pengantar
Arsitektur Jaringan Neural Konvolusional (CNN) RetinaNet terdiri dari 4 bagian utama, yang masing-masing memiliki tujuan sendiri:
a) Backbone - jaringan (dasar) utama yang digunakan untuk mengekstraksi fitur dari gambar input. Bagian dari jaringan ini adalah variabel dan dapat mencakup klasifikasi jaringan saraf seperti ResNet, VGG, EfficientNet, dan lainnya;
b) Fitur Pyramid Net (FPN) - jaringan saraf convolutional, dibangun dalam bentuk piramida, berfungsi untuk menggabungkan keunggulan peta fitur dari tingkat bawah dan atas jaringan, yang pertama memiliki resolusi tinggi, tetapi semantik rendah, kemampuan generalisasi; yang terakhir, sebaliknya;
c) Klasifikasi Subnet - subnet yang mengekstraksi informasi tentang kelas objek dari FPN, memecahkan masalah klasifikasi;
d) Regresi Subnet - subnet yang mengekstraksi informasi tentang koordinat objek dalam gambar dari FPN, menyelesaikan masalah regresi.
Dalam gbr. 1 menunjukkan arsitektur RetinaNet dengan jaringan saraf ResNet sebagai tulang punggung.
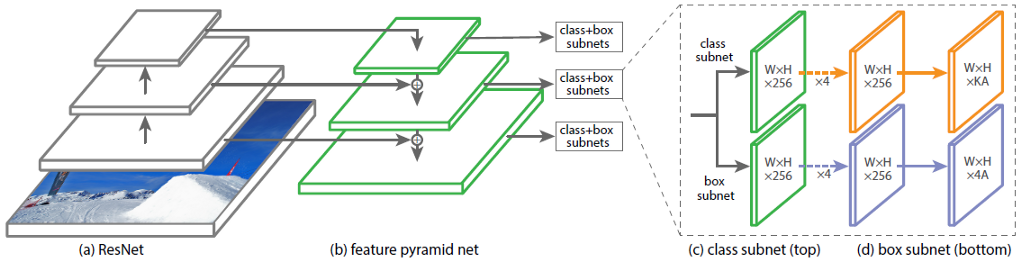
Gambar 1 - Arsitektur RetinaNet dengan tulang punggung ResNet.
Mari kita menganalisis secara terperinci setiap bagian RetinaNet yang ditunjukkan pada Gambar. 1.
Backbone adalah bagian dari jaringan RetinaNet
Menimbang bahwa bagian dari arsitektur RetinaNet yang menerima gambar sebagai input dan menyoroti fitur-fitur penting adalah variabel dan informasi yang diekstrak dari bagian ini akan diproses pada tahap selanjutnya, penting untuk memilih jaringan backbone yang sesuai untuk hasil terbaik.
Penelitian terbaru tentang optimasi CNN telah menyebabkan pengembangan model klasifikasi yang mengungguli semua arsitektur yang dikembangkan sebelumnya dengan tingkat akurasi terbaik pada dataset ImageNet sambil meningkatkan efisiensi sebesar 10 kali. Jaringan ini diberi nama EfficientNet-B (0-7). Indikator keluarga jaringan baru ditunjukkan pada Gambar. 2.
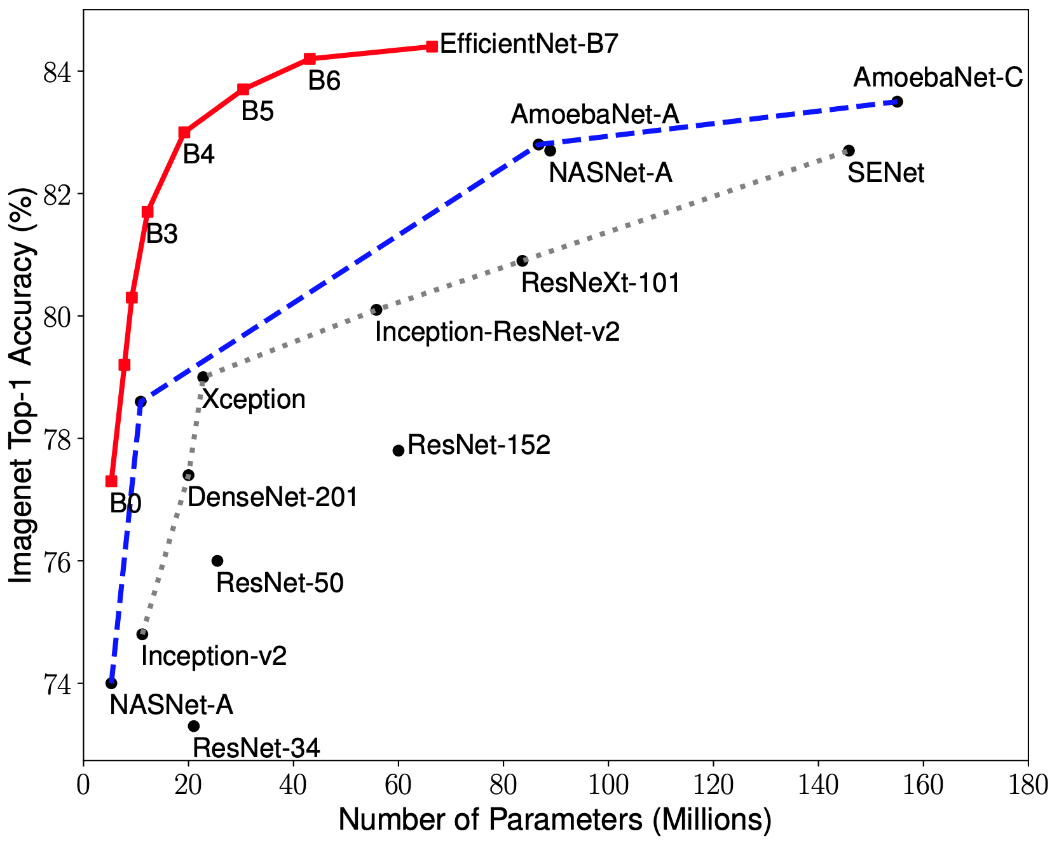
Gambar 2 - Grafik ketergantungan indikator akurasi tertinggi pada jumlah bobot jaringan untuk berbagai arsitektur
Piramida tanda
Jaringan Piramida Fitur terdiri dari tiga bagian utama: jalur bottom-up, jalur top-down, dan koneksi lateral.
Jalur ke atas adalah semacam "piramida" hierarkis - urutan lapisan konvolusional dengan dimensi yang menurun, dalam kasus kami - jaringan tulang punggung. Lapisan atas dari jaringan konvolusional memiliki makna yang lebih semantik, tetapi resolusi yang lebih rendah, dan yang lebih rendah, sebaliknya (Gbr. 3). Jalur bottom-up memiliki kerentanan dalam ekstraksi fitur - hilangnya informasi penting tentang suatu objek, misalnya, karena kebisingan objek kecil tetapi signifikan di latar belakang, karena pada akhir jaringan informasi sangat dikompresi dan digeneralisasi.
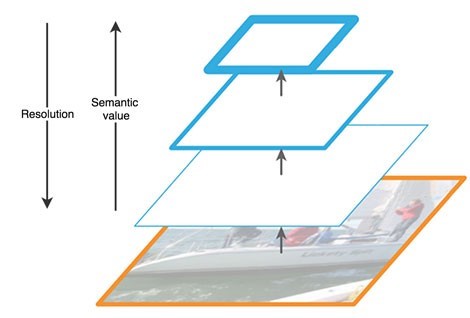
Gambar 3 - Fitur peta fitur di berbagai tingkat jaringan saraf
Jalur menurun juga merupakan "piramida". Peta fitur dari lapisan atas piramida ini memiliki ukuran peta fitur dari lapisan atas dari bawah ke atas piramida dan digandakan dengan metode tetangga terdekat (Gbr. 4) ke bawah.
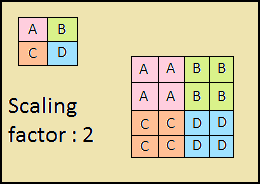
Gambar 4 - Meningkatkan resolusi gambar dengan metode tetangga terdekat
Dengan demikian, dalam jaringan top-down, setiap fitur peta dari lapisan atasnya ditingkatkan ke ukuran peta yang mendasarinya. Selain itu, koneksi sisi hadir dalam FPN, yang berarti bahwa peta fitur lapisan bawah-atas dan atas-bawah dari piramida ditambahkan elemen demi elemen, dan peta dari bawah-atas dilipat 1 * 1. Proses ini ditunjukkan secara skematis pada Gambar. 5.
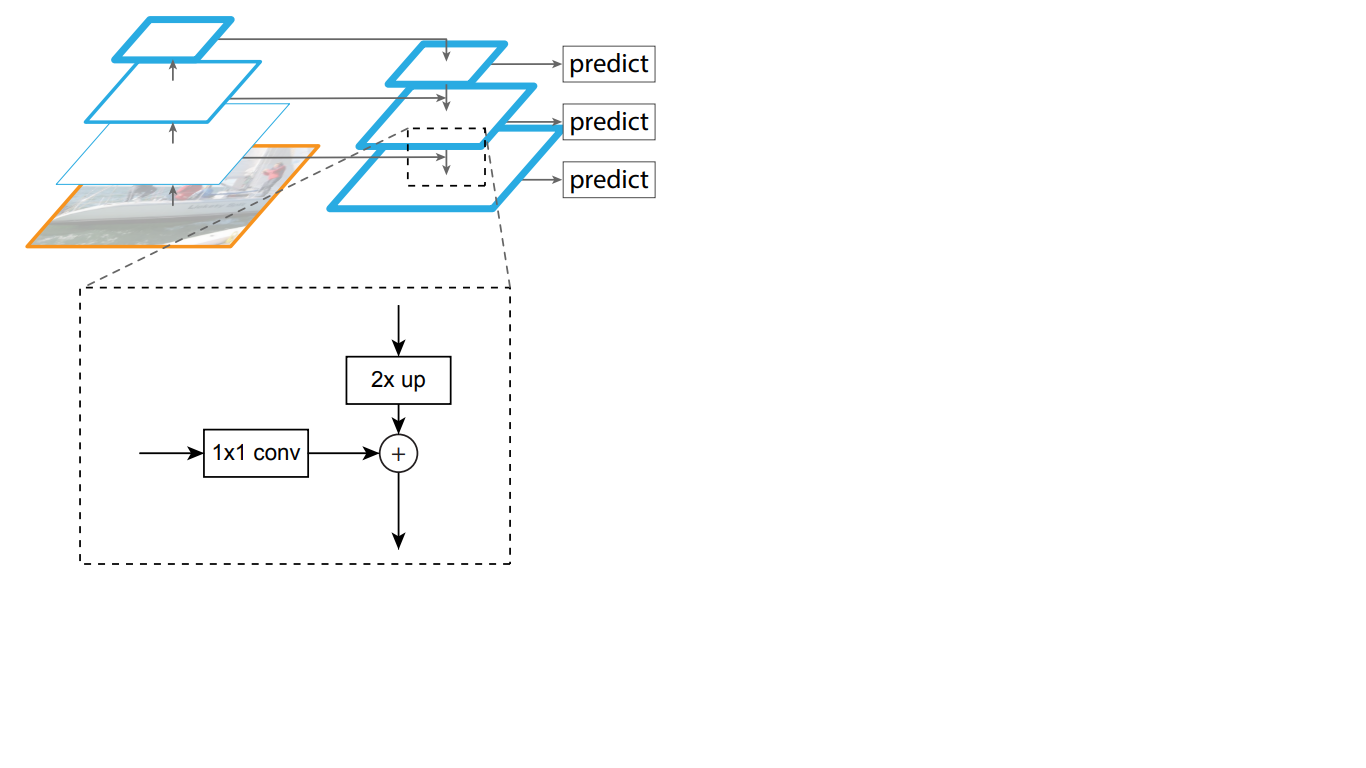
Gambar 5 - Struktur piramida tanda
Koneksi lateral menyelesaikan masalah pelemahan sinyal penting dalam proses melewati lapisan, menggabungkan informasi penting yang diterima secara semantik pada akhir piramida pertama dan informasi lebih rinci yang diperoleh sebelumnya di dalamnya.
Selanjutnya, setiap lapisan yang dihasilkan dalam piramida top-down diproses oleh dua subnet.
Subnet klasifikasi dan regresi
Bagian ketiga dari arsitektur RetinaNet adalah dua subnet: klasifikasi dan regresi (Gambar 6). Masing-masing dari subnet-subnet ini membentuk pada output sebuah respons tentang kelas objek dan lokasinya pada gambar. Mari kita perhatikan bagaimana masing-masing dari mereka bekerja.
Gambar 6 - Subnet RetinaNet
Perbedaan prinsip-prinsip blok yang dipertimbangkan (subnet) tidak berbeda hingga lapisan terakhir. Masing-masing terdiri dari 4 lapisan jaringan konvolusional. 256 peta fitur terbentuk di layer. Pada lapisan kelima, jumlah peta fitur berubah: subnet regresi memiliki 4 * fitur peta, subnet klasifikasi memiliki peta fitur K * A, di mana A adalah jumlah frame jangkar (deskripsi rinci tentang frame jangkar di subbagian berikutnya), K adalah jumlah kelas objek.
Pada layer terakhir, keenam, setiap peta fitur ditransformasikan menjadi satu set vektor. Model regresi pada output memiliki untuk masing-masing kotak anchor vektor 4 nilai yang menunjukkan offset kotak ground-kebenaran relatif terhadap kotak anchor. Model klasifikasi memiliki vektor satu-panas panjang K pada output untuk setiap kerangka jangkar, di mana indeks dengan nilai 1 sesuai dengan nomor kelas yang ditetapkan oleh jaringan saraf untuk objek tersebut.
Bingkai jangkar
Di bagian terakhir, istilah anchor frames digunakan. Anchor box adalah hyperparameter dari neural network-detectors, sebuah persegi panjang pembatas yang telah ditentukan sehubungan dengan dimana jaringan beroperasi.
Katakanlah jaringan memiliki peta fitur 3 * 3 pada output. Di RetinaNet, setiap sel memiliki 9 kotak jangkar, masing-masing dengan ukuran dan rasio aspek yang berbeda (Gambar 7). Selama pelatihan, jangkar frame dicocokkan dengan setiap frame target. Jika indikator IoU mereka memiliki nilai 0,5, maka kerangka jangkar ditetapkan sebagai target, jika nilainya kurang dari 0,4, maka dianggap sebagai latar belakang, dalam kasus lain kerangka jangkar akan diabaikan untuk pelatihan. Jaringan klasifikasi dilatih relatif terhadap penugasan (kelas objek atau latar belakang), jaringan regresi dilatih relatif terhadap koordinat kerangka jangkar (penting untuk dicatat bahwa kesalahan dihitung relatif terhadap kerangka jangkar, tetapi bukan kerangka target).
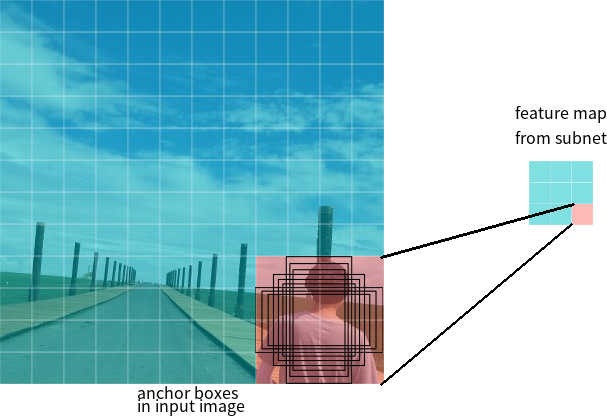
Gambar 7 - Jangkar bingkai untuk satu sel dari peta fitur dengan ukuran 3 * 3
Fungsi kerugian
Kerugian RetinaNet adalah komposit, mereka terdiri dari dua nilai: kesalahan regresi atau lokalisasi (dilambangkan sebagai Lloc di bawah) dan kesalahan klasifikasi (dilambangkan sebagai Lcls di bawah). Fungsi kerugian umum dapat ditulis sebagai:
Di mana λ adalah hiperparameter yang mengontrol keseimbangan antara dua kerugian.
Mari kita pertimbangkan secara lebih rinci perhitungan masing-masing kerugian.
Seperti dijelaskan sebelumnya, setiap frame target diberi jangkar. Mari kita tunjukkan pasangan ini sebagai (Ai, Gi) i = 1, ... N, di mana A mewakili jangkar, G adalah kerangka target, dan N adalah jumlah pasangan yang cocok.
Untuk setiap jangkar, jaringan regresi memprediksi 4 angka, yang dapat dilambangkan sebagai Pi = (Pix, Piy, Piw, Pih). Dua pasangan pertama mewakili perbedaan prediksi antara koordinat pusat-pusat jangkar Ai dan kerangka target Gi, dan dua pasangan terakhir mewakili perbedaan prediksi antara lebar dan tinggi mereka. Dengan demikian, untuk setiap kerangka target, Ti dihitung sebagai perbedaan antara kerangka jangkar dan target:
Di mana smoothL1 (x) didefinisikan oleh rumus di bawah ini:
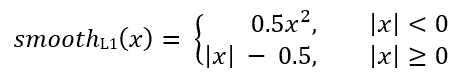
Hilangnya masalah klasifikasi klasifikasi RetinaNet dihitung menggunakan fungsi kehilangan fokus.
di mana K adalah jumlah kelas, yi adalah nilai target kelas, p adalah probabilitas memprediksi kelas ke-i, γ adalah parameter fokus, α adalah koefisien bias. Fitur ini adalah fitur lintas entropi tingkat lanjut. Perbedaannya terletak pada penambahan parameter γ∈ (0, + ∞), yang memecahkan masalah ketidakseimbangan kelas. Selama pelatihan, sebagian besar objek yang diproses oleh classifier adalah latar belakang, yang merupakan kelas terpisah. Oleh karena itu, masalah dapat muncul ketika jaringan saraf belajar untuk menentukan latar belakang yang lebih baik daripada objek lain. Penambahan parameter baru memecahkan masalah ini dengan mengurangi nilai kesalahan untuk objek yang mudah diklasifikasikan. Grafik fungsi fokus dan lintas entropi ditunjukkan pada Gambar. 8.
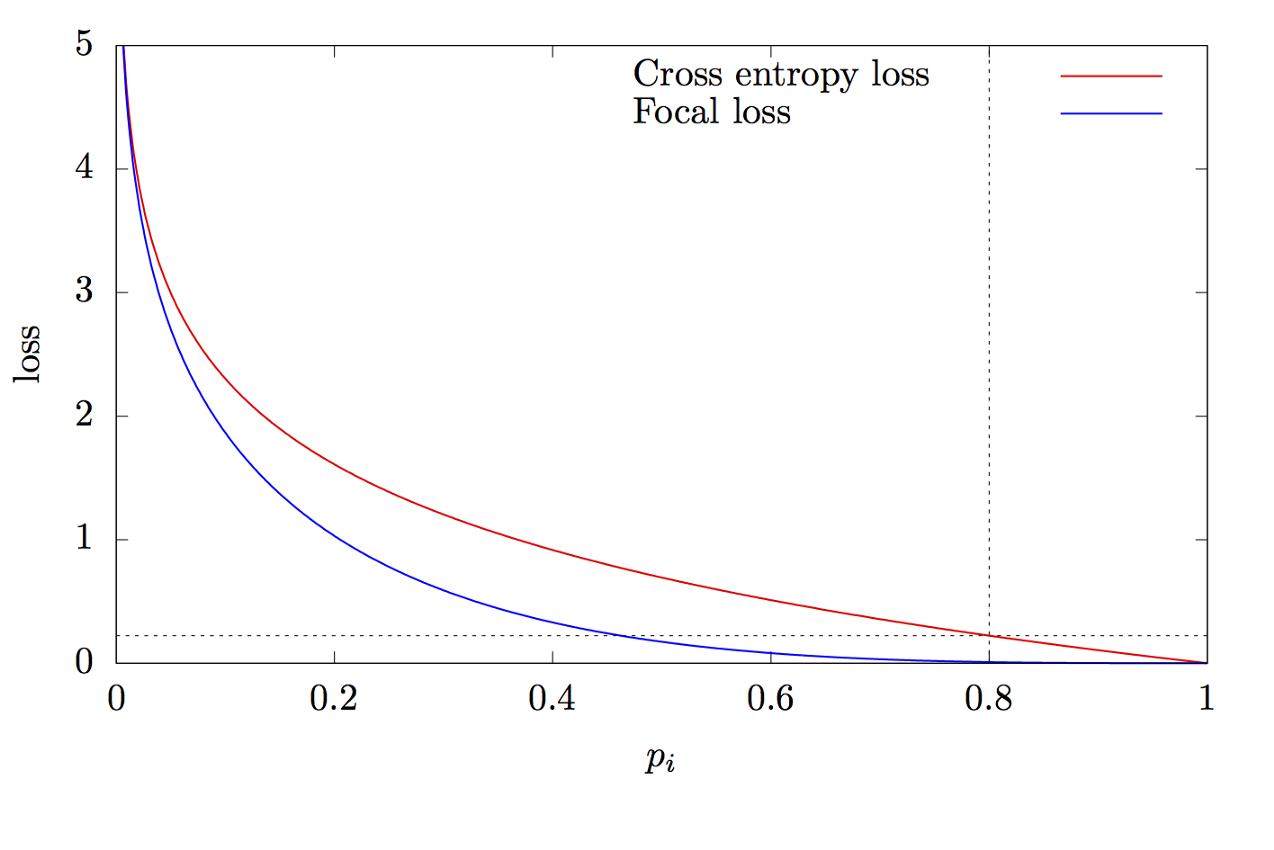
Gambar 8 - Grafik fungsi fokus dan lintas entropi
Terima kasih sudah membaca artikel ini!
Daftar sumber:
- Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. URL: arxiv.org/abs/1905.11946
- Zeng N. RetinaNet Explained and Demystified [ ]. 2018 URL: blog.zenggyu.com/en/post/2018-12-05/retinanet-explained-and-demystified
- Review: RetinaNet — Focal Loss (Object Detection) [ ]. 2019 URL: towardsdatascience.com/review-retinanet-focal-loss-object-detection-38fba6afabe4
- Tsung-Yi Lin Focal Loss for Dense Object Detection. 2017. URL: arxiv.org/abs/1708.02002
- The intuition behind RetinaNet [ ]. 2018 URL: medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d