Tetapi pekerjaan Data Scientist terkait dengan data, dan salah satu momen terpenting dan memakan waktu adalah memproses data sebelum mengirimkannya ke jaringan saraf atau menganalisisnya dengan cara tertentu.
Dalam artikel ini, tim kami akan menjelaskan bagaimana Anda dapat dengan mudah dan cepat memproses data dengan petunjuk dan kode langkah demi langkah. Kami mencoba membuat kode cukup fleksibel untuk diterapkan di berbagai kumpulan data.
Banyak profesional mungkin tidak menemukan sesuatu yang luar biasa dalam artikel ini, tetapi pemula akan dapat mempelajari sesuatu yang baru, dan siapa pun yang telah lama bermimpi membuat buku catatan terpisah untuk pemrosesan data yang cepat dan terstruktur dapat menyalin kode dan memformatnya sendiri, atau mengunduh yang sudah jadi. notebook dari Github.
Kami mendapat set data. Apa selanjutnya?
Jadi, standarnya: Anda perlu memahami apa yang kita hadapi, gambaran besarnya. Kami akan menggunakan panda untuk ini untuk mendefinisikan tipe data yang berbeda.
import pandas as pd # pandas
import numpy as np # numpy
df = pd.read_csv("AB_NYC_2019.csv") # df
df.head(3) # 3 , , 
df.info() # 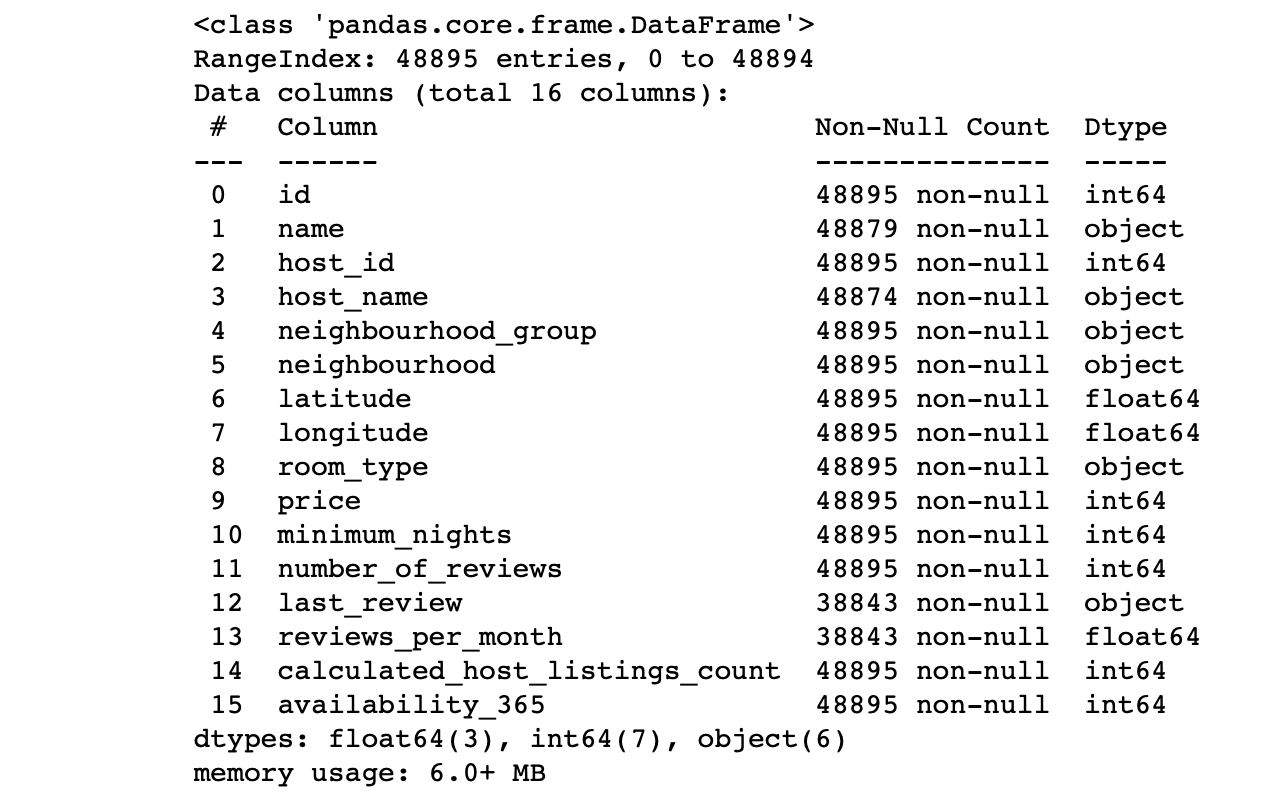
Kami melihat nilai kolom:
- Apakah jumlah baris di setiap kolom sesuai dengan jumlah baris?
- Apa inti dari data di setiap kolom?
- Untuk kolom apa kita ingin target membuat prediksi?
Jawaban atas pertanyaan-pertanyaan ini akan memungkinkan Anda untuk menganalisis kumpulan data dan secara kasar menggambar rencana untuk langkah selanjutnya.
Selain itu, untuk melihat lebih dalam nilai-nilai di setiap kolom, kita bisa menggunakan fungsi pandas description (). Namun, kelemahan dari fungsi ini adalah tidak memberikan informasi tentang kolom dengan nilai string. Kami akan menangani mereka nanti.
df.describe()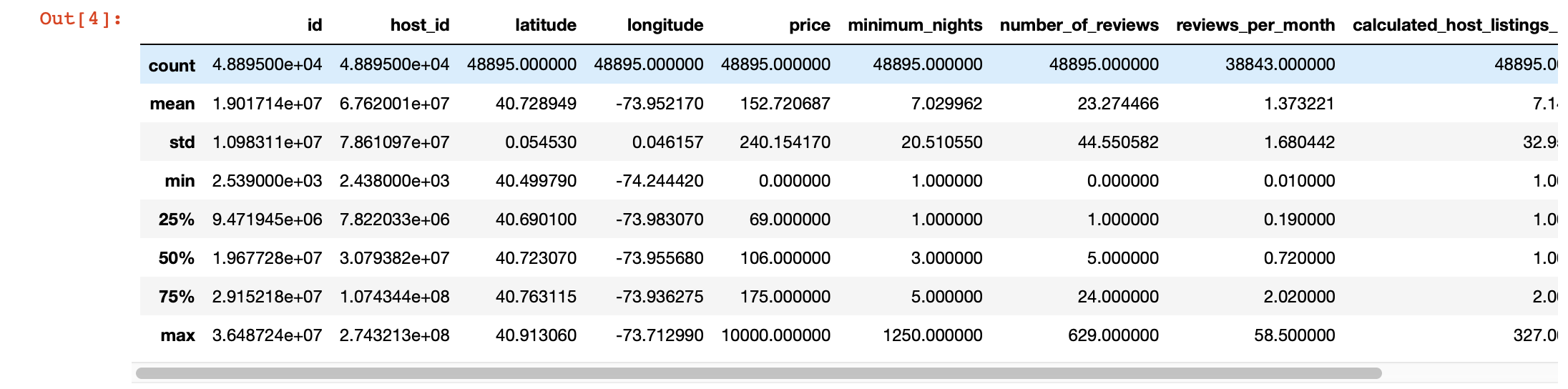
Visualisasi ajaib
Mari kita lihat di mana kita tidak memiliki nilai sama sekali:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')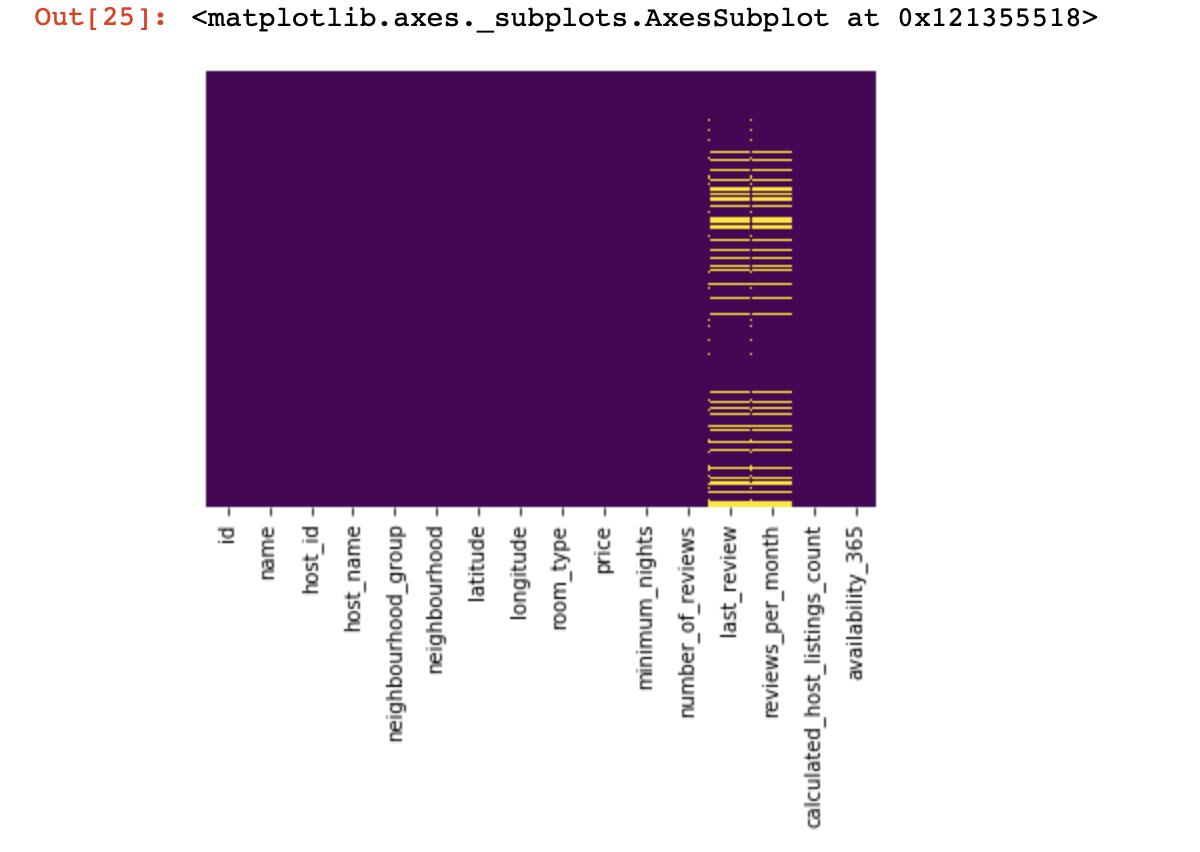
Itu adalah tampilan kecil dari atas, sekarang kita akan turun ke hal-hal yang lebih menarik Mari kita
coba mencari dan, jika mungkin, hapus kolom yang hanya memiliki satu nilai di semua baris (mereka tidak akan mempengaruhi hasil dengan cara apa pun):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] # , , Sekarang kami melindungi diri kami sendiri dan keberhasilan proyek kami dari garis duplikat (garis yang berisi informasi yang sama dalam urutan yang sama dengan salah satu garis yang ada):
df.drop_duplicates(inplace=True) # , .
# .Kami membagi dataset menjadi dua: satu dengan nilai kualitatif, dan yang lainnya dengan nilai kuantitatif
Di sini kita perlu membuat klarifikasi kecil: jika baris dengan data yang hilang dalam data kualitatif dan kuantitatif tidak berkorelasi kuat satu sama lain, maka perlu untuk memutuskan apa yang kita korbankan - semua baris dengan data yang hilang, hanya sebagian, atau kolom tertentu. Jika garis terkait, maka kita berhak membagi dataset menjadi dua. Jika tidak, pertama-tama Anda harus menangani garis-garis yang tidak menghubungkan data yang hilang secara kualitatif dan kuantitatif, dan baru kemudian membagi kumpulan data menjadi dua.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Kami melakukan ini untuk memudahkan kami memproses dua jenis data yang berbeda ini - nanti kami akan memahami betapa jauh lebih mudahnya hal itu membuat hidup kami.
Kami bekerja dengan data kuantitatif
Hal pertama yang harus kita lakukan adalah menentukan apakah ada "kolom mata-mata" dalam data kuantitatif. Kami menyebutnya kolom ini karena mereka berpura-pura menjadi data kuantitatif, dan mereka sendiri berfungsi sebagai data kualitatif.
Bagaimana kita mendefinisikannya? Tentu saja, itu semua bergantung pada sifat data yang Anda analisis, tetapi secara umum, kolom seperti itu mungkin memiliki sedikit data unik (di wilayah 3-10 nilai unik).
print(df_numerical.nunique())Setelah kami menentukan kolom mata-mata, kami akan memindahkannya dari data kuantitatif ke kualitatif:
spy_columns = df_numerical[['1', '2', '3']]# - dataframe
df_numerical.drop(labels=['1', '2', '3'], axis=1, inplace = True)#
df_categorical.insert(1, '1', spy_columns['1']) # -
df_categorical.insert(1, '2', spy_columns['2']) # -
df_categorical.insert(1, '3', spy_columns['3']) # - Akhirnya, kami benar-benar memisahkan data kuantitatif dari data kualitatif dan sekarang Anda dapat mengerjakannya dengan benar. Yang pertama adalah memahami di mana kita memiliki nilai kosong (NaN, dan dalam beberapa kasus 0 akan dianggap sebagai nilai kosong).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())Pada tahap ini, penting untuk memahami di kolom mana angka nol bisa berarti nilai yang hilang: apakah ini terkait dengan bagaimana data dikumpulkan? Atau mungkinkah itu terkait dengan nilai data? Pertanyaan-pertanyaan ini perlu dijawab berdasarkan kasus per kasus.
Jadi, jika kita memutuskan bahwa kita mungkin tidak memiliki data di mana ada nol, kita harus mengganti nol dengan NaN, sehingga akan lebih mudah untuk bekerja dengan data yang hilang ini nanti:
df_numerical[[" 1", " 2"]] = df_numerical[[" 1", " 2"]].replace(0, nan)Sekarang mari kita lihat di mana kita memiliki data yang hilang:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # df_numerical.info()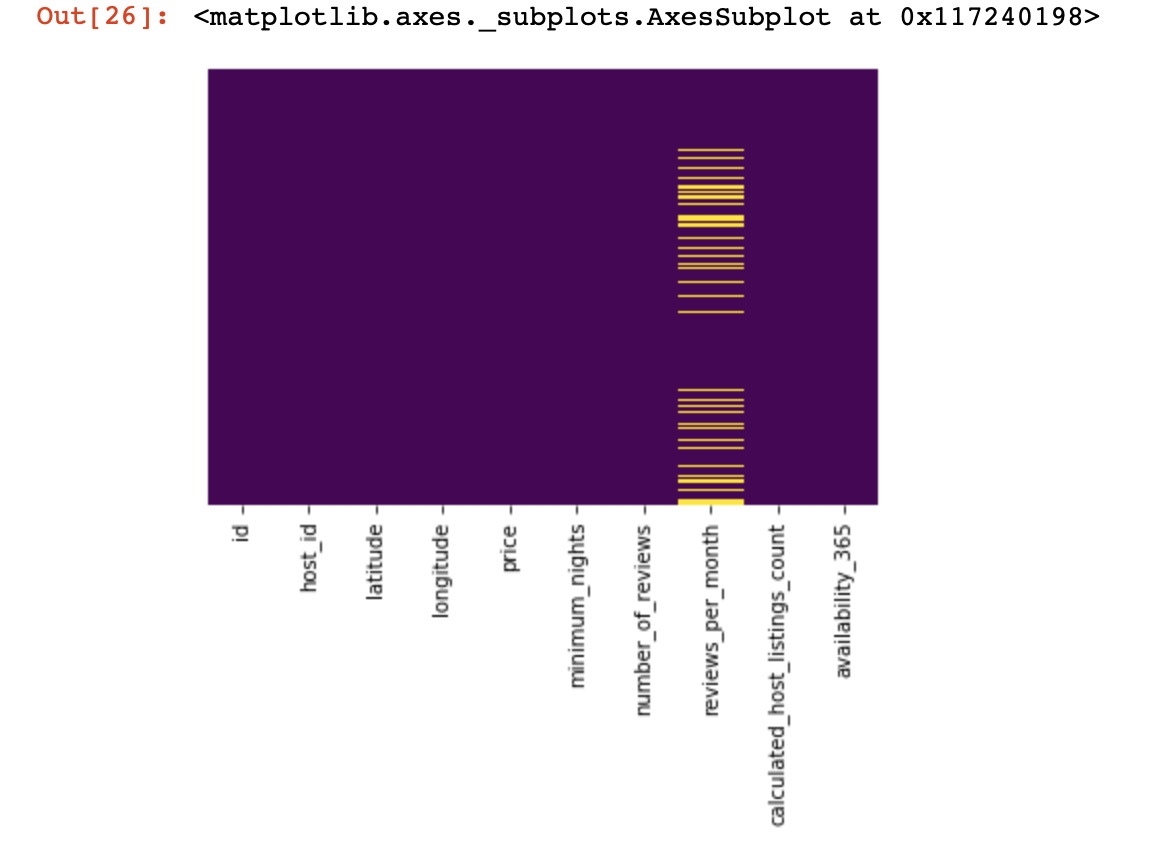
Di sini, nilai-nilai di dalam kolom yang hilang harus ditandai dengan warna kuning. Dan kesenangan dimulai sekarang - bagaimana berperilaku dengan nilai-nilai ini? Hapus baris dengan nilai atau kolom ini? Atau isi nilai kosong ini dengan yang lain?
Berikut ini diagram kasar yang dapat membantu Anda memutuskan apa yang pada dasarnya dapat Anda lakukan dengan nilai kosong:
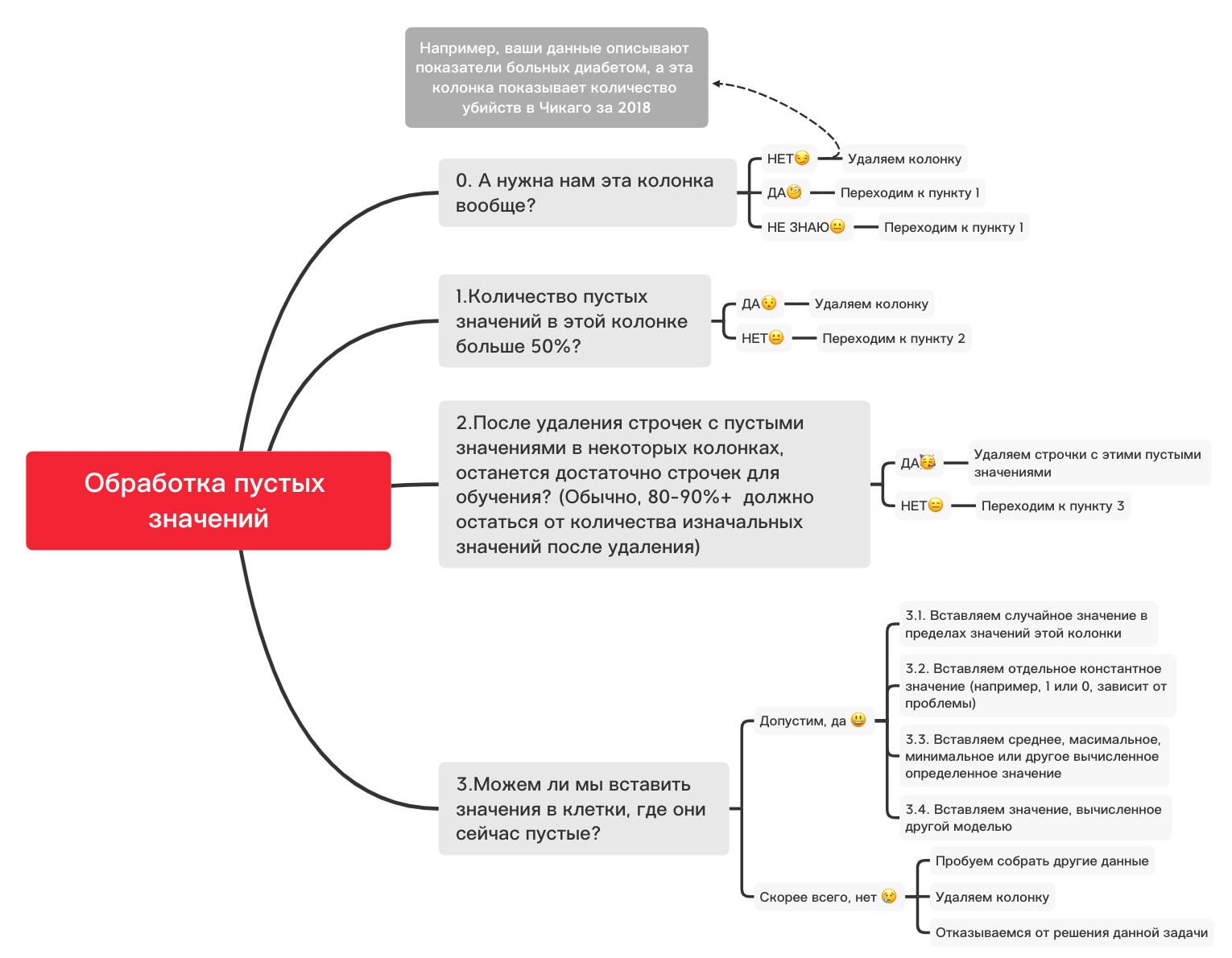
0. Hapus kolom yang tidak perlu
df_numerical.drop(labels=["1","2"], axis=1, inplace=True)1. Apakah ada lebih dari 50% nilai kosong di kolom ini?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["1","2"], axis=1, inplace=True)#, - 50 2. Hapus baris dengan nilai kosong
df_numerical.dropna(inplace=True)# , 3.1. Masukkan nilai acak
import random # random
df_numerical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True) # 3.2. Masukkan nilai konstan
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='constant', fill_value="< >") # SimpleImputer
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.3. Masukkan nilai rata-rata atau nilai yang paling sering
from sklearn.impute import SimpleImputer # SimpleImputer,
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) # mean most_frequent
df_numerical[["_1",'_2','_3']] = imputer.fit_transform(df_numerical[['1', '2', '3']]) #
df_numerical.drop(labels = ["1","2","3"], axis = 1, inplace = True) # 3.4. Memasukkan Nilai yang Dihitung dengan Model Lain
Terkadang nilai dapat dihitung menggunakan model regresi menggunakan model dari perpustakaan sklearn atau perpustakaan serupa lainnya. Tim kami akan memberikan artikel terpisah tentang bagaimana hal ini dapat dilakukan dalam waktu dekat.
Jadi, sementara narasi tentang data kuantitatif akan terputus, karena masih banyak nuansa lain tentang bagaimana lebih baik melakukan persiapan dan preprocessing data untuk berbagai tugas, dan hal-hal dasar untuk data kuantitatif telah diperhitungkan dalam artikel ini, dan sekarang saatnya kembali ke data kualitatif. yang telah kami pisahkan beberapa langkah mundur dari kuantitatif. Anda dapat mengubah buku catatan ini sesuka Anda, menyesuaikannya untuk berbagai tugas, sehingga pemrosesan awal data berjalan dengan sangat cepat!
Data kualitatif
Pada dasarnya, untuk kualitas data, metode One-hot-encoding digunakan untuk memformatnya dari string (atau objek) ke angka. Sebelum melanjutkan ke poin ini, mari gunakan diagram dan kode di atas untuk menangani nilai kosong.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis')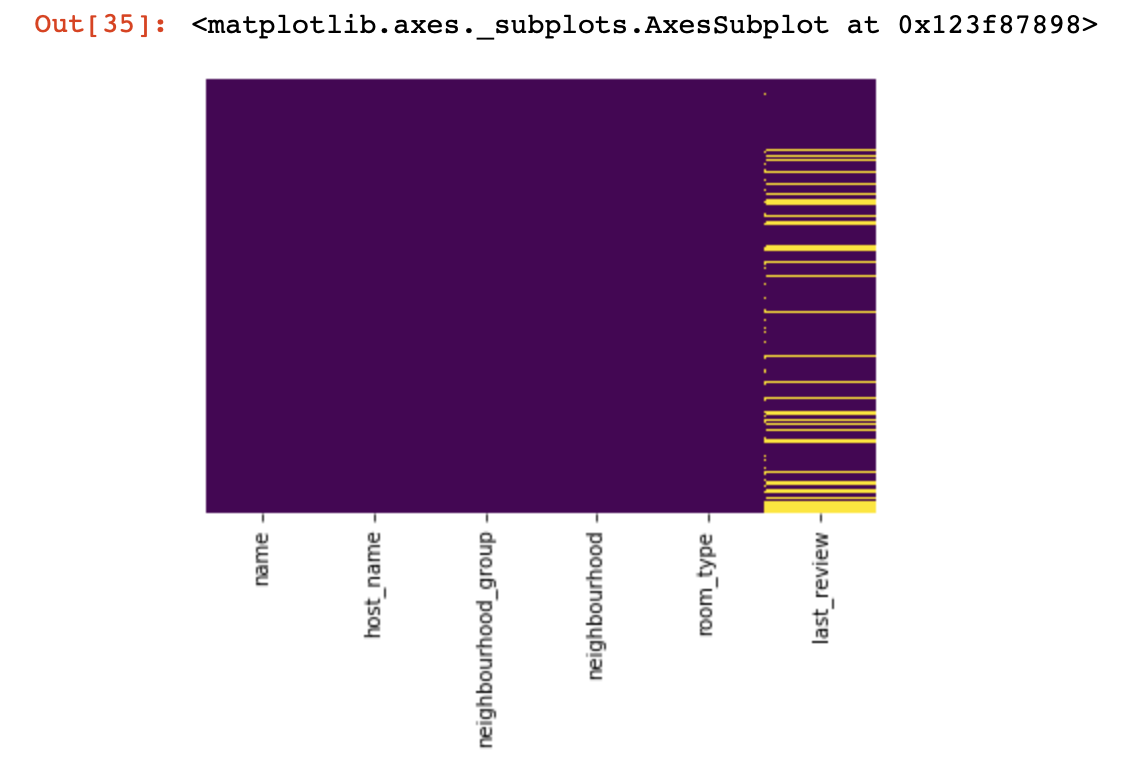
0. Menghapus kolom yang tidak perlu
df_categorical.drop(labels=["1","2"], axis=1, inplace=True)1. Apakah ada lebih dari 50% nilai kosong di kolom ini?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["1","2"], axis=1, inplace=True) #, -
# 50% 2. Hapus baris dengan nilai kosong
df_categorical.dropna(inplace=True)# ,
# 3.1. Masukkan nilai acak
import random
df_categorical[""].fillna(lambda x: random.choice(df[df[column] != np.nan][""]), inplace=True)3.2. Masukkan nilai konstan
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="< >")
df_categorical[["_1",'_2','_3']] = imputer.fit_transform(df_categorical[['1', '2', '3']])
df_categorical.drop(labels = ["1","2","3"], axis = 1, inplace = True)Jadi, akhirnya, kami berurusan dengan nilai-nilai kosong dalam data kualitas. Sekarang adalah waktunya untuk melakukan one-hot-encoding nilai-nilai yang ada di database Anda. Metode ini sangat sering digunakan untuk memastikan bahwa algoritme Anda dapat berlatih dengan data yang berkualitas.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["1","2","3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Jadi, akhirnya kita sudah selesai memproses data kualitatif dan kuantitatif secara terpisah - saatnya menggabungkannya kembali
new_df = pd.concat([df_numerical,df_categorical], axis=1)Setelah kita menggabungkan dataset menjadi satu, pada akhirnya kita bisa menggunakan transformasi data menggunakan MinMaxScaler dari library sklearn. Ini akan membuat nilai kita antara 0 dan 1, yang akan membantu saat melatih model di masa mendatang.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Data ini sekarang siap untuk apa saja - untuk jaringan neural, algoritme ML standar, dan sebagainya!
Dalam artikel ini, kami tidak memperhitungkan pekerjaan dengan data yang terkait dengan deret waktu, karena untuk data semacam itu, teknik pemrosesan yang sedikit berbeda harus digunakan, tergantung pada tugas Anda. Ke depannya, tim kami akan memberikan artikel tersendiri untuk topik ini, dan kami berharap dapat menghadirkan sesuatu yang menarik, baru, dan bermanfaat ke dalam hidup Anda, seperti ini.