Prasyarat
Tugas mencari frasa dalam paginasi teks dikurangi untuk menghitung koefisien relevansi untuk setiap halaman dan kemudian mengurutkan daftar dalam urutan koefisien yang menurun.
Dalam proses penghitungan sesuai dengan pendekatan dasar, setiap halaman dikenai analisis simbol-demi-simbol, dan di sinilah letak optimalisasi.

Saat menghitung koefisien, grup karakter pencocokan string pencarian dan data dianalisis, sementara grup hanya dapat dibentuk dalam kata-kata. Di sisi lain, mempertimbangkan masalah melebih-lebihkan pentingnya kata "panjang" (di bagian 2 ), sebagai solusi yang memungkinkan, " menghitung relevansi frasa pencarian sebagai rata-rata relevansi kata-kata yang termasuk di dalamnya, dihitung secara independen " diusulkan . Menggunakan indeks akan menghasilkan hasil yang setara dengan pendekatan khusus ini.
Indeks
Gagasan pengindeksan tidak baru dan adalah sebagai berikut - karena fakta bahwa kata-kata dalam teks diulang, jumlah perhitungan dapat dikurangi. Untuk melakukan ini, teks di mana pencarian akan dilakukan harus terlebih dahulu menghasilkan indeks. Dalam kasus paling sederhana, indeks adalah tabel dari semua kata dalam teks, yang, di samping kata-kata, berisi data tentang halaman di mana mereka muncul. Fragmen tabel indeks berdasarkan teks novel karya L.N. "Perang dan Damai" Tolstoy (totalnya berisi sekitar 50 ribu kata), ditampilkan dalam gambar.

Langsung dalam proses memproses permintaan, string pencarian pertama-tama dipecah menjadi kata-kata. Selanjutnya, untuk setiap kata dari string pencarian, relevansi dihitung dengan masing-masing kata dalam indeks . Hasil perhitungan diakumulasikan dalamtabel hasil pendahuluan yang berisi kolom "Kata string pencarian", "Kata indeks", "Faktor relevansi", "Nomor halaman". Tabel hanya berisi baris-baris indeks, koefisien relevansi yang kata-katanya telah melampaui ambang batas yang ditentukan. Artinya, setiap baris indeks dengan kata yang cocok menghasilkan baris dalam tabel hasil awal yang sama dengan jumlah halaman teks di mana kata ini muncul. Di bawah ini adalah fragmen dari tabel hasil pendahuluan untuk pencarian frasa "Evening at Anna Pavlovna Sherer's".

Kemudian tabel hasil pendahuluan diurutkan berdasarkan kolom nomor halaman , kata string pencarian , faktor(menurun).

Dengan melintasi baris dari tabel yang diurutkan, untuk setiap halaman dan untuk setiap kata dari string pencarian, kata yang paling relevan dari halaman ini diidentifikasi - berkat pengurutan yang dijelaskan di atas, ini adalah kata pertama untuk setiap kombinasi Nomor halaman - Kata string pencarian . Sisa garis dibuang dengan kombinasi.
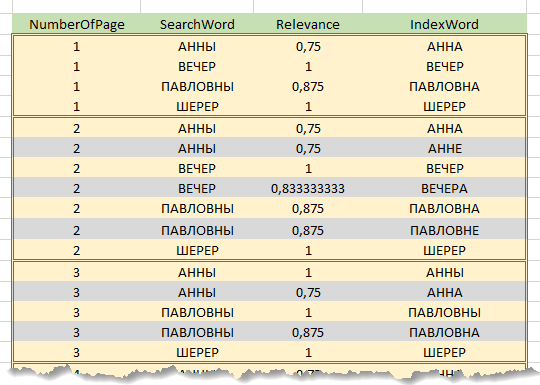
Dengan demikian, untuk setiap halaman teks yang termasuk dalam tabel hasil awal , untuk setiap kata dalam string pencarian, kata-kata yang paling relevan dari halaman ini dengan koefisien yang sesuai akan ditemukan. Jumlah koefisien kata-kata yang ditemukan pada halaman, merujuk pada jumlah kata di bilah pencarian, akan memberikan koefisien relevansi untuk halaman.

Misalnya, pada gambar di atas, pencarian dilakukan oleh baris "Evening at Anna Pavlovna Sherer's" (preposisi "y" tidak diperhitungkan), garis-garis yang disorot dengan warna abu-abu dibuang selama memotong. Koefisien relevansi untuk halaman 1 adalah (0,75 + 1 + 0,875 + 1) / 4 = 0,906, untuk halaman 2 - 0,906, untuk 3 - 0,75.
Manfaat
Jika Anda tidak memperhitungkan waktu akun dihabiskan di pengindeksan, yang hasilnya digunakan kembali dan memperhitungkan bahwa jumlah total perhitungan, penilaian yang direproduksi dalam bagian 1. , A beberapa dari panjang string data yang:
 ;
;
kita dapat mengatakan bahwa keuntungan dari menggunakan indeks akan menjadi kelipatan dari rasio:
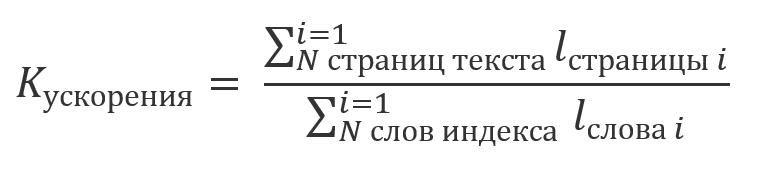
Misalnya, pada demo stand textradar.ru , teks novel "War and Peace" dibagi menjadi 1488 halaman dengan masing-masing 2.000 karakter. Jumlah total simbol dalam kata-kata indeks, yang terdiri dari 52156 elemen, adalah 434060. Artinya, keuntungan dari pengindeksan akan sekitar 7:

Karena kenyataan bahwa hasil yang diperoleh menggunakan pengindeksan setara dengan hasil yang diperoleh dengan menggunakan salah satu pendekatan yang dijelaskan sebelumnya tanpa itu, menjadi mungkin untuk bersama-sama memproses hasil pencarian untuk bagian teks yang diindeks dan tidak diindeks. Karena fakta bahwa pengindeksan adalah operasi yang relatif mahal dan biasanya dilakukan sesuai jadwal, ada kemungkinan bahwa sebagian dari teks diindeks, dan beberapa belum. Dalam hal ini, penghematan dalam jumlah perhitungan akan menjadi kelipatan dari bagian teks yang diindeks dalam ukuran totalnya:
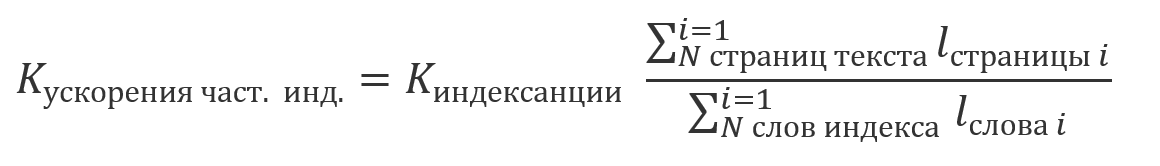
Selain meningkatkan kecepatan pencarian, menggunakan indeks membuka sejumlah kemungkinan lain. Misalnya, dengan menggunakan statistik yang diperoleh dari pengindeksan, Anda dapat meningkatkan pentingnya kata-kata langka, dan juga menyorot halaman-halaman teks tempat kata-kata penting dari frasa pencarian ditemukan lebih sering. Anda juga dapat memperluas tabel indeks dengan sinonim.
Ini menyimpulkan siklus publikasi yang ditujukan untuk deskripsi TextRadar. Terima kasih atas minat dan komentar Anda yang berharga yang memungkinkan kami bergerak lebih jauh dari yang direncanakan.
Hasil penerapan pendekatan yang dijelaskan dapat dilihat pada demo yang digunakan di situs web textradar.ru . Implementasinya (C # ASP.NET MVC) dapat ditemukan di sini .