
Menurut sebuah lelucon terkenal, semua memoar di toko buku harus ditempatkan di bagian "Fiksi Ilmiah". Tapi dalam kasus saya, ini benar! Dahulu kala,
Kepala Berbicara 3D - Ini adalah lidah Max Planck yang menjulur keluar dan patung perunggu mengedipkan mata; monyet yang menyalin ekspresi wajah Anda secara real time; ini adalah model 3D dari kepala wakil presiden Intel yang cukup dikenal, dibuat sepenuhnya otomatis dari video dengan partisipasinya, dan banyak lagi ... Tapi yang pertama yang pertama.
Video sintetis: 3D Talking Heads yang kompatibel dengan MPEG-4 adalah nama lengkap dari proyek yang dilaksanakan di Pusat Penelitian dan Pengembangan Intel di Nizhny Novgorod pada tahun 2000-2003. Pengembangannya adalah seperangkat tiga teknologi utama yang dapat digunakan secara bersama-sama dan secara terpisah dalam banyak aplikasi yang berkaitan dengan pembuatan dan animasi karakter berbicara tiga dimensi sintetis.
- Pengenalan otomatis dan pelacakan ekspresi wajah dan gerakan kepala manusia dalam urutan video. Pada saat yang sama, tidak hanya sudut rotasi dan kemiringan kepala di semua bidang yang dinilai, tetapi juga kontur eksternal dan internal bibir dan gigi selama percakapan, posisi alis, tingkat cakupan mata, dan bahkan arah pandangan.
- Animasi otomatis dalam waktu nyata dari model kepala tiga dimensi yang hampir sewenang-wenang sesuai dengan parameter animasi yang diperoleh menggunakan algoritma pengenalan dan pelacakan dari titik pertama serta dari sumber lain.
- Pembuatan otomatis model 3D fotorealistik kepala orang tertentu menggunakan dua foto prototipe (tampilan depan dan samping), atau urutan video di mana seseorang menoleh dari satu bahu ke bahu lainnya.
Dan bonus lainnya - teknologi, atau lebih tepatnya, beberapa trik rendering realistis dari "kepala bicara" secara real time, dengan mempertimbangkan keterbatasan kinerja perangkat keras dan kemampuan perangkat lunak yang ada di awal tahun 2000-an.
Dan hubungan antara tiga setengah poin ini, serta tautan ke Intel, ada empat huruf dan satu angka: MPEG-4.
MPEG-4
Hanya sedikit orang yang tahu bahwa standar MPEG-4 yang muncul pada tahun 1998, selain mengkodekan streaming video dan audio biasa, menyediakan informasi pengkodean tentang objek sintetis dan animasinya - yang disebut video sintetis. Salah satu objek tersebut adalah wajah manusia, lebih tepatnya, kepala yang didefinisikan sebagai permukaan triangulasi - jaring dalam ruang 3D. MPEG-4 mendefinisikan 84 titik khusus pada wajah seseorang - Titik Fitur (FP): sudut dan titik tengah bibir, mata, alis, ujung hidung, dll.
Parameter Animasi Wajah (FAP) diterapkan pada titik-titik khusus ini (atau ke seluruh model secara keseluruhan dalam kasus belokan dan kemiringan), yang menjelaskan perubahan posisi dan ekspresi wajah dibandingkan dengan keadaan netral.
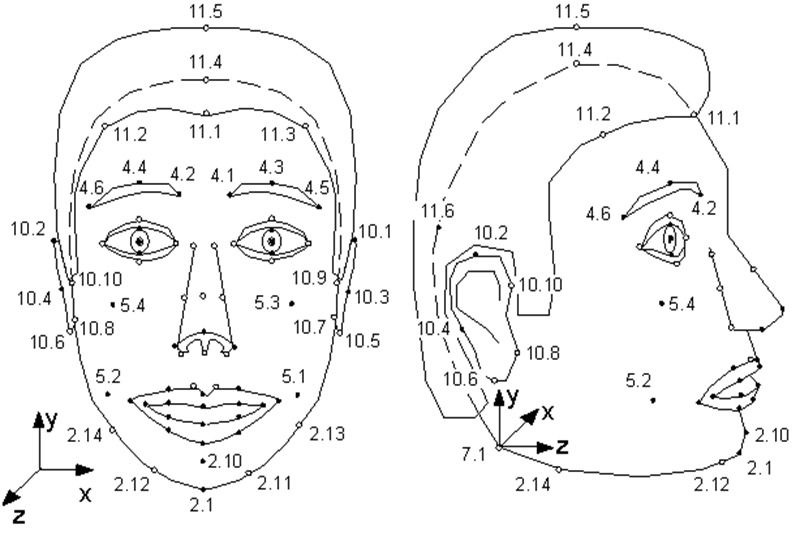
Ilustrasi dari spesifikasi MPEG-4. Titik-titik tunggal model. Seperti yang Anda lihat, model itu bisa mengendus dan menggoyangkan telinganya.
Artinya, deskripsi setiap bingkai video sintetis yang menunjukkan karakter berbicara tampak seperti sekumpulan kecil parameter yang harus digunakan dekoder MPEG-4 untuk menghidupkan model.
Model yang mana? MPEG-4 memiliki dua opsi. Entah model dibuat oleh encoder dan dikirim ke decoder satu kali di awal urutan, atau decoder memiliki model miliknya sendiri, yang digunakan dalam animasi.
Pada saat yang sama, satu-satunya persyaratan MPEG-4 untuk model: penyimpanan di VRML-format dan adanya poin khusus. Artinya, model dapat berfungsi sebagai salinan fotorealistik dari seseorang yang FAPnya digunakan untuk animasi, serta model orang lain, dan bahkan ketel berbicara - yang utama adalah bahwa ia, selain hidung, memiliki mulut dan mata.

Salah satu model yang kompatibel dengan MPEG-4 adalah yang paling tersenyum.
Selain "wajah" objek utama, MPEG-4 mendeskripsikan objek independen "rahang atas", "rahang bawah", "lidah", "mata", di mana titik-titik khusus juga ditetapkan. Namun jika beberapa model tidak memiliki objek ini, FAP yang sesuai tidak akan digunakan oleh decoder.

- Model, model, mengapa kamu memiliki mata dan gigi yang besar? - Untuk menghidupkan diri sendiri dengan lebih baik!
Dari mana asal model animasi yang dipersonalisasi? Bagaimana cara mendapatkan FAP? Dan terakhir, bagaimana Anda mengimplementasikan animasi dan rendering yang realistis berdasarkan FAP ini? MPEG-4 tidak memberikan jawaban apa pun untuk semua pertanyaan ini - seperti standar kompresi video apa pun yang tidak menjelaskan apa pun tentang proses pengambilan gambar dan konten film yang dikodekannya.
Seberapa jauh kemajuannya? Sampai keajaiban yang belum pernah terjadi sebelumnya!
Tentu saja, baik model maupun animasinya dapat dibuat secara manual oleh seniman profesional, menghabiskan waktu puluhan jam dan menerima puluhan ratus dolar. Tetapi ini secara signifikan mempersempit ruang lingkup teknologi, membuatnya tidak dapat diterapkan pada skala industri. Dan ada banyak kegunaan potensial dari teknologi ini, yang sebenarnya memampatkan bingkai video resolusi tinggi menjadi beberapa byte (oh, sayang sekali tidak ada video). Pertama-tama, jaringan - game, pendidikan dan komunikasi (konferensi video) menggunakan karakter sintetis.
Aplikasi semacam itu sangat relevan 20 tahun yang lalu, ketika Internet masih diakses menggunakan modem, dan Internet tak terbatas gigabit tampak seperti semacam teleportasi. Namun, seperti yang ditunjukkan kehidupan, pada tahun 2020, bandwidth saluran Internet dalam banyak kasus masih menjadi masalah. Dan bahkan jika tidak ada masalah seperti itu, katakanlah, kita berbicara tentang penggunaan lokal, karakter sintetis mampu melakukan banyak hal. Misalnya, "membangkitkan" aktor terkenal abad terakhir dalam sebuah film, atau memberikan kesempatan untuk melihat ke mata asisten suara yang sekarang populer dan masih tanpa tubuh. Tetapi pertama-tama, proses transisi dari video nyata dari orang yang sedang berbicara ke video sintetis harus menjadi otomatis, atau setidaknya, dilakukan dengan partisipasi manusia yang minimal.
Inilah yang diterapkan di Nizhny Novgorod Intel. Ide tersebut muncul pertama kali sebagai bagian dari implementasi MPEG Processing Library, dikembangkan pada satu waktu oleh Intel, dan kemudian tumbuh tidak hanya menjadi spin-off yang lengkap, tetapi menjadi blockbuster yang sangat fantastis.
Selain itu, sepenuhnya "buatan Rusia" - proyek ini tampaknya menjadi satu-satunya untuk seluruh keberadaan Intel Rusia, tidak ada kurator di Intel USA. Selama kunjungannya ke Nizhny Novgorod, Justin Ratner (kepala departemen penelitian Intel Labs) menyukai ide tersebut, dan dia memberikan lampu hijau untuk

Synthetic Valery Fedorovich Kuryakin, produser, sutradara, penulis naskah, dan di beberapa tempat menjadi pemeran pengganti proyek - pada waktu itu adalah kepala grup pengembangan Intel.
Pertama, kombinasi dari berbagai teknologi yang berbeda dalam satu proyek kecil, di mana hanya tiga hingga tujuh orang yang bekerja pada saat yang sama, sangatlah fantastis. Pada tahun-tahun itu, setidaknya ada selusin perusahaan di dunia yang terlibat dalam pengenalan dan pelacakan wajah, serta pembuatan dan animasi "kepala bicara". Semuanya, tentu saja, memiliki pencapaian di beberapa bidang: beberapa memiliki kualitas model yang sangat baik, beberapa menunjukkan animasi yang sangat realistis, beberapa berhasil dalam pengenalan dan pelacakan. Tetapi tidak ada satu perusahaan pun yang mampu menawarkan seluruh rangkaian teknologi yang memungkinkan Anda membuat video sintetis sepenuhnya secara otomatis di mana sebuah model, yang sangat mirip dengan prototipe, menyalin dengan baik ekspresi wajah dan gerakannya.
Proyek Intel 3D Talking Heads adalah yang pertama dan pada saat itu merupakan satu-satunya implementasi siklus penuh komunikasi video berdasarkan semua elemen profil sintetis MPEG-4.

Konveyor proyek untuk produksi klon sintetis model 2003.
Kedua, kombinasi perangkat keras yang ada pada saat itu dan solusi teknologi yang diterapkan dalam proyek tersebut, serta rencana penggunaannya, sangat fantastis. Jadi, di awal proyek, saya memiliki Nokia 3310 di saku saya, ada Pentium III-500MHz di desktop saya, dan algoritme yang sangat penting untuk kinerja untuk pekerjaan waktu nyata telah diuji pada server Pentium 4-1.7GHz dengan RAM 128 Mb.
Pada saat yang sama, kami berharap agar model kami segera berfungsi di perangkat seluler, dan kualitasnya tidak lebih buruk dari para pahlawan film animasi komputer fotorealistik " Final Fantasy " yang dirilis pada waktu itu (2001) .

Biaya sebesar $ 137 juta untuk film yang dibuat di render farm dari ~ 1000 komputer Pentium III. Poster dari www.thefinalfantasy.com
Tapi mari kita lihat apa yang terjadi dengan kita.
Pengenalan wajah dan pelacakan, akuisisi FAP.
Teknologi ini dihadirkan dalam dua versi:
- mode real-time (25 frame per detik pada prosesor Pentium 4-1.7GHz yang telah disebutkan), ketika seseorang dilacak langsung di depan kamera video yang terhubung ke komputer;
- ( 1 ), .
Pada saat yang sama, dinamika perubahan posisi / keadaan wajah manusia dipantau secara real time - kami dapat memperkirakan secara kira-kira sudut rotasi dan kemiringan kepala di semua bidang, perkiraan derajat pembukaan dan peregangan mulut dan pengangkatan alis, serta mengenali kedipan. Untuk beberapa aplikasi, perkiraan kasar seperti itu sudah cukup, tetapi jika Anda perlu melacak ekspresi wajah seseorang secara akurat, maka diperlukan algoritma yang lebih kompleks, yang berarti lebih lambat.
Dalam mode offline, teknologi kami memungkinkan untuk menilai tidak hanya posisi kepala secara keseluruhan, tetapi secara akurat mengenali dan melacak kontur luar dan dalam dari bibir dan gigi selama percakapan, posisi alis, tingkat cakupan mata, dan bahkan perpindahan pupil - arah pandangan.
Untuk pengenalan dan pelacakan, kombinasi algoritme visi komputer yang terkenal digunakan, beberapa di antaranya telah diterapkan di pustaka OpenCV yang baru dirilis - misalnya, Aliran Optik, serta metode asli kami sendiri berdasarkan pengetahuan apriori tentang bentuk objek yang sesuai. Secara khusus - pada versi perbaikan kami dari metode templat yang dapat dideformasi , di mana peserta proyek menerima paten .
Teknologi tersebut diimplementasikan dalam bentuk library fungsi yang menerima frame video dengan wajah manusia sebagai input dan output FAP yang sesuai.
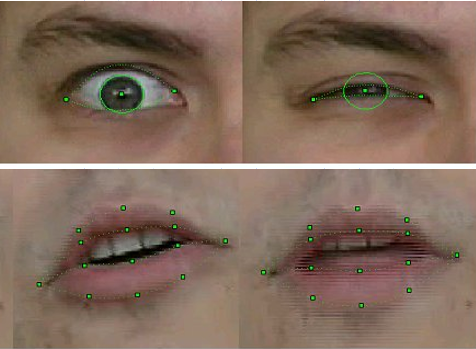
Kualitas pengenalan dan pelacakan sampel FP 2003
Tentu saja, teknologinya tidak sempurna. Pengenalan dan pelacakan gagal jika orang dalam bingkai memiliki kumis, kacamata, atau kerutan yang dalam. Tetapi selama tiga tahun bekerja, kualitasnya telah meningkat secara signifikan. Jika dalam versi pertama untuk model pengenalan gerakan saat merekam video harus menempelkan tanda khusus pada titik FP yang sesuai dari wajah - lingkaran kertas putih diperoleh dengan pukulan kantor, maka di akhir proyek tidak diperlukan hal semacam itu, tentu saja. Selain itu, kami berhasil melacak dengan mantap posisi gigi dan arah pandangan - dan ini sesuai dengan resolusi video dari webcam saat itu, di mana detail seperti itu hampir tidak terlihat!

Ini bukan cacar air, tapi cuplikan dari "masa kecil" teknologi pengenalan. Intel Principle Engineer, dan pada saat itu - karyawan Intel pemula Alexander Bovyrin mengajarkan model sintetis untuk membaca puisi
Animasi
Seperti yang telah dikatakan berkali-kali, animasi model dalam MPEG-4 sepenuhnya ditentukan oleh FAP. Dan semuanya akan sederhana, jika bukan karena beberapa masalah.
Pertama, fakta bahwa FAP dari sekuens video diekstraksi dalam 2D, dan modelnya 3D, dan diperlukan untuk menyelesaikan koordinat ketiga. Artinya, senyum ramah di profil (dan pengguna harus dapat melihat profil ini, jika tidak, ada sedikit kesan dalam 3D) tidak boleh berubah menjadi seringai yang tidak menyenangkan.
Kedua, seperti yang juga dikatakan, FAP menggambarkan pergerakan titik tunggal, yang jumlahnya sekitar delapan puluh dalam model, sementara setidaknya model yang agak realistis secara keseluruhan terdiri dari beberapa ribu simpul (dalam kasus kami, dari empat menjadi delapan ribu), dan algoritma diperlukan untuk menghitung perpindahan semua titik lain dalam model berdasarkan perpindahan FP.
Artinya, jelas bahwa ketika kepala diputar pada sudut yang sama, semua titik akan berputar, tetapi ketika tersenyum, bahkan jika itu sampai ke telinga, "kemarahan" dari pergeseran sudut mulut secara bertahap akan menghilang dan menggerakkan pipi, tetapi tidak ke telinga. Selain itu, ini harus terjadi secara otomatis dan realistis untuk model apa pun dengan lebar mulut dan geometri jaring di sekitarnya. Untuk mengatasi masalah ini, algoritma animasi dibuat dalam proyek ini. Mereka didasarkan pada model pseudomuskuler, yang secara sederhana menggambarkan otot-otot yang mengontrol ekspresi wajah.
Dan kemudian, untuk setiap model dan setiap FAP, "zona pengaruh" secara otomatis ditentukan sebelumnya - simpul yang terlibat dalam tindakan terkait, yang pergerakannya dihitung dengan mempertimbangkan anatomi dan geometri - menjaga kelancaran dan konektivitas permukaan. Artinya, animasi terdiri dari dua bagian - pendahuluan, dilakukan secara offline, di mana koefisien tertentu untuk simpul mesh dibuat dan dimasukkan ke dalam tabel, dan online, di mana, dengan mempertimbangkan data dari tabel, animasi real-time diterapkan ke model.

Tersenyum bukanlah hal yang mudah untuk model 3D dan pembuatnya
Pembuatan model 3D orang tertentu.
Dalam kasus umum, tugas merekonstruksi objek tiga dimensi dari gambar dua dimensinya sangat sulit. Artinya, algoritma untuk solusinya sudah lama dikenal manusia, namun dalam prakteknya karena banyak faktor, hasil yang didapat jauh dari yang diinginkan. Dan ini terutama terlihat dalam kasus rekonstruksi bentuk wajah seseorang - di sini Anda dapat mengingat model pertama kami dengan mata berbentuk delapan (bayangan dari bulu mata di foto asli tidak berhasil) atau sedikit bercabang di hidung (alasannya tidak dapat dipulihkan setelah bertahun-tahun).
Tetapi dalam kasus MPEG-4 talking head, tugasnya sangat disederhanakan, karena rangkaian fitur wajah manusia (hidung, mulut, mata, dll.) Adalah sama untuk semua orang, dan perbedaan eksternal yang membedakan kita semua (dan program visi komputer) orang dari satu sama lain "geometris" - ukuran / proporsi dan lokasi fitur ini dan "bertekstur" - warna dan relief. Oleh karena itu, salah satu profil video MPEG-4 sintetis, kalibrasi, yang diimplementasikan dalam proyek, mengasumsikan bahwa decoder memiliki model umum "orang abstrak" yang dipersonalisasi untuk orang tertentu menggunakan urutan foto atau video.
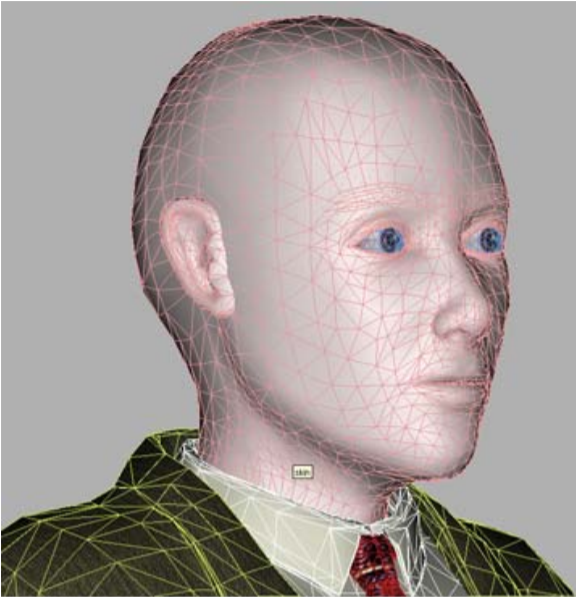
Kami "manusia bulat dalam ruang hampa" - model untuk personalisasi
Artinya, deformasi global dan lokal dari mesh 3D terjadi untuk menyesuaikan proporsi fitur wajah prototipe yang disorot dalam foto / video, setelah itu "tekstur" prototipe diterapkan ke model - yaitu, tekstur yang dibuat dari gambar masukan yang sama. Hasilnya adalah model sintetis. Ini dilakukan sekali untuk setiap model, tentu saja secara offline, dan tentu saja, tidak begitu mudah.
Pertama-tama, diperlukan registrasi atau perbaikan gambar input - membawanya ke sistem koordinat tunggal yang bertepatan dengan sistem koordinat model 3D. Selanjutnya, perlu untuk mendeteksi titik-titik khusus pada gambar masukan, dan, berdasarkan lokasinya, mendeformasi model 3D, misalnya, menggunakan metode fungsi basis radialdan kemudian, menggunakan algoritme penggabungan panorama , buat tekstur dari dua atau lebih gambar masukan, yaitu, "gabungkan" dalam proporsi yang benar untuk mendapatkan informasi visual yang maksimal, serta mengimbangi perbedaan pencahayaan dan nada, yang selalu ada bahkan dalam foto yang diambil dengan pengaturan kamera yang sama (yang tidak selalu terjadi), dan sangat terlihat saat menggabungkan foto-foto ini.

Ini bukan gambar diam dari film horor, tetapi tekstur model 3D oleh Pat Gelsinger , dibuat dengan izinnya ketika proyek itu didemonstrasikan di Forum Pengembang Intel pada tahun 2003.
Versi awal teknologi untuk mempersonalisasi model berdasarkan dua foto diterapkan oleh peserta proyek itu sendiri di Intel. Tetapi setelah mencapai tingkat kualitas tertentu dan menyadari keterbatasan kemampuan mereka, diputuskan untuk mengalihkan bagian dari pekerjaan ini ke kelompok peneliti Universitas Negeri Moskow, yang memiliki pengalaman di bidang ini. Hasil kerja peneliti dari Moscow State University di bawah kepemimpinan Denis Ivanov adalah aplikasi "Head Calibration Environment", yang melakukan semua operasi di atas untuk membuat model pribadi seseorang dari fotonya di wajah dan profil penuh.
Satu-satunya poin halus adalah bahwa aplikasi tidak terintegrasi dengan unit pengenalan wajah yang dijelaskan di atas, yang dikembangkan dalam proyek kami, jadi poin khusus dalam foto yang diperlukan agar algoritme berfungsi harus ditandai secara manual. Tentu saja, tidak semuanya 84, tetapi hanya yang utama, dan mengingat bahwa aplikasi memiliki antarmuka pengguna yang sesuai, operasi ini hanya membutuhkan beberapa detik.
Juga, versi rekonstruksi model yang sepenuhnya otomatis dari urutan video diterapkan, di mana seseorang menoleh dari satu bahu ke bahu lainnya. Namun, seperti yang Anda duga, kualitas tekstur yang diekstrak dari video secara signifikan lebih buruk daripada tekstur yang dibuat dari foto kamera digital pada masa itu dengan resolusi ~ 4K (3-5 megapiksel), yang berarti model yang dihasilkan terlihat kurang menarik. Oleh karena itu, ada juga versi perantara yang menggunakan beberapa foto dengan sudut rotasi kepala yang berbeda.

Baris atas adalah orang maya, baris bawah adalah sungguhan.
Seberapa baik hasil yang dicapai? Kualitas model yang dihasilkan harus dinilai bukan dalam statika, tetapi langsung pada video sintetis berdasarkan kemiripannya dengan video aslinya. Tetapi istilah "mirip dan tidak mirip" tidak matematis, mereka bergantung pada persepsi orang tertentu, dan sulit untuk memahami bagaimana model sintetis dan animasinya berbeda dari prototipe. Beberapa orang menyukainya, beberapa tidak. Namun hasil kerja selama tiga tahun ini adalah ketika mendemonstrasikan hasil di berbagai pameran, penonton harus menjelaskan di jendela mana video asli berada di depan mereka, dan di mana - yang sintetis.
Visualisasi.
Untuk mendemonstrasikan hasil dari semua teknologi di atas, pemutar video sintetis MPEG-4 khusus telah dibuat. Pemain menerima sebagai masukan file VRML dengan model, aliran (atau file) dengan FAP, serta aliran (file) dengan video dan audio nyata untuk tampilan yang disinkronkan dengan video sintetis dengan dukungan untuk mode "gambar dalam gambar". Saat mendemonstrasikan video sintetis, pengguna diberi kesempatan untuk memperbesar model, serta melihatnya dari semua sisi, cukup dengan memutar mouse pada sudut yang berubah-ubah.

Meskipun pemain itu ditulis untuk Windows, tetapi dengan mempertimbangkan kemungkinan porting di masa depan ke OS lain, termasuk yang seluler. Oleh karena itu, OpenGL 1.1 "klasik" tanpa ekstensi apa pun dipilih sebagai pustaka 3D.
Pada saat yang sama, pemain tidak hanya menunjukkan modelnya, tetapi juga mencoba memperbaikinya, tetapi tidak memperbaikinya, seperti yang biasa terjadi pada model foto, tetapi, sebaliknya, membuatnya serealistis mungkin. Yaitu, tetap dalam kerangka pencahayaan Phong yang paling sederhana dan tidak memiliki peneduh, tetapi memiliki persyaratan kinerja yang ketat, unit rendering pemain secara otomatis membuat model sintetis: meniru kerutan, bulu mata, yang mampu menyempitkan dan melebarkan pupil secara realistis; letakkan kacamata dengan ukuran yang sesuai pada model; dan juga menggunakan ray tracing yang paling sederhana, dia menghitung pencahayaan (bayangan) lidah dan gigi saat berbicara.
Tentu saja, sekarang metode seperti itu sudah tidak relevan lagi, tetapi mengingatnya cukup menarik. Jadi, untuk sintesis keriput tiruan, yaitu lengkungan kecil pada relief kulit di wajah, terlihat selama kontraksi otot wajah, ukuran segitiga model mesh yang relatif besar tidak memungkinkan pembuatan lipatan yang nyata. Oleh karena itu, semacam teknologi pemetaan bergelombang diterapkan - pemetaan normal. Alih-alih mengubah geometri model, ada perubahan arah normals ke permukaan di tempat yang tepat, dan ketergantungan komponen difus iluminasi di setiap titik pada normal menciptakan efek yang diinginkan.

Ini adalah realisme sintetis.
Tapi pemain itu tidak berhenti di situ. Untuk kenyamanan penggunaan teknologi dan mentransfernya ke dunia luar, perpustakaan objek Intel Facial Animation Library telah dibuat, yang berisi fungsi untuk animasi (transformasi 3D) dan visualisasi model, sehingga siapa pun yang ingin (dan memiliki sumber FAP) memanggil beberapa fungsi - "Buat Pemandangan", " CreateActor ”,“ Animate ”dapat menganimasikan dan menampilkan modelnya dalam aplikasinya.
Hasil
Apa yang diberikan partisipasi dalam proyek ini kepada saya secara pribadi? Tentu saja, kesempatan untuk berkolaborasi dengan orang-orang hebat pada teknologi yang menarik. Mereka membawa saya ke dalam proyek untuk pengetahuan saya tentang metode dan pustaka untuk merender model 3D dan mengoptimalkan kinerja untuk x86. Tapi, tentu saja, tidak mungkin membatasi diri pada 3D, jadi kami harus pergi ke dimensi lain. Untuk menulis pemain, itu perlu untuk menangani penguraian VRML (tidak ada perpustakaan yang siap pakai untuk tujuan ini), untuk menguasai pekerjaan asli dengan aliran di Windows, memastikan pekerjaan gabungan beberapa utas dengan sinkronisasi 25 kali per detik, tidak melupakan interaksi pengguna, dan bahkan untuk memikirkan dan mengimplementasikan antarmuka. Kemudian, daftar ini dilengkapi dengan partisipasi dalam peningkatan algoritma pelacakan wajah. Dan kebutuhan untuk terus mengintegrasikan dan menggabungkan komponen yang ditulis oleh anggota tim lain dengan pemain,dan juga mempresentasikan proyek ke dunia luar sangat meningkatkan keterampilan komunikasi dan koordinasi saya.
Apa yang diberikan oleh partisipasi Intel dalam proyek ini? Hasilnya, tim kami telah menciptakan produk yang dapat berfungsi sebagai pengujian dan demonstrasi yang baik atas kapabilitas produk dan platform Intel. Selain itu, baik perangkat keras - CPU dan GPU, dan perangkat lunak - kepala kami (baik nyata maupun sintetis) telah berkontribusi pada peningkatan pustaka OpenCV.
Selain itu, kami dapat dengan aman mengatakan bahwa proyek tersebut meninggalkan jejak yang terlihat dalam sejarah - sebagai hasil dari pekerjaannya, para pesertanya menulis artikel dan mempresentasikan laporan pada konferensi khusus tentang visi komputer dan grafik komputer, Rusia ( GraphiCon ) dan internasional.
Dan aplikasi demo 3D Talking Heads telah diperlihatkan oleh Intel di puluhan pameran dagang, forum, dan kongres di seluruh dunia.
Dalam waktu sela, teknologi sudah pasti banyak maju, sehingga lebih mudah untuk membuat dan menghidupkan karakter sintetis secara otomatis. Ada definisi kedalaman ruang Intel Real Sense , dan jaringan saraf berdasarkan data besar yang dipelajari cara menghasilkan gambar orang yang realistis, bahkan tidak ada.
Namun, meski demikian, perkembangan proyek 3D Talking Heads yang diposting di domain publik tersebut terus disaksikan hingga kini.
Lihatlah speaker MPEG-4 sintetis muda kami yang hampir berusia dua puluh tahun dan Anda: