
Sumber: unsplash.com
Juara Dunia Tiga Kali Formula 1 Jackie Stewart mengatakan bahwa memahami mobil telah membantunya menjadi pengemudi yang lebih baik: "Pembalap tidak harus menjadi seorang insinyur, tetapi minat pada mekanik ."
Martin Thompson (pencipta LMAX Disruptor ) menerapkan konsep ini pada pemrograman. Singkatnya, memahami perangkat keras yang mendasarinya akan meningkatkan keterampilan Anda ketika datang untuk merancang algoritma, struktur data, dan sebagainya.
Tim Mail.ru Cloud Solutions menerjemahkan sebuah artikel yang menggali lebih dalam ke dalam desain prosesor dan melihat bagaimana memahami beberapa konsep CPU dapat membantu Anda membuat keputusan yang lebih baik.
Dasar
Prosesor modern didasarkan pada konsep symmetric multiprocessing (SMP). Sebuah prosesor dirancang sedemikian rupa sehingga dua atau lebih core berbagi memori yang sama (juga disebut memori akses utama atau acak).
Selain itu, untuk mempercepat akses memori, prosesor memiliki beberapa level cache: L1, L2, dan L3. Arsitektur yang tepat tergantung pada pabrikan, model CPU, dan faktor lainnya. Paling sering, bagaimanapun, L1 dan L2 cache beroperasi secara lokal untuk setiap inti, sementara L3 dibagi di semua core.

Arsitektur SMP
Semakin dekat cache dengan inti prosesor, semakin rendah latensi akses dan ukuran cache:
| Cache | Menunda | Siklus CPU | Ukuran |
| L1 | ~ 1,2 ns | ~ 4 | Antara 32 dan 512 KB |
| L2 | ~ 3 ns | ~ 10 | Antara 128 KB dan 24 MB |
| L3 | ~ 12 ns | ~ 40 | Antara 2 dan 32 MB |
Sekali lagi, angka pastinya tergantung pada model prosesor. Untuk perkiraan kasar, jika akses ke memori utama membutuhkan 60 ns, akses ke L1 adalah sekitar 50 kali lebih cepat.
Di dunia prosesor, ada konsep tautan lokal yang penting . Ketika prosesor mengakses lokasi memori tertentu, sangat mungkin bahwa:
- Ini akan merujuk ke lokasi memori yang sama dalam waktu dekat - ini adalah prinsip waktu setempat .
- Dia akan merujuk ke sel memori yang terletak di dekatnya - ini adalah prinsip lokalitas jarak .
Waktu lokalitas adalah salah satu alasan untuk cache CPU. Tetapi bagaimana Anda menggunakan lokalitas jarak? Solusi - alih-alih menyalin satu sel memori ke cache CPU, jalur cache disalin di sana. Garis cache adalah segmen memori yang berdekatan .
Ukuran garis cache tergantung pada level cache (dan sekali lagi pada model prosesor). Misalnya, berikut adalah ukuran garis cache L1 pada mesin saya:
$ sysctl -a | grep cacheline
hw.cachelinesize: 64
Alih-alih menyalin variabel tunggal ke cache L1, prosesor menyalin segmen 64-byte yang berdekatan di sana. Misalnya, alih-alih menyalin elemen int64 tunggal dari slice Go, ia menyalin elemen itu ditambah tujuh elemen int64 lainnya.
Penggunaan Khusus untuk Cache Lines in Go
Mari kita lihat contoh nyata yang menunjukkan manfaat dari cache prosesor. Dalam kode berikut, kami menambahkan dua matriks persegi elemen int64:
func BenchmarkMatrixCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[i][j]
}
}
}
}
Jika
matrixLengthsama dengan 64k, itu menghasilkan hasil sebagai berikut:
BenchmarkMatrixSimpleCombination-64000 8 130724158 ns/op
Sekarang, sebagai gantinya,
matrixB[i][j]kami akan menambahkan matrixB[j][i]:
func BenchmarkMatrixReversedCombination(b *testing.B) {
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i++ {
for j := 0; j < matrixLength; j++ {
matrixA[i][j] = matrixA[i][j] + matrixB[j][i]
}
}
}
}
Apakah ini akan mempengaruhi hasil?
BenchmarkMatrixCombination-64000 8 130724158 ns/op
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
Ya, benar, dan sangat radikal! Bagaimana ini bisa dijelaskan?
Mari kita coba menggambar apa yang terjadi. Lingkaran biru menunjukkan matriks pertama dan lingkaran merah muda menunjukkan yang kedua. Ketika kita atur
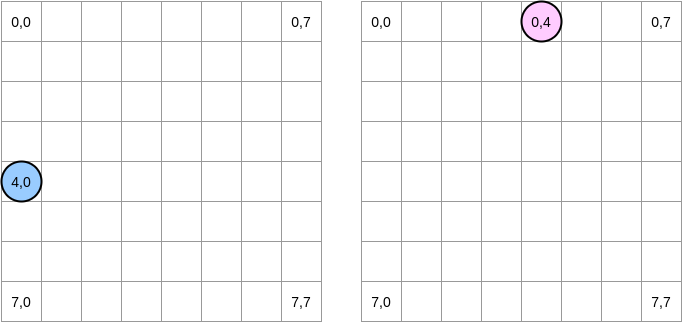
matrixA[i][j] = matrixA[i][j] + matrixB[j][i], pointer biru berada di posisi (4.0) dan yang merah muda ada di posisi (0.4):
Catatan . Dalam diagram ini, matriks disajikan dalam bentuk matematika: dengan absis dan ordinat, dan posisi (0,0) berada di kotak kiri atas. Dalam memori, semua baris matriks disusun berurutan. Namun, demi kejelasan, mari kita lihat representasi matematika. Selain itu, dalam contoh berikut, ukuran matriks adalah kelipatan dari ukuran garis cache. Oleh karena itu, garis cache tidak akan "mengejar" pada baris berikutnya. Kedengarannya rumit, tetapi contohnya akan membuat semuanya jelas.
Bagaimana kita beralih ke matriks? Pointer biru bergerak ke kanan hingga mencapai kolom terakhir dan kemudian pindah ke baris berikutnya di posisi (5,0), dan seterusnya. Sebaliknya, penunjuk merah muda bergerak ke bawah dan kemudian pindah ke kolom berikutnya.
Ketika pointer merah muda mencapai posisi (0,4), prosesor cache seluruh baris (dalam contoh kami, ukuran garis cache adalah empat elemen). Jadi ketika pointer pink mencapai posisi (0,5), kita dapat mengasumsikan bahwa variabel sudah ada di L1, kan?
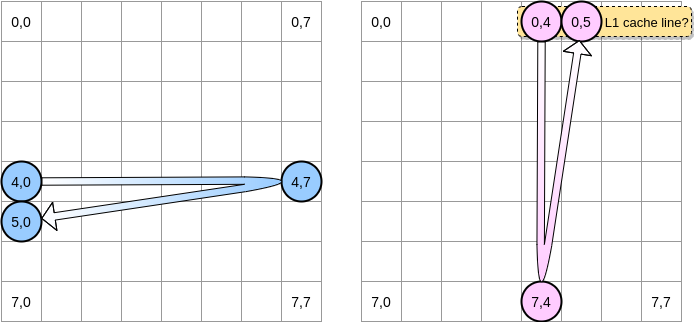
Jawabannya tergantung pada ukuran matriks :
- Jika matriks cukup kecil dibandingkan dengan ukuran L1, maka ya, elemen (0,5) sudah akan di-cache.
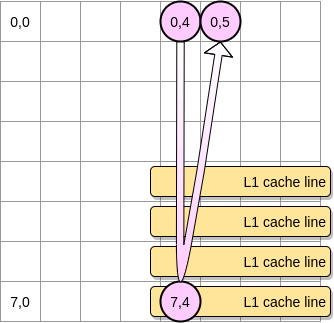
- Jika tidak, baris cache akan dihapus dari L1 sebelum pointer mencapai posisi (0,5). Oleh karena itu, ia akan menghasilkan cache miss dan prosesor harus mengakses variabel dengan cara yang berbeda, misalnya melalui L2. Kami akan berada di negara ini:
Seberapa kecil matriks yang dibutuhkan untuk mendapatkan manfaat dari L1? Mari kita hitung sedikit. Pertama, Anda perlu mengetahui ukuran cache L1:
$ sysctl hw.l1dcachesize
hw.l1icachesize: 32768
Di mesin saya, cache L1 adalah 32.768 byte sementara garis cache L1 adalah 64 byte. Dengan cara ini, saya dapat menyimpan hingga 512 baris cache di L1. Bagaimana jika kita menjalankan benchmark yang sama dengan matriks elemen 512?
BenchmarkMatrixCombination-512 1404 718594 ns/op
BenchmarkMatrixReversedCombination-512 1363 850141 ns/opp
Meskipun kami memperbaiki kesenjangan (pada matriks 64k perbedaannya sekitar 4 kali), kami masih dapat melihat sedikit perbedaan. Apa yang salah? Dalam benchmark, kami bekerja dengan dua matriks. Oleh karena itu, prosesor harus menjaga garis cache keduanya. Dalam dunia ideal (tidak ada aplikasi lain yang berjalan dan sebagainya), cache L1 50% diisi dengan data dari matriks pertama dan 50% dari yang kedua. Bagaimana jika kita mengurangi ukuran matriks hingga setengahnya untuk bekerja dengan 256 elemen:
BenchmarkMatrixCombination-256 5712 176415 ns/op
BenchmarkMatrixReversedCombination-256 6470 164720 ns/op
Akhirnya, kami telah mencapai titik di mana kedua hasil tersebut (hampir) setara.
. ? , Go. - LEA (Load Effective Address). , . LEA .
, int64 , LEA , 8 . , . , . , () .
Sekarang - bagaimana membatasi dampak kesalahan cache dalam kasus matriks yang lebih besar? Ada metode, yang disebut optimasi nested loop (loop nest optimization). Untuk mendapatkan hasil maksimal dari baris cache, kita hanya perlu beralih di dalam blok yang diberikan.
Mari kita mendefinisikan sebuah blok dalam contoh kita sebagai kuadrat dari 4 elemen. Dalam matriks pertama, kita beralih dari (4.0) ke (4.3). Kemudian pindah ke baris berikutnya. Oleh karena itu, kami beralih ke matriks kedua hanya dari (0,4) ke (3,4) sebelum pindah ke kolom berikutnya.
Ketika pointer merah muda melewati kolom pertama, prosesor menyimpan garis cache yang sesuai. Dengan demikian, memeriksa sisa blok berarti mengambil keuntungan dari L1:
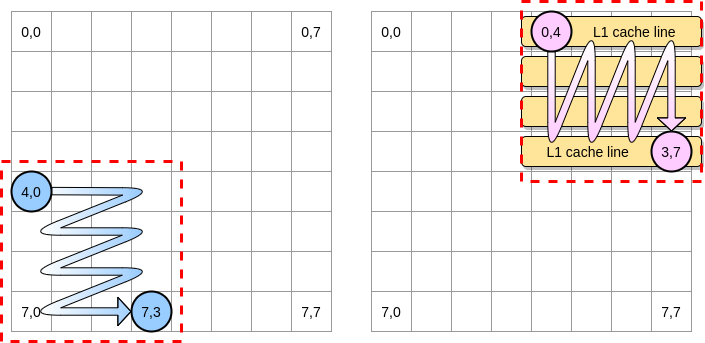
Mari kita menulis implementasi dari algoritma ini di Go, tetapi pertama-tama kita harus hati-hati memilih ukuran blok. Pada contoh sebelumnya, itu sama dengan baris cache. Itu tidak boleh lebih kecil, kalau tidak kita akan menyimpan elemen yang tidak dapat diakses.
Dalam tolok ukur Go kami, kami menyimpan elemen int64 (masing-masing 8 byte). Baris cache adalah 64 byte, sehingga dapat menampung 8 item. Maka nilai ukuran blok harus minimal 8:
func BenchmarkMatrixReversedCombinationPerBlock(b *testing.B){
matrixA := createMatrix(matrixLength)
matrixB := createMatrix(matrixLength)
blockSize := 8
for n := 0; n < b.N; n++ {
for i := 0; i < matrixLength; i += blockSize {
for j := 0; j < matrixLength; j += blockSize {
for ii := i; ii < i+blockSize; ii++ {
for jj := j; jj < j+blockSize; jj++ {
matrixA[ii][jj] = matrixA[ii][jj] + matrixB[jj][ii]
}
}
}
}
}
}
Implementasi kami sekarang lebih dari 67% lebih cepat daripada ketika kami mengulangi seluruh baris / kolom:
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
BenchmarkMatrixReversedCombinationPerBlock-64000 6 185375690 ns/op
Ini adalah contoh pertama yang menunjukkan bahwa memahami operasi cache CPU dapat membantu merancang algoritma yang lebih efisien.
Berbagi salah
Kami sekarang mengerti bagaimana prosesor mengelola cache internal. Sebagai ringkasan cepat:
- Prinsip lokalitas dengan jarak memaksa prosesor untuk mengambil tidak hanya satu alamat memori, tetapi garis cache.
- Cache L1 bersifat lokal untuk satu inti prosesor.
Sekarang mari kita bahas sebuah contoh dengan koherensi cache L1. Memori utama menyimpan dua variabel
var1dan var2. Satu utas pada satu inti mengakses var1, sedangkan utas lainnya pada inti lainnya mengakses var2. Dengan asumsi kedua variabel kontinu (atau hampir kontinu), kita berakhir dalam situasi di mana ia var2hadir di kedua cache
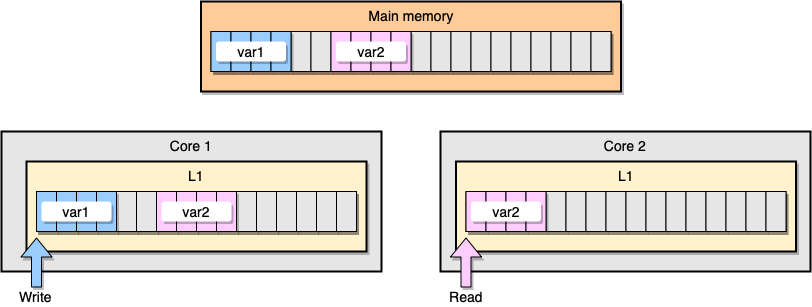
Contoh L1 Cache
Apa yang terjadi jika utas pertama memperbarui garis cache-nya? Ini berpotensi memperbarui lokasi stringnya, termasuk
var2. Kemudian, ketika utas kedua berbunyi var2, nilainya mungkin tidak konsisten.
Bagaimana cara prosesor menjaga cache tetap koheren? Jika dua garis cache memiliki alamat bersama, prosesor akan menandainya sebagai alamat bersama. Jika satu utas memodifikasi baris yang dibagi, itu menandai keduanya sebagai dimodifikasi. Diperlukan koordinasi antar core untuk memastikan koherensi cache, yang secara signifikan dapat menurunkan kinerja aplikasi. Masalah ini disebut berbagi salah .
Mari kita pertimbangkan aplikasi Go tertentu. Dalam contoh ini, kami membuat dua struktur satu demi satu. Oleh karena itu, struktur ini harus berurutan dalam memori. Lalu kita buat dua goroutine, masing-masing mengacu pada strukturnya sendiri (M adalah konstanta sama dengan satu juta):
type SimpleStruct struct {
n int
}
func BenchmarkStructureFalseSharing(b *testing.B) {
structA := SimpleStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
Dalam contoh ini, variabel n dari struktur kedua hanya tersedia untuk goroutine kedua. Namun, karena struktur bersebelahan dalam memori, variabel akan ada pada kedua baris cache (dengan asumsi kedua goroutine dijadwalkan pada utas pada inti yang terpisah, yang tidak harus demikian halnya). Ini adalah hasil benchmark:
BenchmarkStructureFalseSharing 514 2641990 ns/op
Bagaimana mencegah berbagi informasi palsu? Salah satu solusinya adalah memori lengkap (memory padding). Tujuan kami adalah untuk memastikan bahwa ada cukup ruang di antara dua variabel sehingga mereka termasuk dalam baris cache yang berbeda.
Pertama, mari kita buat alternatif untuk struktur sebelumnya dengan mengisi memori setelah mendeklarasikan variabel:
type PaddedStruct struct {
n int
_ CacheLinePad
}
type CacheLinePad struct {
_ [CacheLinePadSize]byte
}
const CacheLinePadSize = 64
Kemudian kita instantiate kedua struktur dan terus mengakses dua variabel dalam goroutine terpisah:
func BenchmarkStructurePadding(b *testing.B) {
structA := PaddedStruct{}
structB := SimpleStruct{}
wg := sync.WaitGroup{}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(2)
go func() {
for j := 0; j < M; j++ {
structA.n += j
}
wg.Done()
}()
go func() {
for j := 0; j < M; j++ {
structB.n += j
}
wg.Done()
}()
wg.Wait()
}
}
Dari perspektif memori, contoh ini akan terlihat seperti dua variabel adalah bagian dari baris cache yang berbeda:
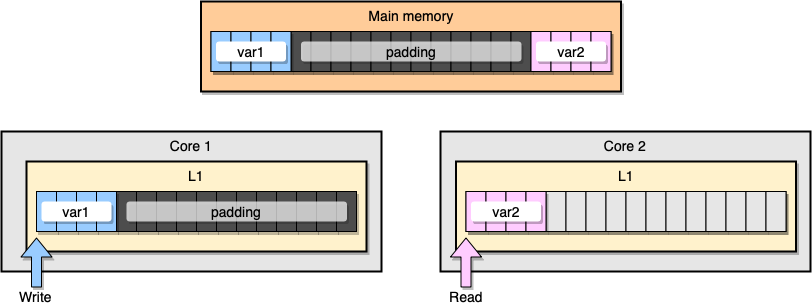
Mengisi memori.
Mari kita lihat hasilnya:
BenchmarkStructureFalseSharing 514 2641990 ns/op
BenchmarkStructurePadding 735 1622886 ns/op
Contoh kedua dengan pengisian memori adalah sekitar 40% lebih cepat dari implementasi asli kami. Namun ada juga sisi negatifnya. Metode ini mempercepat kode, tetapi membutuhkan lebih banyak memori.
Liking mechanics adalah konsep penting dalam hal mengoptimalkan aplikasi. Pada artikel ini, kami telah melihat contoh bagaimana memahami CPU telah membantu kami meningkatkan kecepatan program.
Apa lagi yang harus dibaca: