laba atas investasi: anggaran kecil;
- Teknologi: penggunaan teknologi terlepas dari pemasoknya;
- Kerahasiaan data;
- Integrasi: kebutuhan untuk mengembangkan tingkat integrasi dengan platform baru atau usang;
- Pembatasan lainnya.
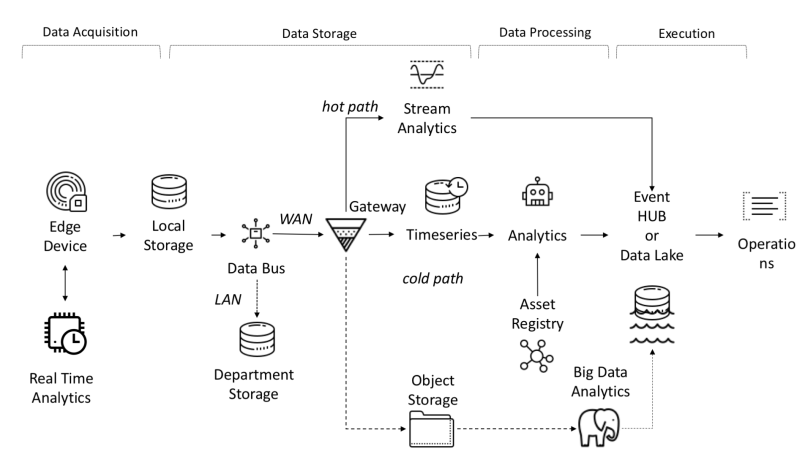
Aliran data ujung-ke-ujung di I-IoT
Contoh implementasi khusus platform Edge
Gambar ini menunjukkan implementasi dari tautan platform berikut:
- Sumber data: sebagai contoh, simulator pengendali Lanjutan PLCSIM Simatic dengan server OPC yang diaktifkan dipilih, seperti yang dijelaskan di artikel sebelumnya;
- Platform Node-Red yang populer dengan plugin node-red-contrib-opcua telah diinstal dipilih sebagai gateway perbatasan ;
- Pialang MQTT Mosquitto digunakan sebagai dispatcher untuk transfer data antara tautan lain di aliran;
- Apache Kafka digunakan sebagai platform streaming terdistribusi yang berfungsi sebagai analitik jalur panas menggunakan kafka-stream.
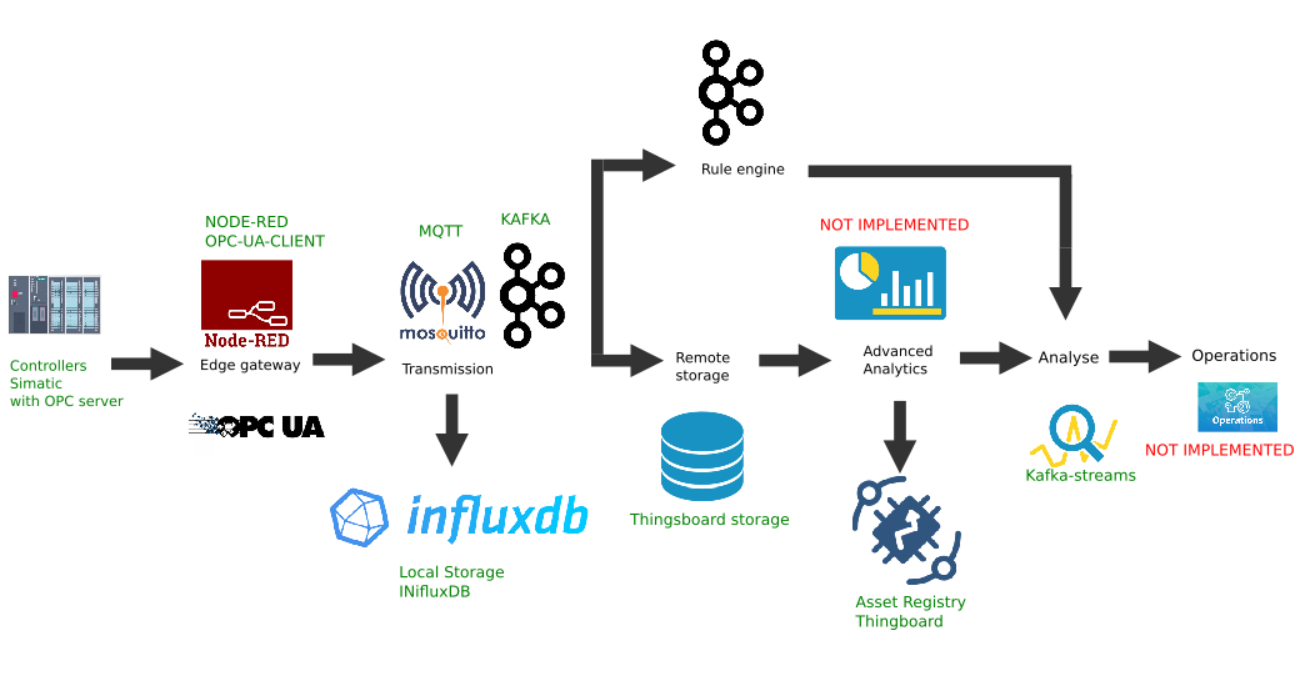
Gerbang tepi merah-node
Sebagai gateway komputasi tepi, kami akan menggunakan Node-red, platform kustom sederhana yang memiliki banyak plugin berbeda. Peran adaptor Industri dimainkan oleh plugin node-red-contrib-opcua. Untuk beberapa pengumpulan data dari pengontrol dengan metode berlangganan, node digunakan: OpcUa-Browser dan OpcUa-client. Di node browser OPC, url server OPC (titik akhir) dan topik dikonfigurasi, yang menentukan namespace dan nama blok data yang dapat dibaca, misalnya: ns = 3; s = "HMI_Alarms_Area". Di node klien OPC, url server OPC juga ditentukan, SUBSCRIBE dan interval pembaruan data ditetapkan sebagai Tindakan.
Aliran utama berwarna merah node
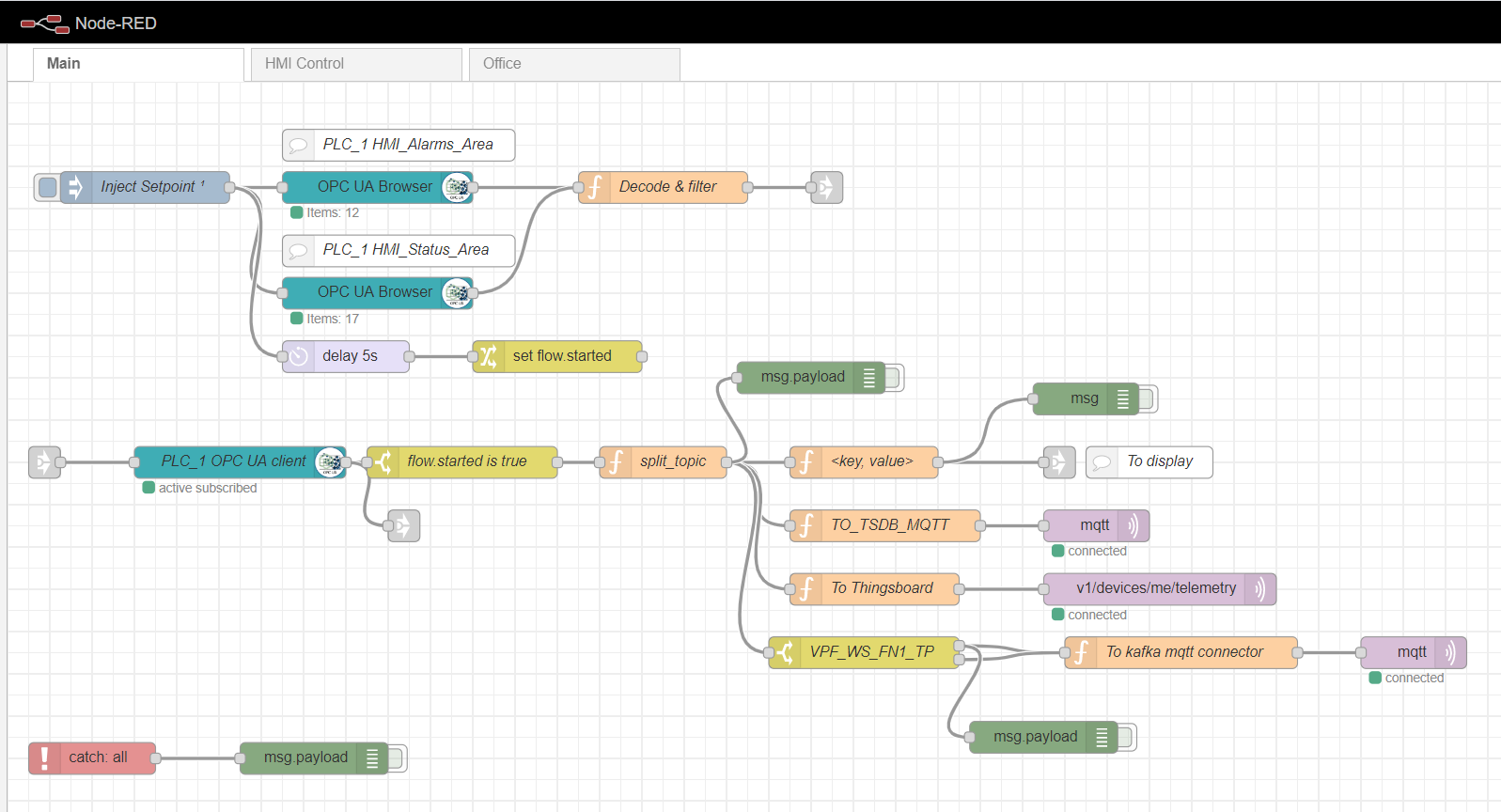
Menyiapkan node OPC-browser

OPC-client

Untuk berlangganan membaca banyak data, perlu menyiapkan dan mengunduh tag dari pengontrol, sesuai dengan protokol OPC. Untuk melakukan ini, pertama, node injeksi digunakan dengan kotak centang hanya sekali, yang memicu pembacaan blok data satu kali yang ditentukan di node browser OPC. Data tersebut kemudian diproses oleh fungsi Decode & filter. Setelah itu, node klien OPC berlangganan dan membaca data yang berubah dari pengontrol. Pemrosesan lebih lanjut dari aliran tergantung pada implementasi dan persyaratan khusus. Dalam contoh saya, saya memproses data untuk selanjutnya dikirim ke broker MQTT untuk topik yang berbeda.
Kontrol HMI dan tab Office adalah implementasi HMI sederhana berdasarkan Scadavis.io dan dasbor merah node seperti yang dijelaskan sebelumnya di artikel .
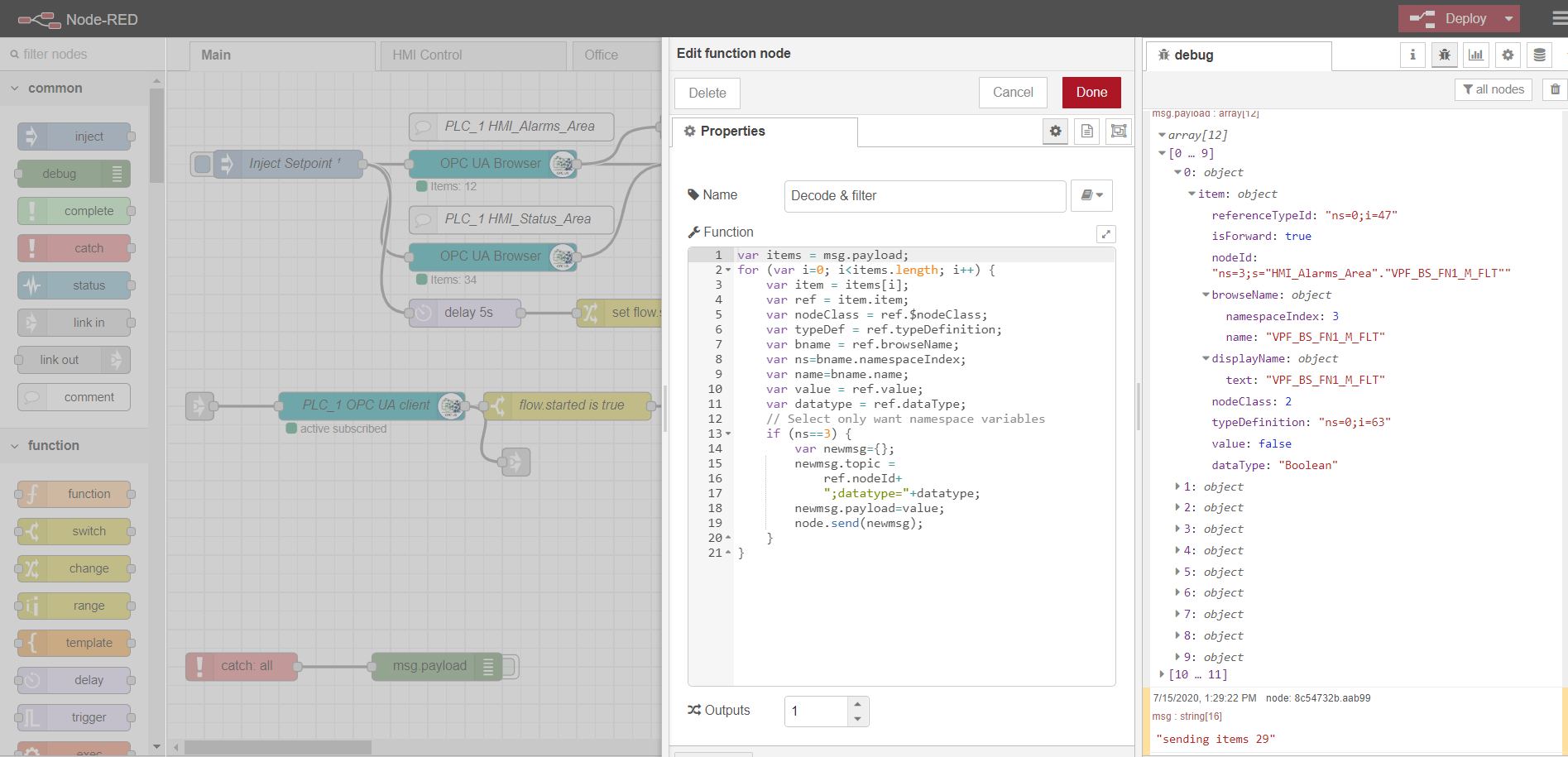
Contoh penguraian data dari node browser-OPC:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
Broker MQTT
Implementasi apa pun dapat digunakan sebagai broker. Dalam kasus saya, broker Mosquitto sudah diinstal dan dikonfigurasi . Broker melakukan fungsi pengiriman data antara gateway Edge dan peserta platform lainnya. Ada contoh dengan load balancing dan arsitektur terdistribusi ( seperti di sini ). Dalam kasus ini, kami akan membatasi diri pada satu pialang mqtt dengan transfer data tanpa enkripsi.
Penyimpanan lokal data deret waktu
Lebih mudah untuk merekam dan menyimpan data deret waktu dalam database deret waktu NoSql. Tumpukan InfluxData berfungsi dengan baik untuk tujuan kami . Kami membutuhkan empat layanan dari tumpukan ini:
InfluxDB adalah database rangkaian waktu sumber terbuka yang merupakan bagian dari tumpukan TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Didesain untuk pemrosesan data beban tinggi dan menyediakan bahasa kueri seperti SQL InfluxQL untuk berinteraksi dengan data.
Telegraf adalah agen untuk mengumpulkan dan mengirim metrik dan peristiwa ke InfluxDB dari sistem IoT eksternal, sensor, dll. Ini dikonfigurasi untuk mengumpulkan data dari topik mqtt.
Kapacitor adalah mesin data bawaan untuk InfluxDB 1.x dan komponen terintegrasi ke dalam platform InfluxDB. Layanan ini dapat dikonfigurasi untuk memantau berbagai setpoint dan alarm, serta memasang penangan untuk mengirim peristiwa ke sistem eksternal seperti Kafka, email, dll.
Chronograf adalah antarmuka pengguna dan komponen administratif dari platform InfluxDB. Digunakan untuk membuat dasbor dengan cepat dengan visualisasi waktu nyata.
Semua komponen stack dapat dijalankan secara lokal atau menyiapkan container Docker.
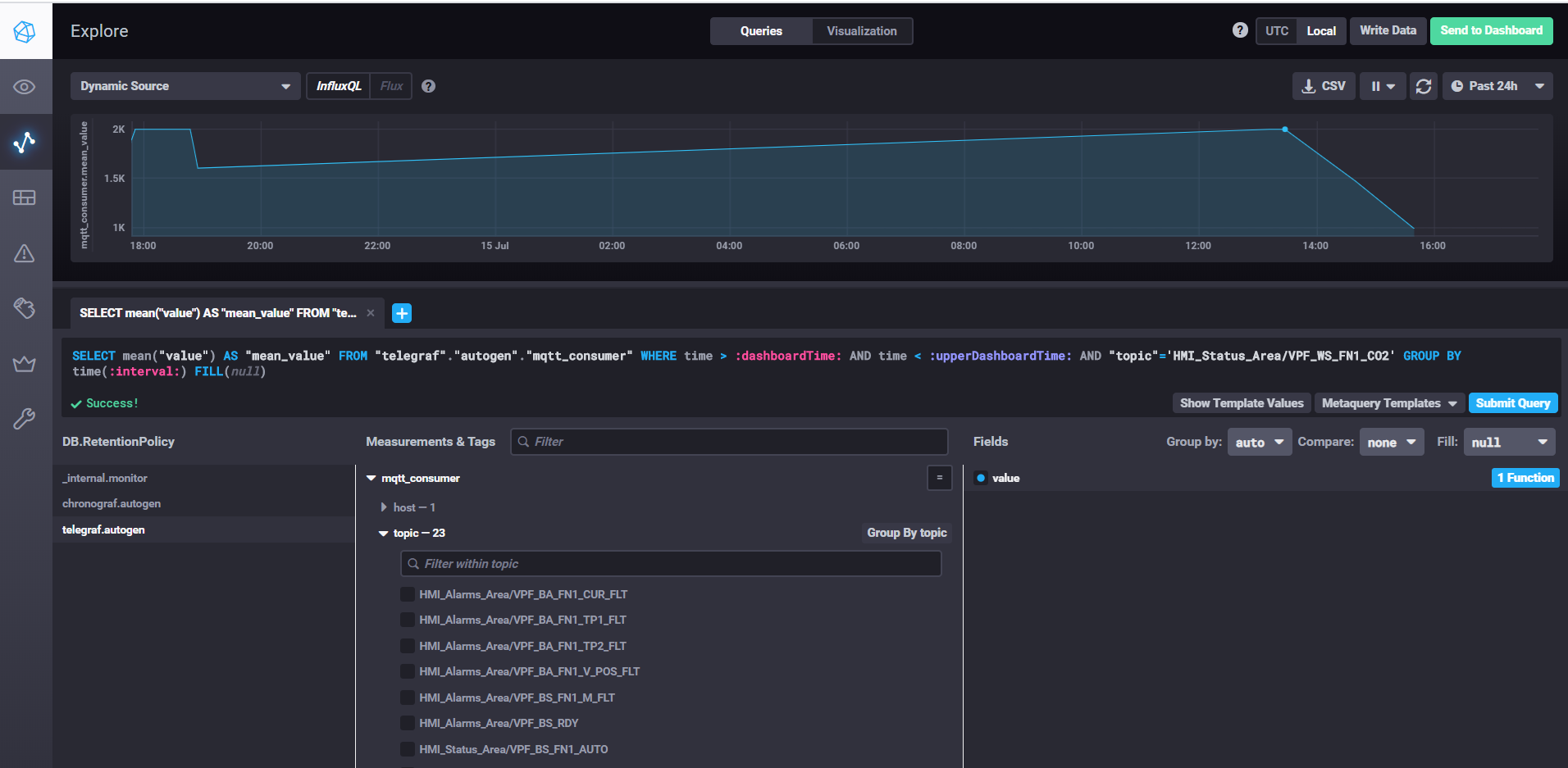
Mengambil data dan menyesuaikan dasbor dengan Chronograf
Untuk memulai InfluxDB, cukup jalankan perintah influxd, di pengaturan influxdb.conf Anda dapat menentukan lokasi penyimpanan dan properti lainnya, secara default data disimpan di direktori pengguna di direktori .influxdb.
Untuk memulai telegraf, Anda perlu menjalankan perintah telegraf -config telegraf.conf, di mana Anda dapat menentukan sumber metrik dan kejadian di pengaturan, dalam contoh kami untuk mqtt akan terlihat seperti ini:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
Di properti server, tentukan url ke pialang mqtt, qos dapat meninggalkan 0 jika cukup untuk menulis data tanpa konfirmasi. Dalam properti topik, tentukan topeng mqtt dari topik tempat kita akan membaca datanya. Misalnya HMI_Status_Area / # berarti kita membaca semua topik yang memiliki awalan HMI_Status_Area. Dengan demikian, telegraf untuk setiap topik akan membuat metriknya sendiri di database, tempat ia akan menulis data.
Untuk menjalankan kapacitor, Anda perlu menjalankan perintah kapacitord -config kapacitor.conf. Properti dapat dibiarkan sebagai default dan dikonfigurasi lebih lanjut dengan chronograf.
Untuk memulai chronograf, jalankan saja perintah chronograf dengan nama yang sama. Antarmuka web akan tersedia localhost : 8888 /
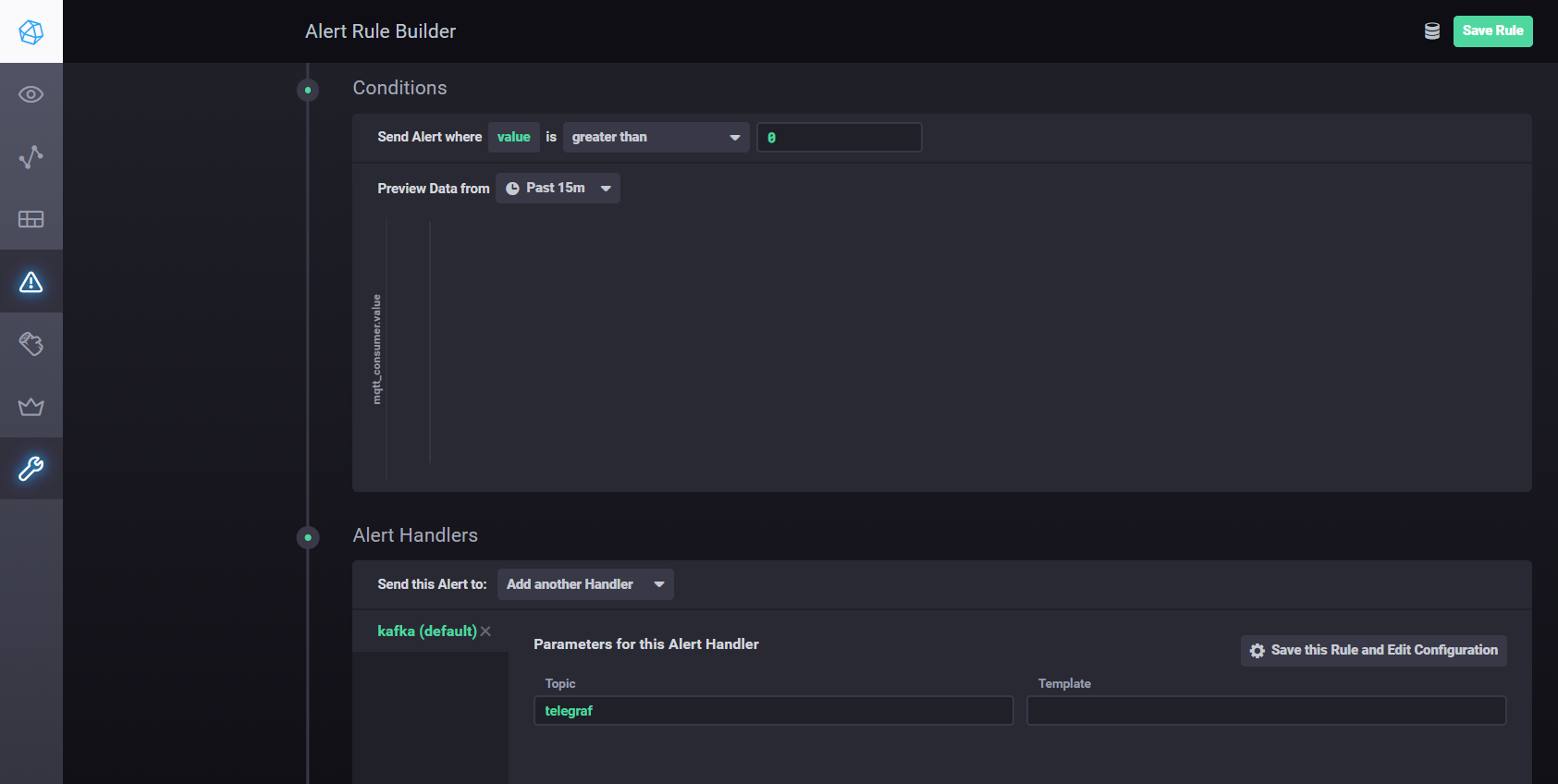
Untuk mengkonfigurasi pengaturan dan alarm menggunakan Kapacitor, Anda dapat menggunakanmanual . Singkatnya - Anda harus pergi ke tab Alerting di Chronograf dan membuat aturan baru menggunakan tombol Build Alert Rule, antarmukanya intuitif, semuanya dilakukan secara visual. Untuk mengatur pengiriman hasil pemrosesan ke kafka, dll. Anda perlu menambahkan penangan di bagian Kondisi
Pengaturan penangan Kapacitor
Streaming Terdistribusi dengan Apache Kafka
Untuk arsitektur yang diusulkan, pengumpulan data perlu dipisahkan dari pemrosesan, peningkatan skalabilitas, dan independensi lapisan. Kita dapat menggunakan antrian untuk mencapai tujuan ini. Implementasinya bisa berupa Java Message Service (JMS) atau Advanced Message Queuing Protocol (AMQP), namun dalam hal ini kita akan menggunakan Apache Kafka. Kafka didukung oleh sebagian besar platform analitik, memiliki kinerja dan skalabilitas yang sangat tinggi, dan memiliki perpustakaan aliran Kafka yang baik.
Anda dapat menggunakan plugin Node-red node-red-contrib-kafka-manager untuk berinteraksi dengan Kafka . Namun, dengan mempertimbangkan pemisahan pengumpulan dari pemrosesan data, kami akan menginstal plugin MQTT, yang berlangganan topik Mosquitto. Plugin MQTT tersedia di sini .
Untuk mengonfigurasi konektor, salin pustaka kafka-connect-mqtt-1.1-SNAPSHOT.jar dan org.eclipse.paho.client.mqttv3-1.0.2.jar (atau versi lain) ke direktori kafka / libs /. Kemudian, di direktori / config, Anda perlu membuat file properti mqtt.properties dengan konten berikut:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Setelah sebelumnya meluncurkan zookeeper-server dan kafka-server, kita dapat memulai konektor menggunakan perintah:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
Dari topik mqtt (mqtt.topic = mqtt), data akan ditulis ke topik Kafka ukuran-aliran (kafka.topic = streams-measure).
Sebagai contoh sederhana, Anda dapat membuat proyek maven menggunakan pustaka kafka-streams.
Dengan menggunakan kafka-stream, Anda dapat menerapkan berbagai layanan dan skenario untuk analitik panas dan pemrosesan data streaming.
Contoh membandingkan suhu saat ini dengan setpoint untuk periode tersebut.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Registri aset
Registri aset, pada kenyataannya, bukanlah komponen struktural dari platform Edge dan merupakan bagian dari lingkungan cloud IoT. Tetapi contoh ini menunjukkan bagaimana Edge dan Cloud berinteraksi.
Sebagai pencatatan aset, kami akan menggunakan platform IoT ThingsBoard yang populer, yang antarmukanya juga cukup intuitif. Instalasi dimungkinkan dengan data demo. Platform dapat diinstal secara lokal, di buruh pelabuhan, atau menggunakan lingkungan cloud yang sudah jadi .
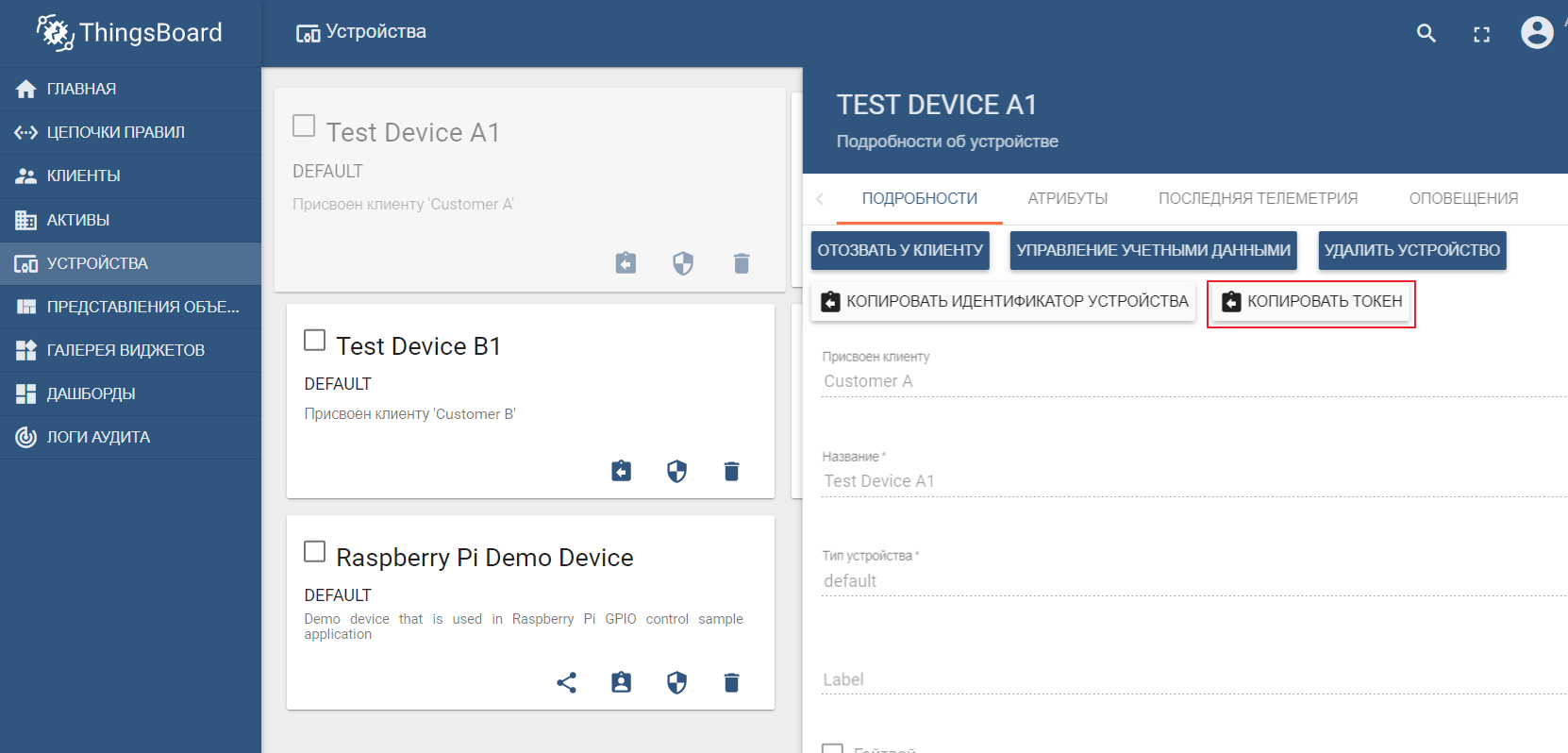
Dataset demo mencakup perangkat uji (Anda dapat dengan mudah membuat yang baru) tempat Anda dapat mengirim nilai. Secara default ThingsBoard dimulai dengan broker mqtt-nya sendiri, yang Anda perlukan untuk menghubungkan dan mengirim datadalam format json. Katakanlah kita ingin mengirim data ke ThingsBoard dari TEST DEVICE A1. Untuk melakukan ini, kita perlu terhubung ke broker ThingBoard di localhost: 1883 menggunakan A1_TEST_TOKEN sebagai login, yang dapat disalin dari pengaturan perangkat. Kemudian kami dapat mempublikasikan data ke topik v1 / perangkat / me / telemetri: {"suhu": 26}
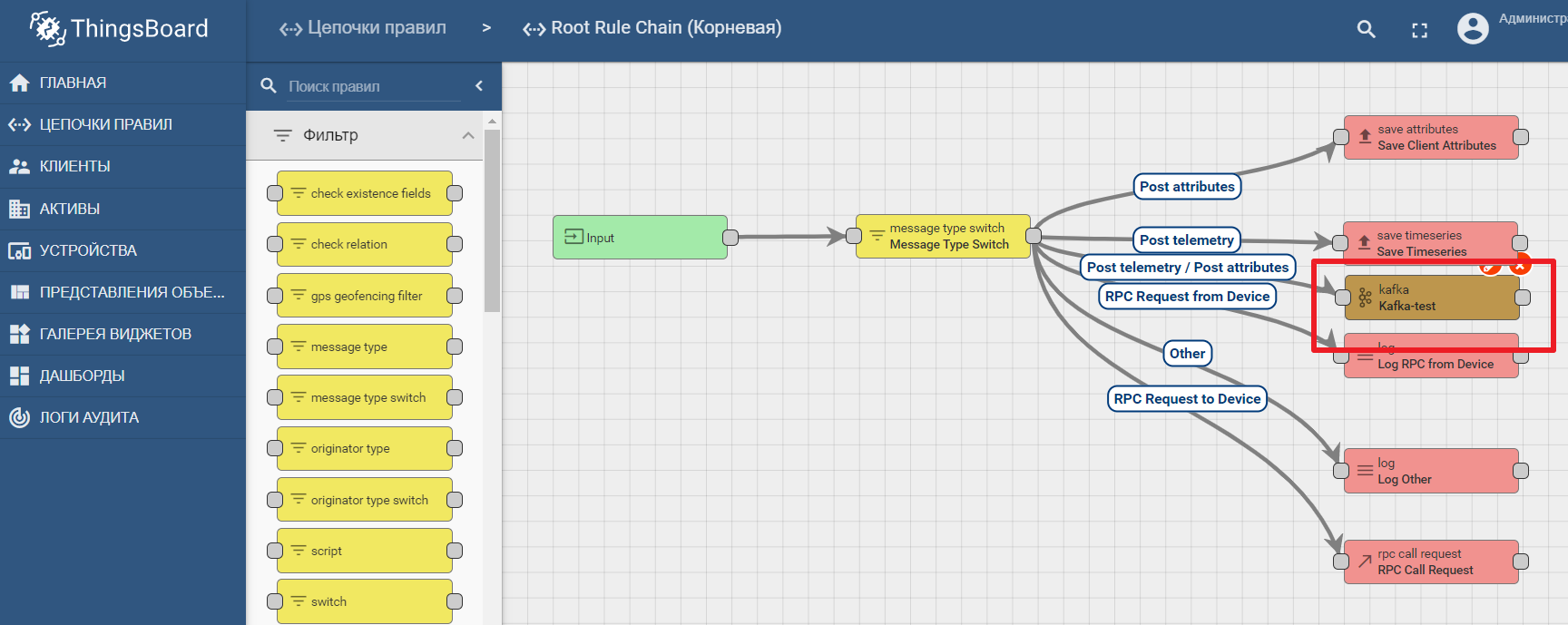
Dokumentasi platform berisi manual untuk menyiapkan transfer data dan memproses analitik di Kafka - analitik data IoT menggunakan Kafka, Kafka Streams, dan ThingsBoard
Contoh penggunaan node kafka di Thingsboard
Kesimpulan
Teknologi IT modern dan protokol terbuka memungkinkan untuk merancang sistem dengan kompleksitas apa pun. Platform edge adalah titik penghubung antara lingkungan industri dan platform IoT berbasis cloud. Itu dapat diuraikan menjadi komponen makro, di antaranya gateway tepi memainkan peran kunci, bertanggung jawab untuk meneruskan data dari perangkat ke hub data IoT. Alat streaming data terbuka memungkinkan analitik yang efisien dan komputasi edge.