
pengantar
Google Dorks atau Google Hacking adalah teknik yang digunakan oleh media, penyelidik, teknisi keamanan, dan siapa pun untuk menanyakan berbagai mesin pencari untuk menemukan informasi tersembunyi dan kerentanan yang dapat ditemukan di server publik. Ini adalah teknik di mana kueri penelusuran situs web biasa digunakan sepenuhnya untuk menentukan informasi yang tersembunyi di permukaan.
Bagaimana cara kerja Google Dorking?
Contoh pengumpulan dan analisis informasi ini, yang bertindak sebagai alat OSINT, bukanlah kerentanan Google atau perangkat untuk meretas hosting situs web. Sebaliknya, ini bertindak sebagai proses pengambilan data konvensional dengan kemampuan tingkat lanjut. Dan ini bukanlah hal baru, karena ada sejumlah besar situs web yang berusia lebih dari satu dekade dan berfungsi sebagai gudang untuk mempelajari dan menggunakan Google Hacking.
Sedangkan mesin pencari mengindeks, menyimpan header dan konten halaman, dan menautkannya bersama untuk permintaan pencarian yang optimal. Tapi sayangnya, web spider mesin pencari apapun dikonfigurasi untuk mengindeks semua informasi yang ditemukan. Meskipun administrator sumber daya web tidak berniat menerbitkan materi ini.
Namun, hal yang paling menarik tentang Google Dorking adalah banyaknya informasi yang dapat membantu semua orang dalam proses mempelajari proses pencarian Google. Dapat membantu pendatang baru untuk menemukan kerabat yang hilang, atau dapat mengajarkan cara mendapatkan informasi untuk keuntungan mereka sendiri. Secara umum, setiap sumber daya menarik dan menakjubkan dengan caranya sendiri-sendiri dan dapat membantu semua orang tentang apa yang sebenarnya dia cari.
Informasi apa yang dapat saya temukan melalui Dorks?
Mulai dari pengontrol akses jarak jauh dari berbagai mesin pabrik hingga antarmuka konfigurasi sistem kritis. Ada asumsi bahwa tidak ada yang akan menemukan sejumlah besar informasi yang diposting di internet.
Namun, mari kita lihat secara berurutan. Bayangkan kamera keamanan baru yang memungkinkan Anda menontonnya langsung di ponsel kapan saja. Anda mengatur dan menghubungkannya melalui Wi-Fi, dan mengunduh aplikasi untuk mengautentikasi login kamera keamanan. Setelah itu, Anda dapat mengakses kamera yang sama dari mana saja di dunia.
Di latar belakang, tidak semuanya terlihat sederhana. Kamera mengirimkan permintaan ke server China dan memutar video secara real time, memungkinkan Anda untuk masuk dan membuka umpan video yang dihosting di server di China dari ponsel Anda. Server ini mungkin tidak memerlukan kata sandi untuk mengakses umpan dari webcam Anda, membuatnya tersedia untuk umum bagi siapa saja yang mencari teks yang ada di halaman tampilan kamera.
Dan sayangnya, Google sangat efisien dalam menemukan perangkat apa pun di Internet yang berjalan di server HTTP dan HTTPS. Dan karena sebagian besar perangkat ini berisi beberapa jenis platform web untuk menyesuaikannya, ini berarti banyak hal yang tidak seharusnya ada di Google berakhir di sana.
Sejauh ini, jenis file yang paling serius adalah yang membawa kredensial pengguna atau seluruh perusahaan. Ini biasanya terjadi dalam dua cara. Pertama, server dikonfigurasi dengan tidak benar dan mengekspos log administratif atau log ke publik di Internet. Ketika kata sandi diubah atau pengguna tidak dapat masuk, arsip ini dapat bocor bersama dengan kredensial.
Opsi kedua terjadi ketika file konfigurasi yang berisi informasi yang sama (login, kata sandi, nama database, dll.) Tersedia untuk umum. File-file ini harus disembunyikan dari akses publik, karena seringkali meninggalkan informasi penting. Salah satu kesalahan ini dapat mengarah pada fakta bahwa penyerang menemukan celah ini dan mendapatkan semua informasi yang diperlukan.
Artikel ini mengilustrasikan penggunaan Google Dorks untuk menunjukkan tidak hanya cara menemukan semua file ini, tetapi juga seberapa rentan platform yang berisi informasi dalam bentuk daftar alamat, email, gambar, dan bahkan daftar webcam yang tersedia untuk umum.
Mengurai operator penelusuran
Dorking dapat digunakan di berbagai mesin pencari, tidak hanya di Google. Dalam penggunaan sehari-hari, mesin pencari seperti Google, Bing, Yahoo, dan DuckDuckGo mengambil kueri penelusuran atau string kueri penelusuran dan memberikan hasil yang relevan. Selain itu, sistem yang sama ini diprogram untuk menerima operator yang lebih canggih dan kompleks yang sangat mempersempit istilah pencarian ini. Operator adalah kata kunci atau frase yang memiliki arti khusus untuk mesin pencari. Contoh operator yang umum digunakan adalah: "inurl", "intext", "site", "feed", "language". Setiap operator diikuti oleh titik dua, diikuti dengan frase atau frase kunci yang sesuai.
Operator ini memungkinkan Anda untuk mencari informasi yang lebih spesifik, seperti baris teks tertentu di dalam halaman situs web, atau file yang dihosting di URL tertentu. Di antaranya, Google Dorking juga dapat menemukan halaman login tersembunyi, pesan kesalahan yang menampilkan informasi tentang kerentanan yang tersedia, dan file bersama. Alasan utamanya adalah karena administrator situs web mungkin lupa mengecualikan dari akses publik.
Layanan Google yang paling praktis dan sekaligus menarik adalah kemampuannya untuk mencari halaman yang dihapus atau diarsipkan. Ini dapat dilakukan dengan menggunakan operator "cache:". Operator bekerja sedemikian rupa sehingga menunjukkan versi halaman web yang disimpan (dihapus) yang disimpan di cache Google. Sintaks untuk operator ini ditampilkan di sini:
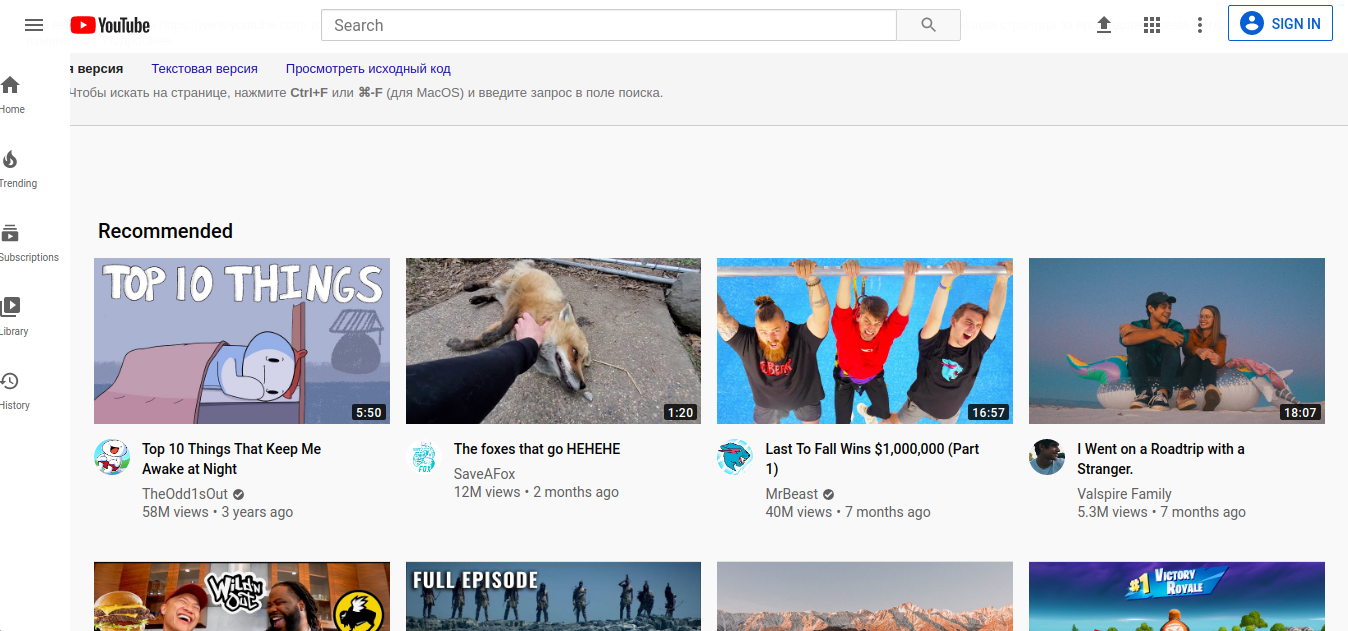
cache: www.youtube.com
Setelah membuat permintaan di atas ke Google, akses ke versi sebelumnya atau versi lama dari halaman web Youtube disediakan. Perintah ini memungkinkan Anda memanggil versi lengkap halaman, versi teks, atau sumber halaman itu sendiri (kode lengkap). Waktu yang tepat (tanggal, jam, menit, detik) dari pengindeksan yang dibuat oleh laba-laba Google juga ditunjukkan. Halaman ditampilkan dalam bentuk file grafik, meskipun pencarian di dalam halaman itu sendiri dilakukan dengan cara yang sama seperti pada halaman HTML biasa (pintasan keyboard CTRL + F). Hasil dari perintah "cache:" bergantung pada seberapa sering halaman web diindeks oleh Google. Jika pengembang sendiri menetapkan indikator dengan frekuensi kunjungan tertentu di bagian atas dokumen HTML, maka Google akan mengenali halaman tersebut sebagai halaman sekunder dan biasanya mengabaikannya demi rasio PageRank.yang merupakan faktor utama dalam frekuensi pengindeksan halaman. Oleh karena itu, jika laman web tertentu telah diubah di antara kunjungan oleh perayap Google, laman tersebut tidak akan diindeks atau dibaca menggunakan perintah "cache:". Contoh yang bekerja sangat baik saat menguji fitur ini adalah blog yang sering diperbarui, akun media sosial, dan portal online.
Informasi atau data terhapus yang ditempatkan karena kesalahan atau perlu dihapus pada suatu saat dapat dipulihkan dengan sangat mudah. Kelalaian administrator platform web dapat membuatnya berisiko menyebarkan informasi yang tidak diinginkan.
Informasi pengguna
Pencarian untuk informasi pengguna digunakan menggunakan operator tingkat lanjut, yang membuat hasil pencarian menjadi akurat dan rinci. Operator "@" digunakan untuk mencari pengguna yang mengindeks di jejaring sosial: Twitter, Facebook, Instagram. Menggunakan contoh universitas Polandia yang sama, Anda dapat menemukan perwakilan resminya, di salah satu platform sosial, menggunakan operator ini sebagai berikut:
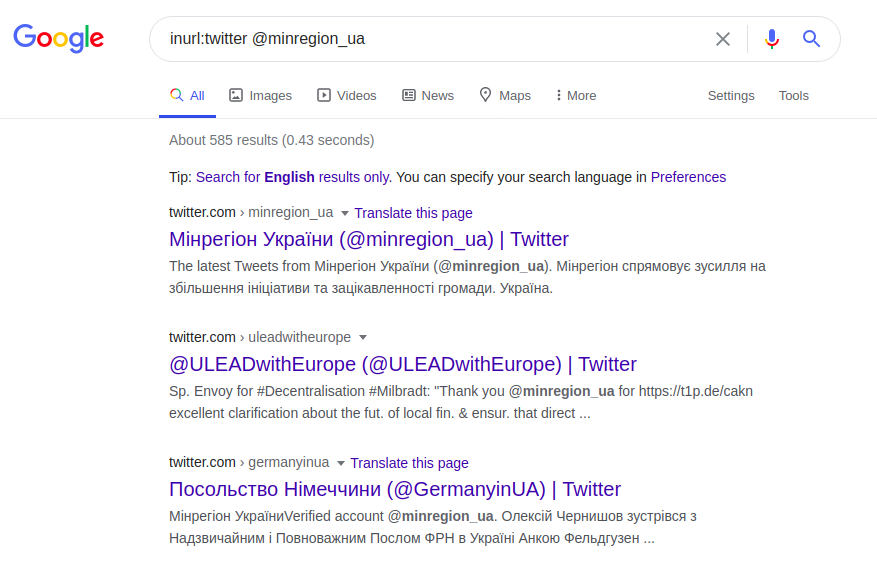
inurl: twitter
permintaan Twitter ini menemukan pengguna "minregionua". Dengan asumsi bahwa tempat atau nama karya pengguna yang kami cari (Kementerian Pengembangan Komunitas dan Wilayah Ukraina) dan namanya diketahui, Anda dapat membuat permintaan yang lebih spesifik. Dan alih-alih harus mencari-cari di seluruh halaman web institusi, Anda dapat menanyakan pertanyaan yang benar berdasarkan alamat email dan menganggap bahwa nama alamat harus menyertakan setidaknya nama pengguna atau institusi yang diminta. Misalnya:
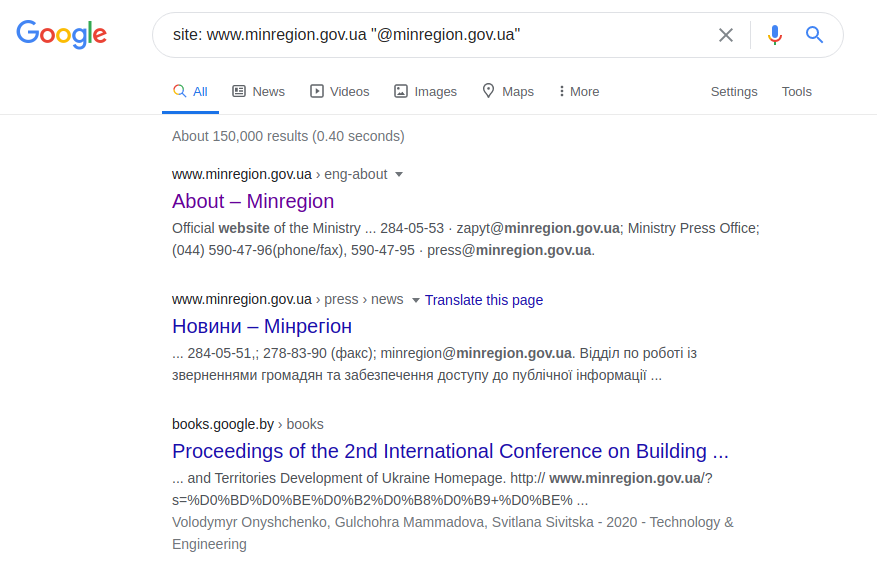
situs: www.minregion.gov.ua "@ minregion.ua"
Anda juga dapat menggunakan metode yang tidak terlalu rumit dan mengirim permintaan hanya ke alamat email, seperti yang ditunjukkan di bawah, dengan harapan keberuntungan dan kurangnya profesionalisme dari administrator sumber daya web.
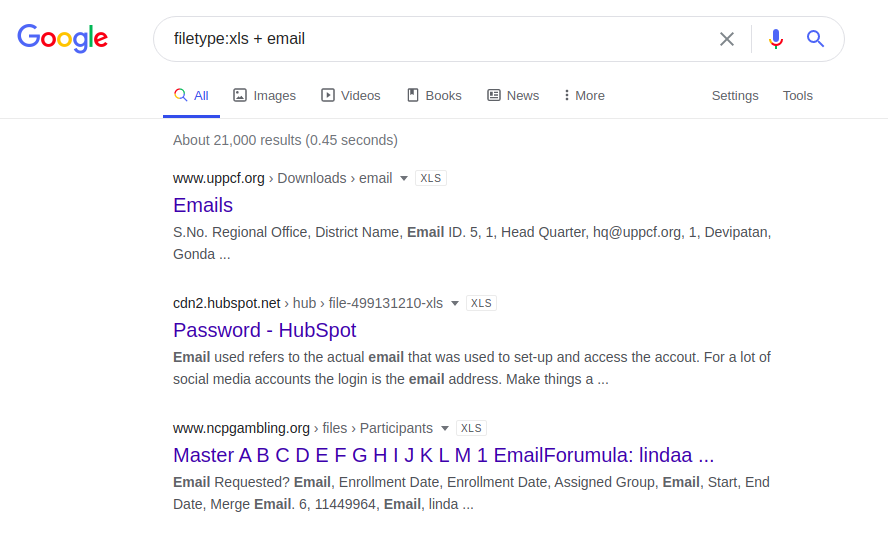
email.xlsx
filetype: xls + email
Selain itu, Anda dapat mencoba mendapatkan alamat email dari halaman web dengan permintaan berikut:

situs: www.minregion.gov.ua intext: e-mail
Permintaan di atas akan mencari kata kunci "email" pada halaman web Kementerian Pengembangan Komunitas dan Wilayah Ukraina. Menemukan alamat email adalah penggunaan yang terbatas dan umumnya memerlukan sedikit persiapan dan pengumpulan informasi pengguna sebelumnya.
Sayangnya, pencarian nomor telepon yang diindeks melalui buku telepon Google hanya terbatas di Amerika Serikat. Misalnya:
buku telepon: Arthur Mobile AL
Mencari informasi pengguna juga dimungkinkan melalui "pencarian gambar" Google atau pencarian gambar terbalik. Ini memungkinkan Anda menemukan foto yang identik atau mirip di situs yang diindeks oleh Google.
Informasi sumber daya web
Google memiliki beberapa operator berguna, khususnya "terkait:", yang menampilkan daftar situs web "serupa" dengan yang diinginkan. Kesamaan didasarkan pada tautan fungsional, bukan tautan logis atau bermakna.
related: minregion.gov.ua
Contoh ini menampilkan halaman-halaman Kementerian Ukraina lainnya. Operator ini bekerja seperti tombol "Halaman Terkait" dalam pencarian Google lanjutan. Dengan cara yang sama, permintaan "info:" bekerja, yang menampilkan informasi pada halaman web tertentu. Ini adalah informasi spesifik dari sebuah halaman web yang disajikan dalam judul situs web (), yaitu di tag meta description (<meta name = “Description”). Contoh:

info: minregion.gov.ua
Kueri lain, "define:" sangat berguna dalam menemukan karya ilmiah. Ini memungkinkan Anda untuk mendapatkan definisi kata dari sumber seperti ensiklopedia dan kamus online. Contoh penerapannya:
define: wilayah ukraina
Operator universal - tilde ("~"), memungkinkan Anda mencari kata atau sinonim yang mirip:
~ komunitas ~ pengembangan
Kueri di atas menampilkan situs web dengan kata "komunitas" (wilayah) dan "pembangunan" (pembangunan), dan situs web dengan sinonim "komunitas". Operator "link:", yang mengubah kueri, membatasi rentang pencarian ke link yang ditentukan untuk halaman tertentu.
link: www.minregion.gov.ua
Namun, operator ini tidak menampilkan semua hasil dan tidak memperluas kriteria pencarian.
Hashtag adalah sejenis nomor identifikasi yang memungkinkan Anda mengelompokkan informasi. Mereka saat ini digunakan di Instagram, VK, Facebook, Tumblr dan TikTok. Google memungkinkan Anda mencari banyak jejaring sosial secara bersamaan atau hanya yang direkomendasikan. Contoh kueri umum untuk mesin telusur apa pun adalah:
# polyticavukrainі
Operator "AROUND (n)" memungkinkan Anda mencari dua kata yang terletak pada jarak sejumlah kata dari satu sama lain. Contoh:

Ministry of AROUND (4) of Ukraine
Hasil dari query di atas adalah untuk menampilkan website yang mengandung dua kata ini (" Ministry " dan "Ukraine"), namun dipisahkan satu sama lain oleh empat kata lainnya.
Mencari berdasarkan jenis file juga sangat berguna, karena Google mengindeks konten menurut format perekamannya. Untuk melakukan ini, gunakan operator "filetype:". Ada berbagai macam pencarian file yang sedang digunakan. Dari semua mesin telusur yang tersedia, Google menyediakan sekumpulan operator paling canggih untuk mencari sumber terbuka.
Sebagai alternatif dari operator di atas, alat seperti Maltego dan Oryon OSINT Browser direkomendasikan. Mereka menyediakan pengambilan data otomatis dan tidak memerlukan pengetahuan operator khusus. Mekanisme programnya sangat sederhana: menggunakan kueri yang benar yang dikirim ke Google atau Bing, dokumen yang diterbitkan oleh lembaga yang Anda minati dapat ditemukan dan metadata dari dokumen ini dianalisis. Sumber daya informasi potensial untuk program tersebut adalah setiap file dengan ekstensi apa pun, misalnya: ".doc", ".pdf", ".ppt", ".odt", ".xls" atau ".jpg".
Selain itu, harus dijelaskan tentang cara merawat "membersihkan metadata Anda" dengan benar sebelum membuat file menjadi publik. Beberapa panduan web menyediakan setidaknya beberapa cara untuk menghilangkan informasi meta. Namun, tidak mungkin untuk menyimpulkan cara terbaik, karena semuanya tergantung pada preferensi individu dari administrator itu sendiri. Umumnya disarankan agar Anda menulis file dalam format yang awalnya tidak menyimpan metadata, lalu membuat file tersebut tersedia. Ada banyak program pembersihan metadata gratis di Internet, terutama untuk gambar. ExifCleaner dapat dianggap sebagai salah satu yang paling diinginkan. Untuk file teks, sangat disarankan agar Anda membersihkannya secara manual.
Informasi yang tanpa sadar ditinggalkan oleh pemilik situs
Sumber daya yang diindeks oleh Google tetap bersifat publik (misalnya, dokumen internal dan materi perusahaan yang ditinggalkan di server), atau disimpan demi kenyamanan oleh orang yang sama (misalnya, file musik atau file film). Menelusuri konten semacam itu dapat dilakukan dengan Google dengan berbagai cara, dan yang termudah hanyalah menebak. Jika, misalnya, ada file 5.jpg, 8.jpg dan 9.jpg di direktori tertentu, Anda dapat memprediksi bahwa ada file dari 1 hingga 4, dari 6 hingga 7, dan bahkan lebih 9. Oleh karena itu, Anda dapat mengakses materi yang seharusnya tidak berada di depan umum. Cara lain adalah mencari jenis konten tertentu di situs web. Anda dapat mencari file musik, foto, film dan buku (e-book, audiobook).
Dalam kasus lain, ini mungkin file yang ditinggalkan pengguna tanpa disadari di domain publik (misalnya, musik di server FTP untuk digunakan sendiri). Informasi ini dapat diperoleh dengan dua cara: menggunakan operator "filetype:" atau operator "inurl:". Misalnya:
filetype: situs doc: gov.ua
situs: www.minregion.gov.ua filetype: pdf
situs: www.minregion.gov.ua inurl: doc
Anda juga dapat mencari file program menggunakan permintaan pencarian dan memfilter file yang diinginkan dengan ekstensinya:
filetype: iso
Informasi tentang struktur halaman web
Untuk melihat struktur halaman web tertentu dan mengungkapkan seluruh strukturnya, yang akan membantu server dan kerentanannya di masa mendatang, Anda dapat melakukannya hanya dengan menggunakan operator "site:". Mari kita analisis frasa berikut:
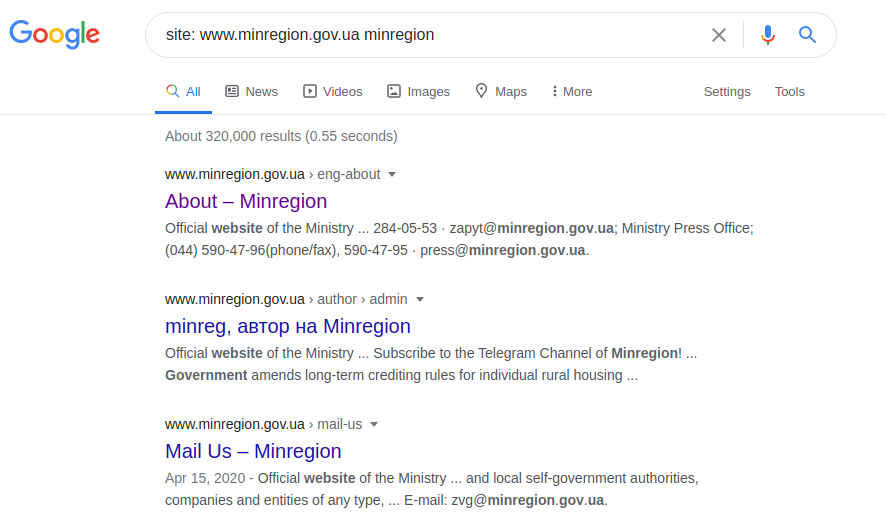
situs: www.minregion.gov.ua minregion
Kami mulai mencari kata "minregion" di domain "www.minregion.gov.ua". Setiap situs dari domain ini (pencarian Google baik dalam teks, dalam tajuk dan judul situs) mengandung kata ini. Dengan demikian, mendapatkan struktur lengkap dari semua situs untuk domain tertentu tersebut. Setelah struktur direktori tersedia, hasil yang lebih akurat (meskipun ini mungkin tidak selalu terjadi) dapat diperoleh dengan kueri berikut:
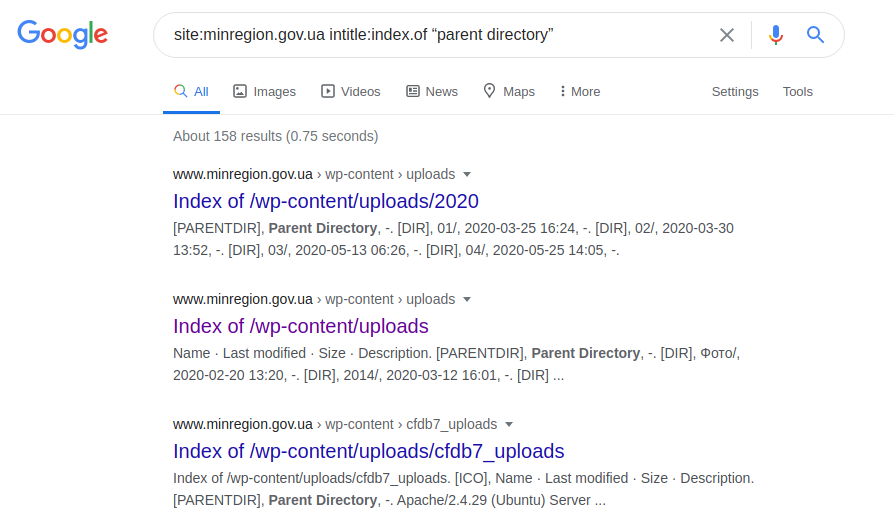
site: minregion.gov.ua intitle: index.of "direktori induk"
Ini menunjukkan subdomain yang paling tidak terlindungi dari "minregion.gov.ua", terkadang dengan kemampuan untuk mencari seluruh direktori, bersama dengan kemungkinan upload file. Oleh karena itu, tentu saja, permintaan seperti itu tidak berlaku untuk semua domain, karena domain tersebut dapat dilindungi atau dijalankan di bawah kendali beberapa server lain.
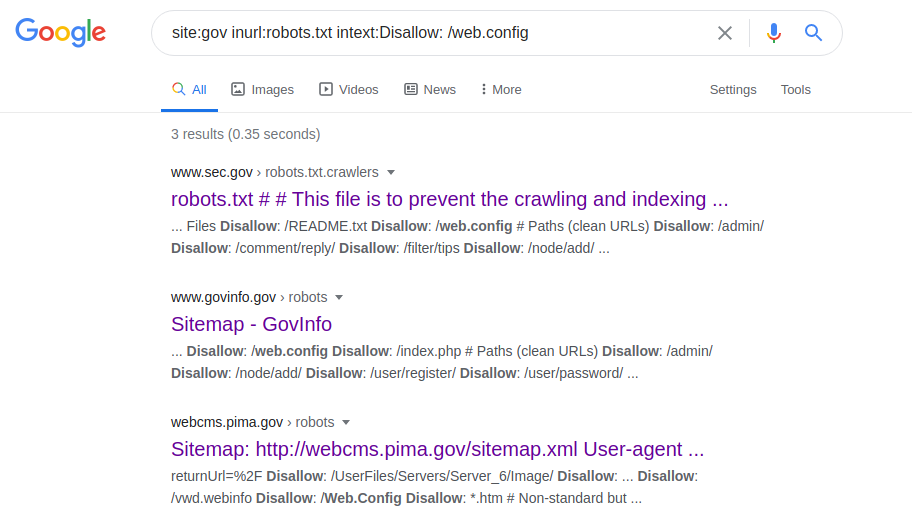
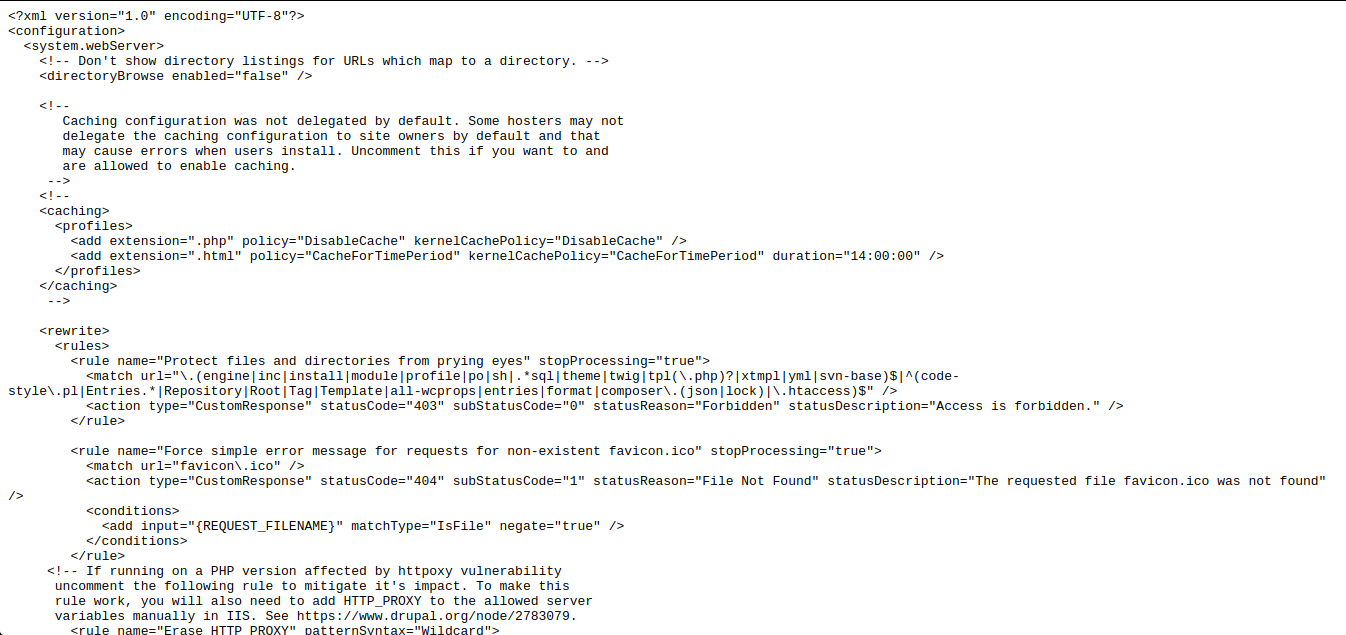
situs: gov inurl: robots.txt intext: Disallow: /web.config
Operator ini memungkinkan Anda untuk mengakses parameter konfigurasi dari berbagai server. Setelah membuat permintaan, buka file robots.txt, cari jalur ke "web.config" dan buka jalur file yang ditentukan. Untuk mendapatkan nama server, versinya, dan parameter lainnya (misalnya, port), permintaan berikut dibuat:
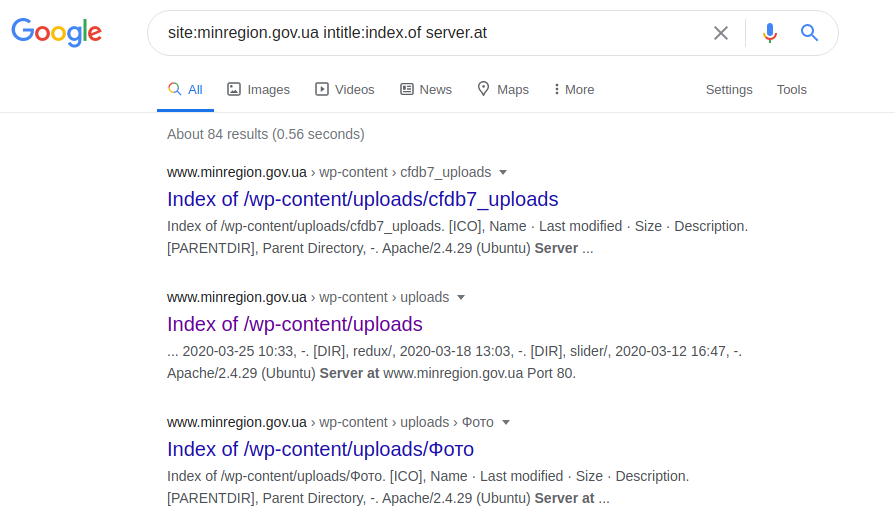
situs: gosstandart.gov.by intitle: index.of server.at
Setiap server memiliki beberapa frase unik di halaman utamanya, misalnya, Internet Information Service (IIS):
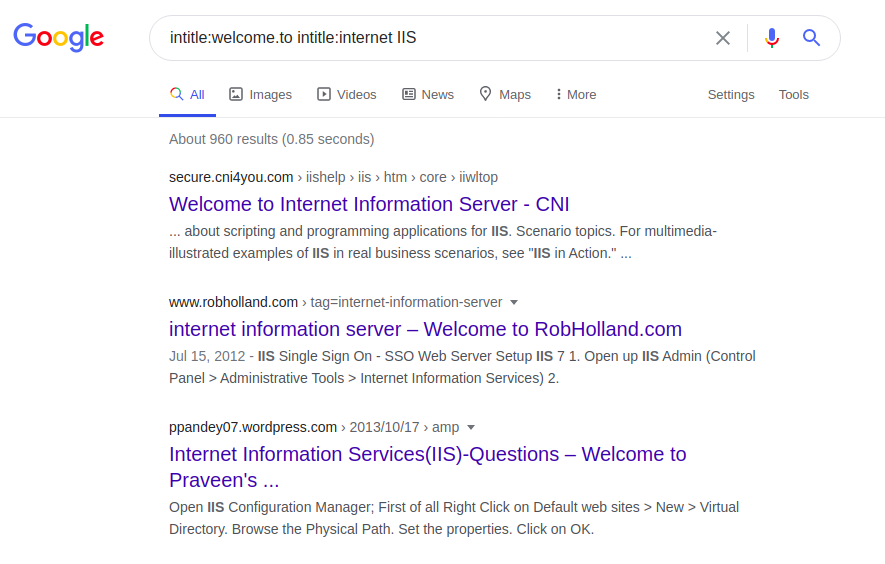
intitle: welcome.to intitle: internet IIS
Definisi dari server itu sendiri dan teknologi yang digunakan di dalamnya hanya bergantung pada kecerdikan permintaan yang ditanyakan. Anda dapat, misalnya, mencoba melakukan ini dengan menjelaskan spesifikasi teknis, manual, atau yang disebut halaman bantuan. Untuk mendemonstrasikan kapabilitas ini, Anda bisa menggunakan kueri berikut ini:
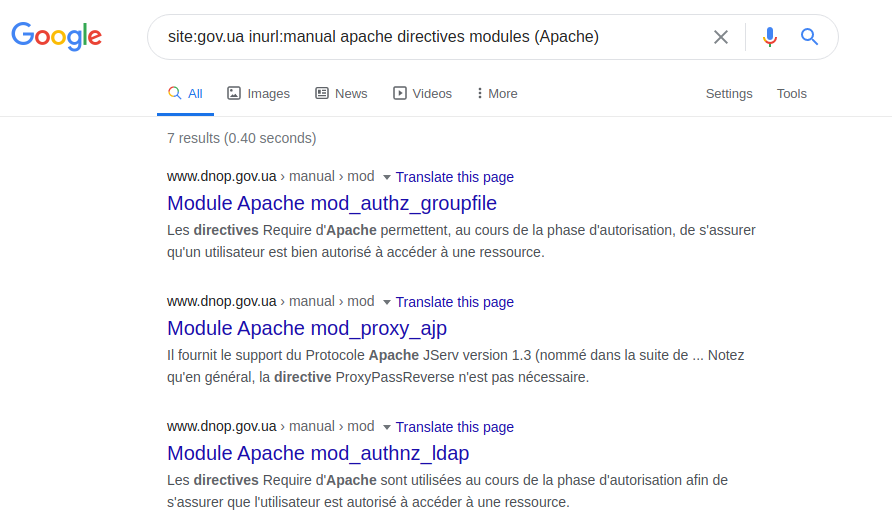
site: gov.ua inurl: modul direktif apache manual (Apache)
Akses dapat diperpanjang, misalnya, berkat file dengan kesalahan SQL:
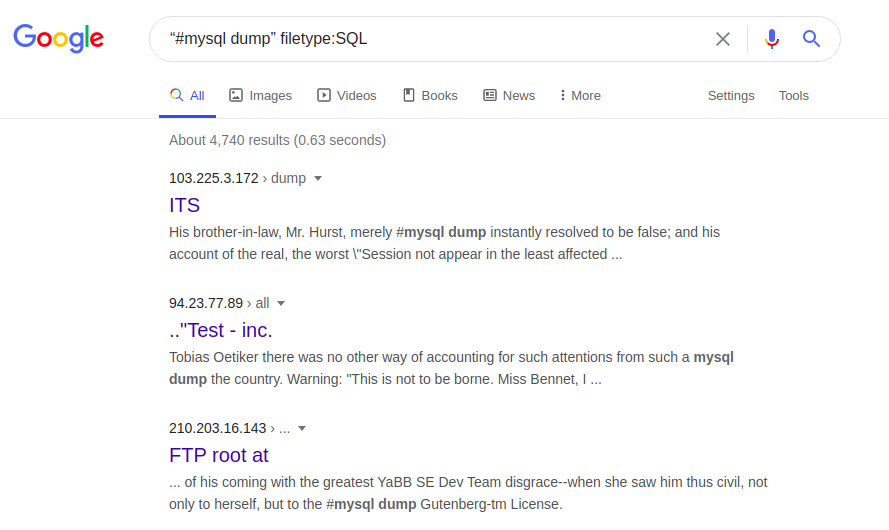
Jenis file "#Mysql dump":
Kesalahan SQL dalam database SQL dapat, khususnya, memberikan informasi tentang struktur dan konten database. Pada gilirannya, seluruh halaman web, versi aslinya dan / atau yang diperbarui dapat diakses dengan permintaan berikut:
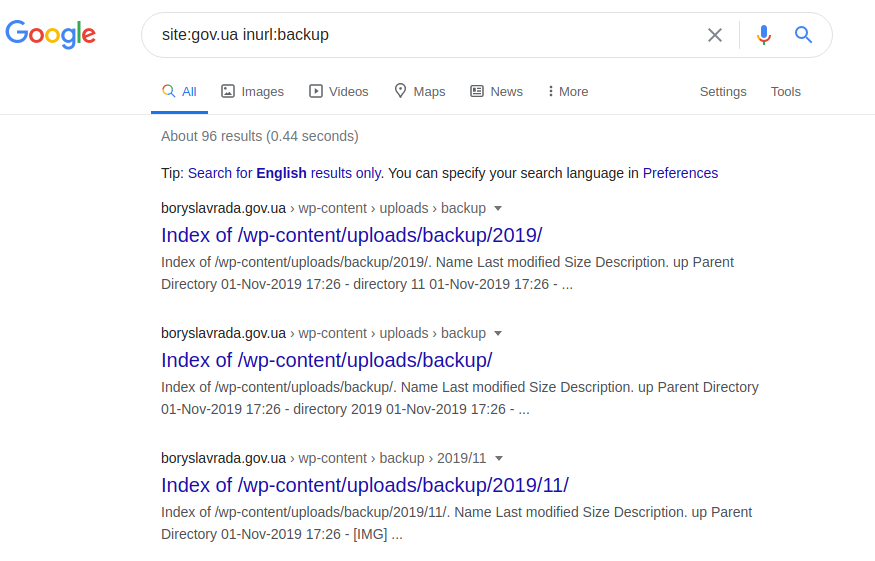
situs: gov.ua inurl:
situs cadangan : gov.ua inurl: backup intitle: index.of inurl: admin
Saat ini, penggunaan operator di atas jarang memberikan hasil yang diharapkan, karena dapat diblokir terlebih dahulu oleh pengguna yang berpengetahuan.
Selain itu, dengan menggunakan program FOCA, Anda dapat menemukan konten yang sama seperti saat mencari operator di atas. Untuk memulai, program memerlukan nama nama domain, setelah itu akan menganalisis struktur seluruh domain dan semua subdomain lain yang terhubung ke server lembaga tertentu. Informasi ini dapat ditemukan di kotak dialog di bawah tab Jaringan:
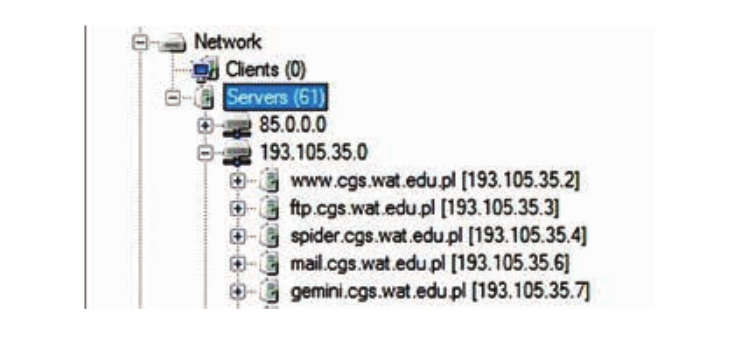
Dengan demikian, penyerang potensial dapat mencegat data yang ditinggalkan oleh administrator web, dokumen internal, dan materi perusahaan yang tertinggal bahkan di server tersembunyi.
Jika Anda ingin mengetahui lebih banyak informasi tentang semua kemungkinan operator pengindeksan, Anda dapat memeriksa database target dari semua operator Google Dorking di sini . Anda juga dapat membiasakan diri dengan satu proyek menarik di GitHub, yang telah mengumpulkan semua tautan URL yang paling umum dan rentan dan mencoba mencari sesuatu yang menarik untuk diri Anda sendiri, Anda dapat melihatnya di sini di tautan ini .
Menggabungkan dan mendapatkan hasil
Untuk contoh yang lebih spesifik, di bawah ini adalah kumpulan kecil operator Google yang umum digunakan. Dalam kombinasi berbagai informasi tambahan dan perintah yang sama, hasil pencarian menunjukkan tampilan yang lebih rinci tentang proses mendapatkan informasi rahasia. Bagaimanapun, untuk mesin pencari biasa Google, proses pengumpulan informasi ini bisa sangat menarik.
Cari anggaran di situs web Departemen Keamanan Dalam Negeri dan Keamanan Siber AS.
Kombinasi berikut ini menyediakan semua spreadsheet Excel yang diindeks secara publik yang berisi kata "anggaran":
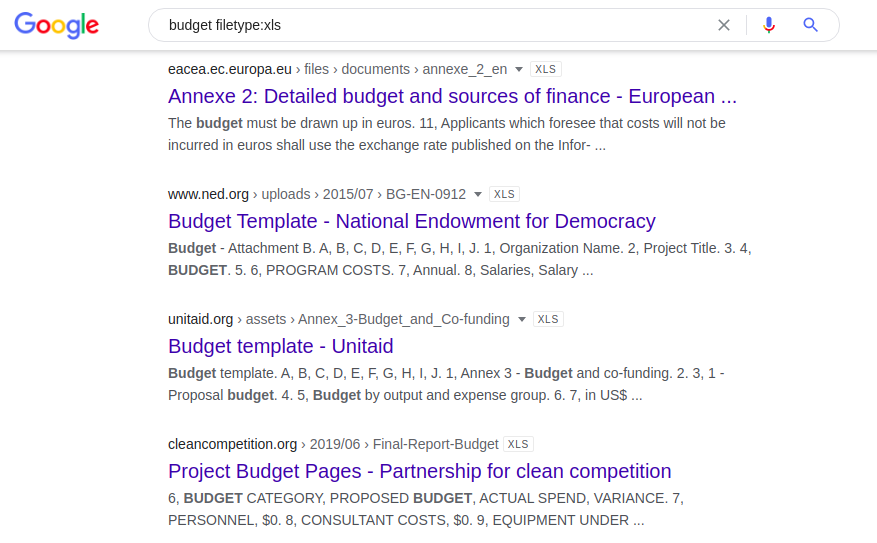
budget filetype: xls
Karena operator "filetype:" tidak secara otomatis mengenali versi berbeda dari format file yang sama (mis. doc versus odt atau xlsx versus csv), masing-masing format ini harus dibagi secara terpisah:
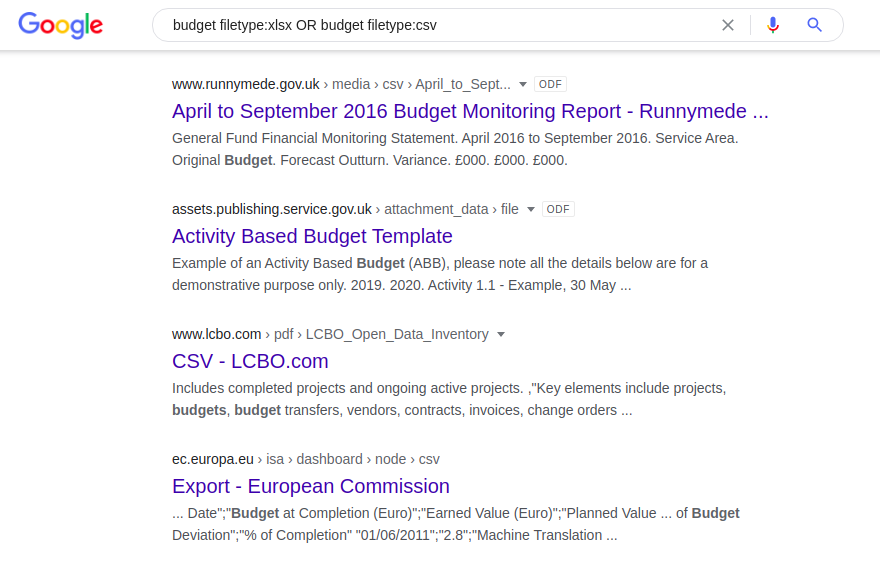
budget filetype: xlsx ATAU budget filetype: csv
Selanjutnya dork akan mengembalikan file PDF di situs NASA:
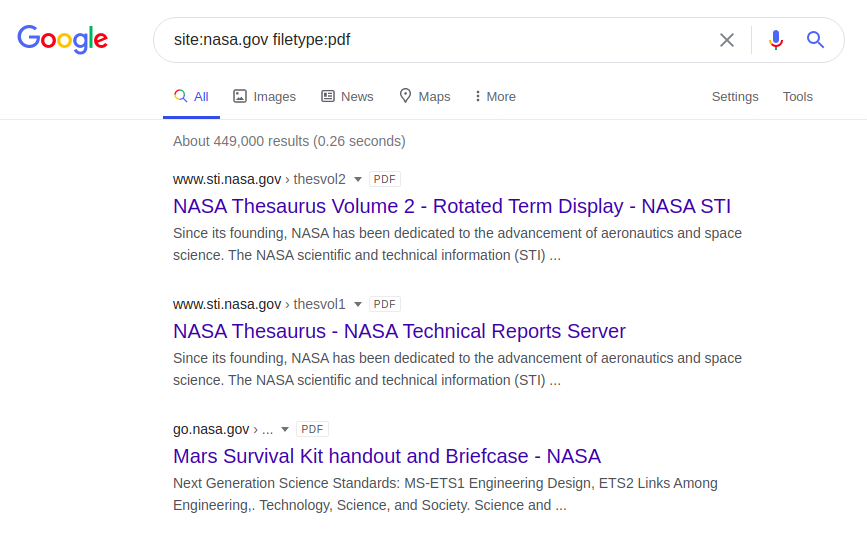
site: nasa.gov filetype: pdf
Contoh menarik lainnya dari penggunaan dork dengan kata kunci "budget" adalah mencari dokumen cybersecurity AS dalam format "pdf" di situs resmi Departemen Pertahanan Dalam Negeri.
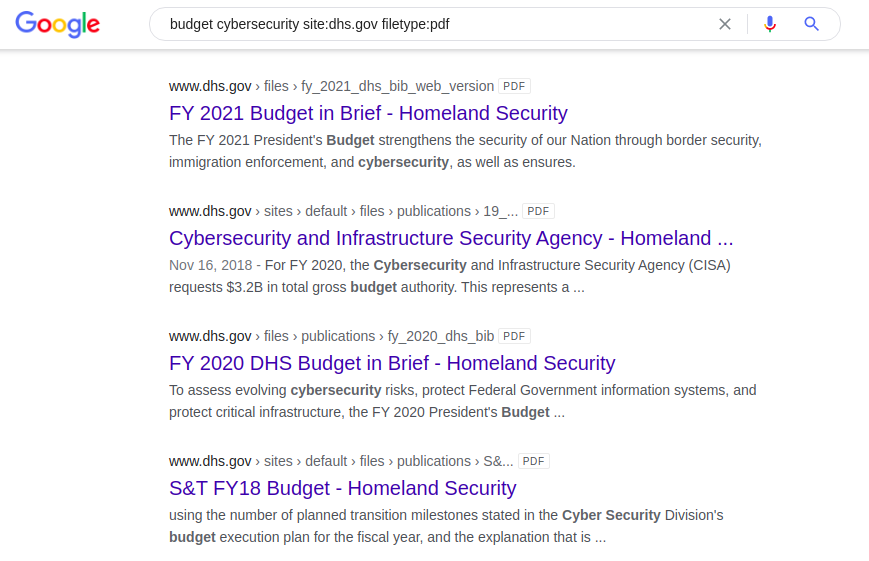
budget cybersecurity site: dhs.gov filetype: pdf
Aplikasi dork yang sama, tapi kali ini mesin pencari akan mengembalikan spreadsheet .xlsx yang berisi kata "budget" di website Departemen Keamanan Dalam Negeri AS:
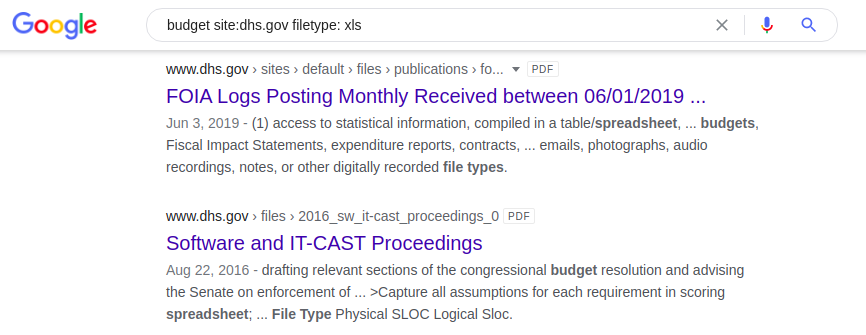
situs anggaran: dhs.gov filetype: xls
Cari kata sandi
Mencari informasi dengan login dan kata sandi dapat berguna sebagai pencarian kerentanan pada sumber daya Anda sendiri. Jika tidak, kata sandi disimpan dalam dokumen bersama di server web. Anda dapat mencoba kombinasi berikut di mesin pencari yang berbeda:
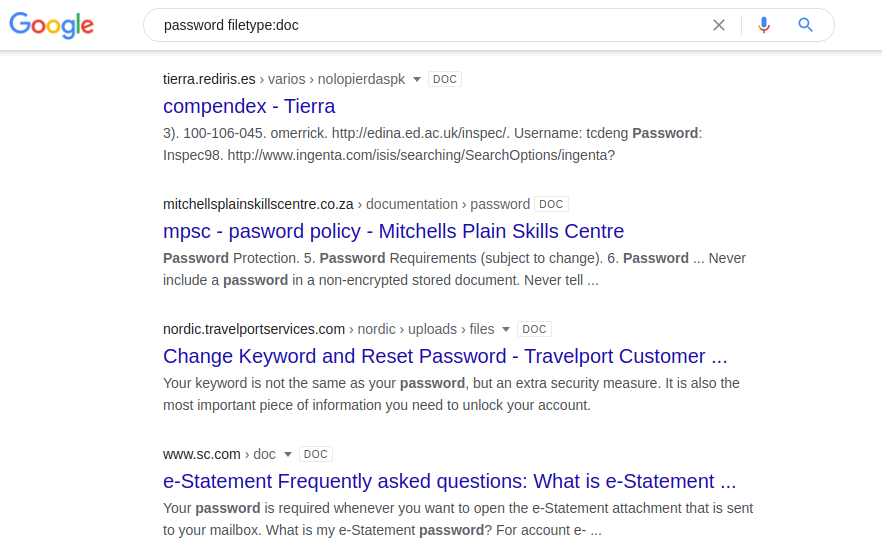
jenis file kata sandi: doc / docx / pdf / xls
kata sandi filetype: doc / docx / pdf / xls situs: [Nama situs]
Jika Anda mencoba memasukkan kueri seperti itu di mesin pencari lain, Anda bisa mendapatkan hasil yang sangat berbeda. Misalnya, jika Anda menjalankan kueri ini tanpa istilah "situs: [Nama Situs] ", Google akan mengembalikan hasil dokumen yang berisi nama pengguna dan sandi asli dari beberapa sekolah menengah di Amerika. Mesin pencari lain tidak menampilkan informasi ini di halaman pertama hasil pencarian. Seperti yang Anda lihat di bawah, Yahoo dan DuckDuckGo adalah contohnya.
Harga rumah di London
Contoh menarik lainnya menyangkut informasi tentang harga perumahan di London. Di bawah ini adalah hasil kueri yang dimasukkan di empat mesin pencari berbeda:
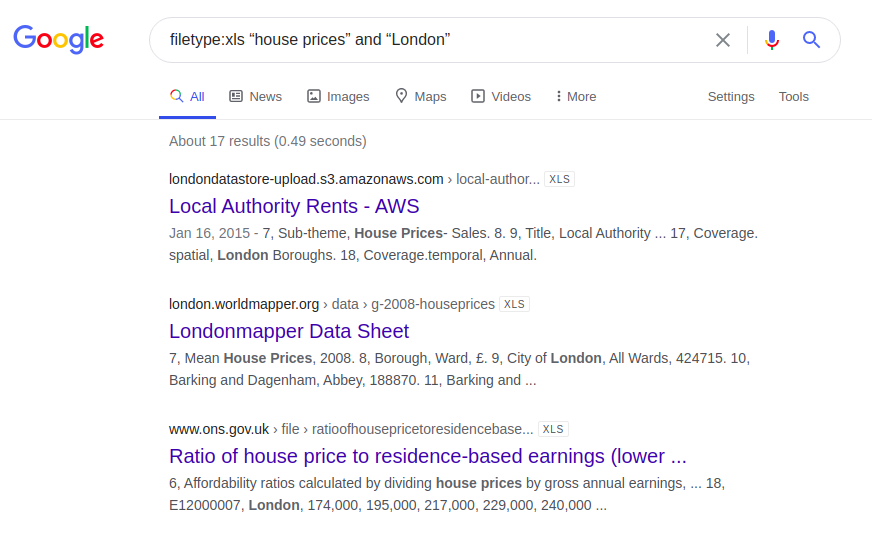
filetype: xls "harga rumah" dan "London"
Mungkin Anda sekarang memiliki ide dan gagasan sendiri tentang situs web mana yang ingin Anda fokuskan dalam pencarian informasi Anda sendiri, atau cara memeriksa sumber daya Anda sendiri dengan benar untuk kemungkinan kerentanan ...
Alat pengindeksan pencarian alternatif
Ada juga metode lain untuk mengumpulkan informasi menggunakan Google Dorking. Semuanya adalah alternatif dan bertindak sebagai otomatisasi pencarian. Di bawah ini kami mengusulkan untuk melihat beberapa proyek paling populer yang tidak berdosa untuk dibagikan.
Google Hacking Online
Google Hacking Online adalah integrasi online pencarian Google Dorking berbagai data melalui halaman web menggunakan operator mapan, yang dapat Anda temukan di sini . Alat tersebut adalah bidang masukan sederhana untuk menemukan alamat IP atau URL yang diinginkan dari tautan ke sumber daya yang diminati, bersama dengan opsi pencarian yang disarankan.
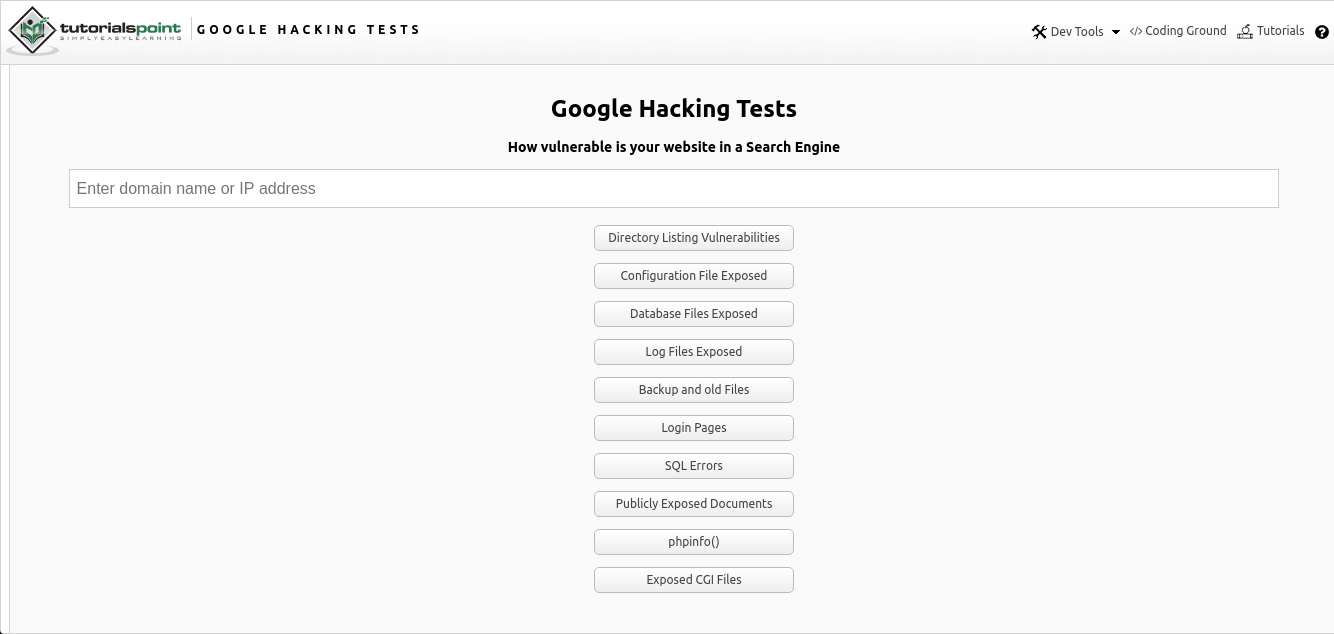
Seperti yang Anda lihat dari gambar di atas, pencarian berdasarkan beberapa parameter disediakan dalam bentuk beberapa pilihan:
- Cari direktori publik dan rentan
- File konfigurasi
- File database
- Log
- Data lama dan data cadangan
- Halaman Otentikasi
- Kesalahan SQL
- Dokumen yang tersedia untuk umum
- Informasi konfigurasi php server ("phpinfo")
- File Common Gateway Interface (CGI)
Semuanya bekerja pada vanilla JS, yang ditulis dalam file halaman web itu sendiri. Pada awalnya diambil informasi pengguna yang dimasukkan, yaitu nama host atau alamat IP halaman web. Dan kemudian permintaan dibuat dengan operator untuk informasi yang dimasukkan. Tautan untuk mencari sumber daya tertentu terbuka di jendela pop-up baru dengan hasil yang disediakan.
BinGoo
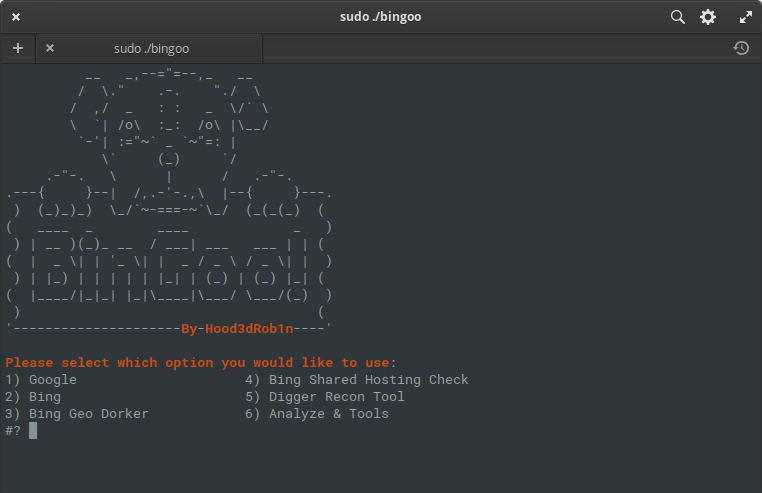
BinGoo adalah alat serbaguna yang ditulis dalam bash murni. Ini menggunakan operator pencarian Google dan Bing untuk memfilter sejumlah besar tautan berdasarkan istilah pencarian yang disediakan. Anda dapat memilih untuk mencari satu operator dalam satu waktu, atau membuat daftar satu operator per baris dan melakukan pemindaian massal. Setelah proses pengumpulan awal selesai, atau Anda memiliki tautan yang dikumpulkan dengan cara lain, Anda dapat melanjutkan ke alat analisis untuk memeriksa tanda-tanda umum kerentanan.
Hasil diurutkan dengan rapi ke dalam file yang sesuai berdasarkan hasil yang diperoleh. Tetapi analisis tidak berhenti di sini juga, Anda dapat melangkah lebih jauh dan menjalankannya menggunakan fungsionalitas SQL atau LFI tambahan, atau Anda dapat menggunakan alat pembungkus SQLMAP dan FIMAP, yang bekerja jauh lebih baik, dengan hasil yang akurat.
Juga disertakan beberapa fitur berguna untuk membuat hidup lebih mudah, seperti geodorking berdasarkan jenis domain, kode negara dalam domain, dan pemeriksa hosting bersama yang menggunakan pencarian Bing yang telah dikonfigurasi dan daftar konyol untuk mencari kemungkinan kerentanan di situs lain. Juga termasuk pencarian sederhana untuk halaman admin berdasarkan daftar yang disediakan dan kode respon server untuk konfirmasi. Secara umum, ini adalah paket alat yang sangat menarik dan ringkas yang melakukan pengumpulan dan analisis utama dari informasi yang diberikan! Anda bisa mengenalinya di sini .
Pagodo
Tujuan dari alat Pagodo adalah untuk mengindeks pasif oleh operator Google Dorking untuk mengumpulkan halaman web dan aplikasi yang berpotensi rentan melalui Internet. Program ini terdiri dari dua bagian. Yang pertama adalah ghdb_scraper.py, yang menanyakan dan mengumpulkan operator Google Dorks, dan yang kedua, pagodo.py, menggunakan operator dan informasi yang dikumpulkan melalui ghdb_scraper.py dan mem-parsingnya melalui kueri Google.
File pagodo.py membutuhkan daftar operator Google Dorks untuk memulai. File serupa disediakan baik dalam repositori proyek itu sendiri, atau Anda cukup menanyakan seluruh database melalui satu permintaan GET menggunakan ghdb_scraper.py. Dan kemudian salin saja pernyataan dorks individu ke file teks atau letakkan di json jika lebih banyak data konteks diperlukan.
Untuk melakukan operasi ini, Anda harus memasukkan perintah berikut:
python3 ghdb_scraper.py -j -sSekarang, setelah ada file dengan semua operator yang diperlukan, file tersebut dapat dialihkan ke pagodo.py menggunakan opsi "-g" untuk mulai mengumpulkan aplikasi yang berpotensi rentan dan publik. File pagodo.py menggunakan pustaka "google" untuk menemukan situs-situs ini menggunakan operator seperti ini:
intitle: "Login ListMail" admin -demo
situs: example.com
Sayangnya, proses begitu banyak permintaan (yaitu ~ 4600) melalui Google sederhana Tidak akan berhasil. Google akan segera mengidentifikasi Anda sebagai bot dan memblokir alamat IP untuk jangka waktu tertentu. Beberapa perbaikan telah ditambahkan untuk membuat kueri penelusuran terlihat lebih organik.
Modul google Python telah secara khusus di-tweak untuk memungkinkan pengacakan agen pengguna di seluruh pencarian Google. Fitur ini tersedia dalam modul versi 1.9.3 dan memungkinkan Anda untuk mengacak agen pengguna berbeda yang digunakan untuk setiap kueri penelusuran. Fitur ini memungkinkan Anda untuk meniru browser berbeda yang digunakan di lingkungan perusahaan besar.
Peningkatan kedua berfokus pada pengacakan waktu di antara pencarian. Penundaan minimum ditentukan menggunakan parameter -e, dan faktor jitter digunakan untuk menambahkan waktu ke jumlah minimum penundaan. Daftar 50 getaran dibuat dan salah satunya ditambahkan secara acak ke latensi minimum untuk setiap pencarian Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Lebih jauh dalam skrip, waktu acak dipilih dari array jitter dan ditambahkan ke penundaan dalam membuat permintaan:
pause_time = self.delay + random.choice (self.jitter)Anda dapat bereksperimen dengan nilainya sendiri, tetapi pengaturan default berfungsi dengan baik. Harap dicatat bahwa proses alat dapat memakan waktu beberapa hari (rata-rata 3; tergantung pada jumlah operator yang ditentukan dan interval permintaan), jadi pastikan Anda punya waktu untuk ini.
Untuk menjalankan alat itu sendiri, perintah berikut sudah cukup, di mana "example.com" adalah tautan ke situs web yang diinginkan, dan "dorks.txt" adalah file teks yang dibuat oleh ghdb_scraper.py:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1Dan Anda dapat menyentuh dan membiasakan diri dengan alat tersebut dengan mengeklik tautan ini .
Metode perlindungan dari Google Dorking
Rekomendasi kunci
Google Dorking, seperti alat sumber terbuka lainnya, memiliki tekniknya sendiri untuk melindungi dan mencegah penyusup mengumpulkan informasi rahasia. Rekomendasi lima protokol berikut harus diikuti oleh administrator dari semua platform web dan server untuk menghindari ancaman dari "Google Dorking":
- Pembaruan sistematis sistem operasi, layanan, dan aplikasi.
- Implementasi dan pemeliharaan sistem anti-hacker.
- Kesadaran tentang robot Google dan berbagai prosedur mesin pencari, dan bagaimana memvalidasi proses tersebut.
- Menghapus konten sensitif dari sumber publik.
- Memisahkan konten publik, konten pribadi dan memblokir akses ke konten untuk pengguna publik.
Konfigurasi file .htaccess dan robots.txt
Pada dasarnya, semua kerentanan dan ancaman yang terkait dengan "Dorking" dihasilkan karena kecerobohan atau kelalaian pengguna berbagai program, server, atau perangkat web lainnya. Oleh karena itu, aturan perlindungan diri dan perlindungan data tidak menimbulkan kesulitan atau komplikasi.
Untuk mendekati pencegahan pengindeksan dari mesin telusur mana pun, Anda harus memperhatikan dua file konfigurasi utama sumber daya jaringan apa pun: ".htaccess" dan "robots.txt". Yang pertama melindungi jalur dan direktori yang ditentukan dengan kata sandi. Yang kedua mengecualikan direktori dari pengindeksan oleh mesin pencari.
Jika sumber daya Anda sendiri berisi jenis data atau direktori tertentu yang tidak boleh diindeks oleh Google, pertama-tama Anda harus mengonfigurasi akses ke folder melalui sandi. Pada contoh di bawah ini, Anda dapat melihat dengan jelas bagaimana dan apa sebenarnya yang harus ditulis di file ".htaccess" yang terletak di direktori root situs web mana pun.
Pertama, tambahkan beberapa baris seperti yang ditunjukkan di bawah ini:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName "Secure Document"
AuthType Basic
memerlukan nama
pengguna pengguna1 membutuhkan nama pengguna2
membutuhkan nama pengguna3
Di baris AuthUserFile, tentukan jalur ke lokasi file .htaccess, yang terletak di direktori Anda. Dan di tiga baris terakhir, Anda perlu menentukan nama pengguna yang sesuai untuk akses yang akan diberikan. Kemudian Anda perlu membuat ".htpasswd" di folder yang sama dengan ".htaccess" dan menjalankan perintah berikut:
htpasswd -c .htpasswd username1
Masukkan kata sandi untuk username1 dua kali dan setelah itu, file yang benar-benar bersih ".htpasswd" akan dibuat di direktori saat ini dan akan berisi versi terenkripsi dari kata sandi.
Jika ada beberapa pengguna, Anda harus menetapkan kata sandi untuk masing-masing pengguna. Untuk menambahkan pengguna tambahan, Anda tidak perlu membuat file baru, Anda cukup menambahkannya ke file yang ada tanpa menggunakan opsi -c menggunakan perintah ini:
htpasswd .htpasswd namapengguna2
Dalam kasus lain, disarankan untuk menyiapkan file robots.txt, yang bertanggung jawab untuk mengindeks halaman dari sumber daya web apa pun. Ini berfungsi sebagai panduan untuk setiap mesin pencari yang menautkan ke alamat halaman tertentu. Dan sebelum langsung ke sumber yang Anda cari, robots.txt akan memblokir permintaan tersebut atau melewatinya.
File itu sendiri terletak di direktori root dari platform web mana pun yang berjalan di Internet. Konfigurasi dilakukan hanya dengan mengubah dua parameter utama: "User-agent" dan "Disallow". Yang pertama memilih dan menandai semua atau beberapa mesin pencari tertentu. Sedangkan yang kedua mencatat apa yang sebenarnya perlu diblokir (file, direktori, file dengan ekstensi tertentu, dll.). Berikut adalah beberapa contoh: direktori, file, dan pengecualian mesin telusur tertentu yang dikecualikan dari proses pengindeksan.
Agen-pengguna: *
Disallow: / cgi-bin /
User-agent: *
Disallow: /~joe/junk.html
User-agent: Bing
Disallow: /
Menggunakan tag meta
Selain itu, pembatasan untuk spider web dapat diterapkan di halaman web individual. Mereka dapat ditemukan di situs web, blog, dan halaman konfigurasi biasa. Dalam tajuk HTML, mereka harus disertai dengan salah satu frasa berikut:
<meta name = "Robots" content = "none" \>
<meta name = "Robots" content = "noindex, nofollow" \>
Saat Anda menambahkan entri seperti itu di header halaman, robot Google tidak akan mengindeks halaman utama atau kedua. String ini dapat dimasukkan pada halaman yang tidak boleh diindeks. Namun, keputusan ini didasarkan pada kesepakatan bersama antara mesin telusur dan pengguna itu sendiri. Meskipun Google dan spider web lainnya mematuhi batasan yang disebutkan di atas, ada robot web tertentu yang "memburu" frasa tersebut untuk mengambil data yang awalnya dikonfigurasi tanpa pengindeksan.
Dari opsi lanjutan untuk keamanan pengindeksan, Anda dapat menggunakan sistem CAPTCHA. Ini adalah tes komputer yang memungkinkan hanya manusia untuk mengakses konten halaman, bukan bot otomatis. Namun, opsi ini memiliki sedikit kekurangan. Ini tidak terlalu ramah pengguna untuk pengguna itu sendiri.
Teknik pertahanan sederhana lainnya dari Google Dorks dapat berupa, misalnya, menyandikan karakter dalam file administratif dengan ASCII, sehingga menyulitkan penggunaan Google Dorking.
Praktek pentesting
Praktik pentesting adalah tes untuk mengidentifikasi kerentanan di jaringan dan di platform web. Keduanya penting dengan caranya sendiri, karena pengujian semacam itu secara unik menentukan tingkat kerentanan halaman web atau server, termasuk Google Dorking. Ada alat pentesting khusus yang dapat ditemukan di Internet. Salah satunya adalah Site Digger, sebuah situs yang memungkinkan Anda untuk secara otomatis memeriksa database Google Hacking pada halaman web mana pun yang dipilih. Selain itu, ada juga alat bantu seperti pemindai Wikto, SUCURI, dan berbagai pemindai online lainnya. Mereka bekerja dengan cara yang sama.
Ada alat yang lebih canggih yang meniru lingkungan halaman web, bersama dengan bug dan kerentanan, untuk memikat penyerang dan kemudian mengambil informasi sensitif tentangnya, seperti Google Hack Honeypot. Pengguna standar yang memiliki sedikit pengetahuan dan pengalaman yang tidak memadai dalam melindungi terhadap Google Dorking harus terlebih dahulu memeriksa sumber daya jaringan mereka untuk mengidentifikasi kerentanan Google Dorking dan memeriksa data sensitif apa yang tersedia untuk umum. Sebaiknya periksa basis data ini secara teratur, hasibeenpwned.com dan dehashed.com , untuk melihat apakah keamanan akun online Anda telah diganggu dan dipublikasikan.
https://haveibeenpwned.com/ mengacu pada halaman web yang kurang aman di mana data akun (alamat email, login, kata sandi, dan data lainnya) dikumpulkan. Basis data saat ini berisi lebih dari 5 miliar akun. Alat yang lebih canggih tersedia di https://dehashed.com , yang memungkinkan Anda mencari informasi berdasarkan nama pengguna, alamat email, kata sandi dan hashnya, alamat IP, nama, dan nomor telepon. Selain itu, akun yang bocor dapat dibeli secara online. Biaya akses satu hari hanya $ 2.
Kesimpulan
Google Dorking merupakan bagian integral dari pengumpulan informasi rahasia dan proses analisisnya. Ini dapat dianggap sebagai salah satu alat OSINT paling root dan utama. Operator Google Dorking membantu baik dalam menguji server mereka sendiri dan dalam menemukan semua kemungkinan informasi tentang calon korban. Ini memang contoh yang sangat mencolok dari penggunaan mesin pencari yang benar untuk tujuan mengeksplorasi informasi tertentu. Namun, apakah niat untuk menggunakan teknologi ini baik (memeriksa kerentanan sumber daya Internet mereka sendiri) atau buruk (mencari dan mengumpulkan informasi dari berbagai sumber dan menggunakannya untuk tujuan ilegal), tetap hanya pengguna yang memutuskan.
Metode alternatif dan alat otomatisasi memberikan lebih banyak peluang dan kenyamanan untuk menganalisis sumber daya web. Beberapa di antaranya, seperti BinGoo, memperluas pencarian terindeks reguler di Bing dan menganalisis semua informasi yang diterima melalui alat tambahan (SqlMap, Fimap). Mereka, pada gilirannya, menyajikan informasi yang lebih akurat dan spesifik tentang keamanan sumber daya web yang dipilih.
Pada saat yang sama, penting untuk mengetahui dan mengingat cara mengamankan dan mencegah platform online Anda diindeks di tempat yang tidak semestinya. Dan juga mematuhi ketentuan dasar yang disediakan untuk setiap administrator web. Bagaimanapun, ketidaktahuan dan ketidaksadaran bahwa, karena kesalahan mereka sendiri, orang lain mendapatkan informasi Anda, bukan berarti semuanya bisa dikembalikan seperti semula.