Ab Initio memiliki banyak transformasi klasik dan tidak biasa yang dapat diperluas dengan PDL sendiri. Untuk bisnis kecil, alat sekuat itu kemungkinan besar akan berlebihan, dan sebagian besar kemampuannya mungkin mahal dan tidak perlu. Tetapi jika skala Anda dekat dengan Sberbank, maka Ab Initio mungkin menarik bagi Anda.
Ini membantu bisnis untuk mengumpulkan pengetahuan secara global dan mengembangkan ekosistem, dan pengembang - untuk memompa keterampilan mereka dalam ETL, untuk menambah pengetahuan di shell, memberikan kesempatan untuk menguasai bahasa PDL, memberikan gambaran visual tentang proses pemuatan, menyederhanakan pengembangan karena banyaknya komponen fungsional.
Dalam posting ini saya akan berbicara tentang kemampuan Ab Initio dan memberikan karakteristik komparatif dari pekerjaannya dengan Hive dan GreenPlum.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
Fungsionalitas produk ini sangat luas dan membutuhkan banyak waktu untuk belajar. Namun, dengan keterampilan kerja yang tepat dan pengaturan kinerja yang tepat, hasil pemrosesan data cukup mengesankan. Menggunakan Ab Initio untuk pengembang dapat memberinya pengalaman yang menarik. Ini adalah pandangan baru tentang pengembangan ETL, gabungan antara lingkungan visual dan pengembangan unduhan dalam bahasa mirip naskah.
Bisnis mengembangkan ekosistemnya dan alat ini berguna lebih dari sebelumnya. Dengan bantuan Ab Initio, Anda dapat mengumpulkan pengetahuan tentang bisnis Anda saat ini dan menggunakan pengetahuan ini untuk mengembangkan bisnis baru yang lama dan terbuka. Alternatif untuk Ab Initio dapat dipanggil dari lingkungan pengembangan visual Informatica BDM dan dari lingkungan non-visual - Apache Spark.
Deskripsi Ab Initio
Ab Initio, seperti alat ETL lainnya, adalah serangkaian produk.

Ab Initio GDE (Lingkungan Pengembangan Grafis) adalah lingkungan untuk pengembang di mana ia membuat transformasi data dan menghubungkannya dengan aliran data dalam bentuk panah. Dalam hal ini, seperangkat transformasi tersebut disebut grafik:

Koneksi input dan output dari komponen fungsional adalah port dan berisi bidang yang dihitung dalam transformasi. Beberapa grafik yang dihubungkan oleh aliran dalam bentuk panah dalam urutan pelaksanaannya disebut rencana.
Ada beberapa ratus komponen fungsional, yang banyak. Banyak dari mereka sangat terspesialisasi. Ab Initio memiliki jangkauan transformasi klasik yang lebih luas daripada alat ETL lainnya. Misalnya, Gabung memiliki banyak keluaran. Selain hasil menghubungkan dataset, Anda bisa mendapatkan catatan output dari dataset input, dengan kunci yang tidak mungkin untuk terhubung. Anda juga bisa mendapatkan penolakan, kesalahan, dan log dari operasi transformasi, yang dapat dibaca dalam kolom yang sama dengan file teks dan diproses oleh transformasi lain:

Atau, misalnya, Anda bisa mematerialisasi penerima data dalam bentuk tabel dan membaca data dari itu di kolom yang sama.
Ada transformasi asli. Misalnya, transformasi Pindai memiliki fungsi yang sama dengan fungsi analitis. Ada transformasi dengan nama yang jelas: Buat Data, Baca Excel, Normalisasi, Sortir dalam Grup, Jalankan Program, Jalankan SQL, Gabung dengan DB, dll. Grafik dapat menggunakan parameter runtime, termasuk mentransfer parameter dari sistem operasi atau ke sistem operasi ... File dengan set parameter siap pakai yang diteruskan ke grafik disebut set parameter (psets).
Seperti yang diharapkan, Ab Initio GDE memiliki repositori sendiri yang disebut EME (Enterprise Meta Environment). Pengembang memiliki kemampuan untuk bekerja dengan versi kode lokal dan memeriksa perkembangannya di repositori pusat.
Dimungkinkan, selama eksekusi atau setelah eksekusi grafik, untuk mengklik aliran apa pun yang menghubungkan transformasi dan melihat data yang melewati antara transformasi ini:

Dimungkinkan juga untuk mengeklik aliran apa pun dan melihat detail pelacakan - dalam berapa banyak persamaan transformasi yang bekerja, berapa banyak baris dan byte di mana dari paralel yang dimuat:

Dimungkinkan untuk membagi eksekusi grafik menjadi fase dan menandai bahwa beberapa transformasi harus dilakukan terlebih dahulu (dalam fase nol), mengikuti fase pertama, mengikuti fase kedua, dll.
Untuk setiap transformasi, Anda dapat memilih apa yang disebut tata letak (di mana ia akan dieksekusi): tanpa paralel atau di utas paralel, jumlah yang dapat diatur. Pada saat yang sama, file sementara yang dibuat oleh Ab Initio selama pekerjaan transformasi dapat ditempatkan baik di sistem file server dan dalam HDFS.
Dalam setiap transformasi, berdasarkan pada templat default, Anda dapat membuat skrip Anda sendiri dalam bahasa PDL, yang sedikit mirip shell.
Dengan bantuan bahasa PDL, Anda dapat memperluas fungsionalitas transformasi dan, khususnya, Anda dapat secara dinamis (saat runtime) menghasilkan fragmen kode arbitrer tergantung pada parameter runtime.
Juga, Ab Initio memiliki integrasi yang dikembangkan dengan OS melalui shell. Secara khusus, Sberbank menggunakan linux ksh. Anda dapat bertukar variabel dengan shell dan menggunakannya sebagai parameter grafik. Anda dapat memanggil eksekusi grafik Ab Initio dari shell dan mengelola Ab Initio.
Selain Ab Initio GDE, pengiriman mencakup banyak produk lainnya. Ada Sistem Operasi Co> dengan klaim disebut sistem operasi. Ada Control> Center di mana Anda dapat menjadwalkan dan memantau aliran unduhan. Ada produk untuk melakukan pengembangan pada tingkat yang lebih primitif daripada yang dimungkinkan oleh Ab Initio GDE.
Deskripsi kerangka kerja MDW dan bekerja pada penyesuaiannya untuk GreenPlum
Bersama dengan produknya, vendor memasok produk MDW (Metadata Driven Warehouse), yang merupakan konfigurator grafik yang dirancang untuk membantu tugas-tugas khas mengisi gudang data atau kubah data.
Berisi parser metadata khusus (khusus proyek) dan generator kode out-of-the-box.
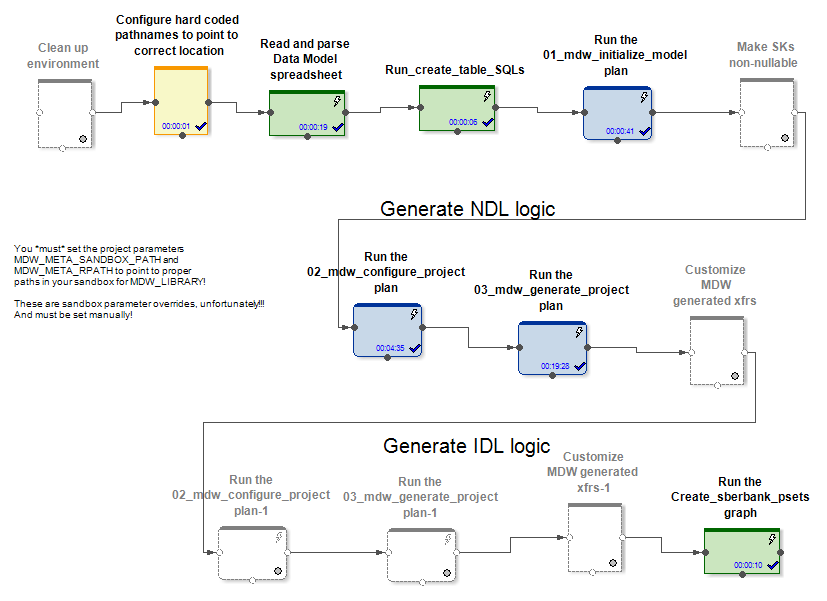
Di pintu masuk, MDW menerima model data, file konfigurasi untuk mengatur koneksi database (Oracle, Teradata, atau Hive) dan beberapa pengaturan lainnya. Bagian spesifik proyek, misalnya, menyebarkan model ke database. Bagian kotak dari produk menghasilkan grafik dan file konfigurasi untuk mereka setelah memuat data ke dalam tabel model. Ini membuat grafik (dan psets) untuk beberapa mode inisialisasi dan pekerjaan tambahan pada pembaruan entitas.
Dalam kasus Hive dan RDBMS, grafik refresh data inisialisasi dan tambahan yang berbeda dihasilkan.
Dalam kasus Hive, data delta yang masuk bergabung dengan Ab Initio. Bergabung dengan data yang ada di tabel sebelum pembaruan. Pemuat data dalam MDW (baik di Hive dan di RDBMS) tidak hanya memasukkan data baru dari delta, tetapi juga menutup periode validitas data untuk kunci utama di mana delta diterima. Selain itu, Anda harus menulis ulang bagian data yang tidak berubah. Tetapi ini harus dilakukan, karena Hive tidak menghapus atau memperbarui operasi.
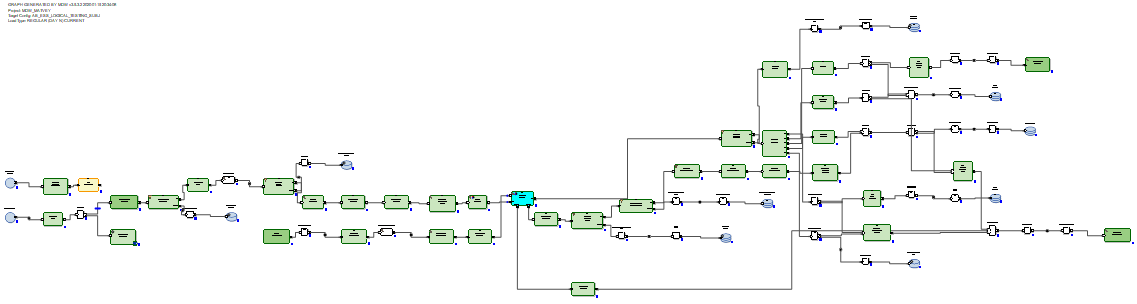
Dalam kasus RDBMS, grafik pembaruan data tambahan terlihat lebih optimal karena RDBMS memiliki kemampuan pembaruan nyata.
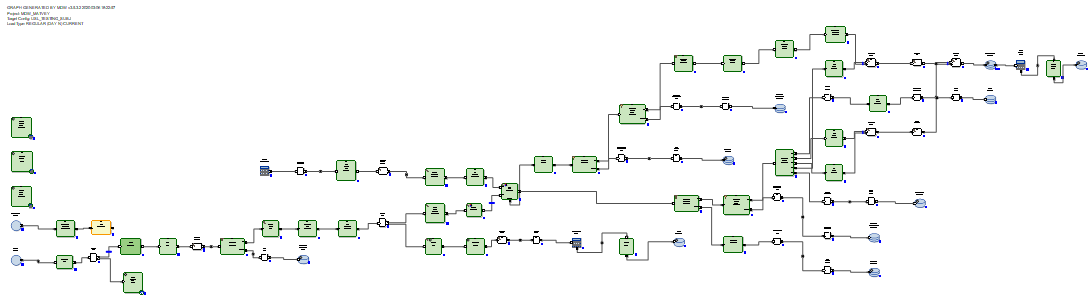
Delta yang diterima dimuat ke dalam tabel pementasan dalam database. Setelah itu, delta terhubung ke data yang ada di tabel sebelum pembaruan. Dan ini dilakukan dengan cara SQL melalui query SQL yang dihasilkan. Kemudian, menggunakan perintah delete + insert SQL, data baru dari delta dimasukkan ke dalam tabel target dan periode relevansi data ditutup, sesuai dengan kunci utama dari mana delta diterima.
Tidak perlu menulis ulang data yang tidak berubah.
Dengan demikian, kami sampai pada kesimpulan bahwa dalam kasus Hive, MDW harus menulis ulang seluruh tabel, karena Hive tidak memiliki fungsi pembaruan. Dan tidak ada yang lebih baik daripada penulisan ulang data yang lengkap saat pembaruan tidak ditemukan. Dalam kasus RDBMS, sebaliknya, pencipta produk menganggap perlu untuk mempercayakan koneksi dan pembaruan tabel menggunakan SQL.
Untuk proyek di Sberbank, kami menciptakan implementasi baru yang bisa digunakan kembali dari pemuat basis data GreenPlum. Ini dilakukan berdasarkan versi yang dihasilkan MDW untuk Teradata. Teradata, bukan Oracle, yang tampil terbaik dan terdekat untuk ini. juga merupakan sistem MPP. Cara kerjanya, serta sintaksis Teradata dan GreenPlum, ternyata serupa.
Contoh perbedaan kritis untuk MDW antara RDBMS yang berbeda adalah sebagai berikut. Di GreenPlum, tidak seperti Teradata, saat membuat tabel, Anda perlu menulis klausa
distributed byTeradata menulis
delete <table> all, dan di GreenePlum mereka menulis
delete from <table>Oracle menulis untuk keperluan optimasi
delete from t where rowid in (< t >), dan Teradata dan GreenPlum menulis
delete from t where exists (select * from delta where delta.pk=t.pk)Kami juga mencatat bahwa agar Ab Initio dapat bekerja dengan GreenPlum, diperlukan untuk menginstal klien GreenPlum di semua node dari cluster Ab Initio. Ini karena kami telah terhubung ke GreenPlum secara bersamaan dari semua node di cluster kami. Dan agar pembacaan dari GreenPlum menjadi paralel dan setiap utas Ab Initio paralel untuk membaca bagian data sendiri dari GreenPlum, perlu untuk menempatkan konstruksi yang dipahami oleh Ab Initio di bagian "di mana" dari query SQL
where ABLOCAL()dan menentukan nilai konstruksi ini dengan menentukan pembacaan parameter dari database transformasi
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»yang mengkompilasi ke sesuatu seperti
mod(sk,10)=3, yaitu Anda harus memberi tahu GreenPlum filter eksplisit untuk setiap partisi. Untuk database lain (Teradata, Oracle) Ab Initio dapat melakukan paralelisasi ini secara otomatis.
Karakteristik kinerja komparatif dari Ab Initio untuk bekerja dengan Hive dan GreenPlum
Sebuah percobaan dilakukan di Sberbank untuk membandingkan kinerja grafik yang dihasilkan oleh MDW dalam kaitannya dengan Hive dan dalam kaitannya dengan GreenPlum. Sebagai bagian dari percobaan, dalam kasus Hive, ada 5 node pada cluster yang sama dengan Ab Initio, dan dalam kasus GreenPlum, ada 4 node pada cluster terpisah. Itu Hive memiliki beberapa keunggulan perangkat keras dibandingkan GreenPlum.
Kami melihat dua pasang grafik yang melakukan tugas yang sama memperbarui data di Hive dan GreenPlum. Grafik yang dihasilkan oleh konfigurator MDW diluncurkan:
- menginisialisasi pemuatan + pemuatan inkremental data yang dihasilkan secara acak ke dalam tabel Hive
- menginisialisasi pemuatan + pemuatan inkremental data yang dihasilkan secara acak ke dalam tabel GreenPlum yang sama
Dalam kedua kasus (Hive dan GreenPlum) meluncurkan unduhan dalam 10 utas paralel pada kluster Ab Initio yang sama. Ab Initio menyimpan data antara untuk perhitungan dalam HDFS (dalam hal Ab Initio, tata letak MFS menggunakan HDFS digunakan). Satu baris data yang dihasilkan secara acak menempati 200 byte dalam kedua kasus.
Hasilnya seperti ini:
Sarang:
| Menginisialisasi pemuatan di Hive | |||
| Baris disisipkan | 6.000.000 | 60.000.000 | 600.000.000 |
| Durasi inisialisasi
beban dalam hitungan detik |
41 | 203 | 1 601 |
| Pemuatan inkremental di Hive | |||
| Jumlah baris dalam
tabel target pada awal percobaan |
6.000.000 | 60.000.000 | 600.000.000 |
| Jumlah baris delta yang diterapkan ke
tabel target selama percobaan |
6.000.000 | 6.000.000 | 6.000.000 |
| Durasi
unduhan tambahan dalam hitungan detik |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
Kita melihat bahwa kecepatan inisialisasi pemuatan di Hive dan GreenPlum secara linear tergantung pada jumlah data dan, untuk alasan perangkat keras yang lebih baik, ini agak lebih cepat untuk Hive daripada untuk GreenPlum.
Pemuatan tambahan di Hive juga secara linear tergantung pada jumlah data yang dimuat sebelumnya di tabel target dan agak lambat karena jumlahnya bertambah. Ini disebabkan oleh kebutuhan untuk sepenuhnya menimpa tabel target. Ini berarti bahwa menerapkan perubahan kecil pada tabel besar bukan kasus penggunaan yang baik untuk Hive.
Pemuatan tambahan dalam GreenPlum sangat tergantung pada jumlah data yang dimuat sebelumnya yang tersedia di tabel target dan cukup cepat. Ini terjadi berkat SQL Joins dan arsitektur GreenPlum, yang memungkinkan operasi penghapusan.
Jadi, GreenPlum menyuntikkan delta menggunakan metode delete + insert, sementara Hive tidak memiliki operasi hapus atau perbarui, sehingga seluruh larik data terpaksa menulis ulang seluruh larik data selama pembaruan inkremental. Yang paling indikatif adalah perbandingan sel yang disorot dalam huruf tebal, karena sesuai dengan varian operasi unduhan intensif sumber daya yang paling sering. Kita melihat bahwa GreenPlum menang 8 kali dari Hive dalam tes ini.
Ab Initio dengan GreenPlum dalam Near Real Time
Dalam percobaan ini, kami akan menguji kemampuan Ab Initio untuk memperbarui tabel GreenPlum dengan potongan data yang dihasilkan secara acak dalam waktu dekat. Pertimbangkan tabel GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, yang dengannya kami akan bekerja.
Kami akan menggunakan tiga grafik Ab Initio untuk bekerja dengannya:
1) Grafik Create_test_data.mp - membuat file dengan data dalam HDFS untuk 6.000.000 baris dalam 10 aliran paralel. Data tersebut acak, strukturnya disusun untuk dimasukkan ke dalam tabel kami

2) Grafik mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - menghasilkan grafik MDW untuk menginisialisasi penyisipan data ke dalam tabel kami dalam 10 utas paralel (digunakan data pengujian oleh grafik (1) digunakan)

3) Grafik mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - menghasilkan grafik MDW untuk pembaruan bertahap tabel kami dalam 10 utas paralel menggunakan sebagian data masuk baru (delta) yang dihasilkan oleh grafik (1)

Jalankan skrip berikut dalam mode NRT:
- menghasilkan 6.000.000 jalur uji
- lakukan inisialisasi pemuatan masukkan 6.000.000 garis uji ke dalam tabel kosong
- ulangi 5 kali unduhan tambahan
- menghasilkan 6.000.000 jalur uji
- buat insert tambahan 6.000.000 baris uji ke dalam tabel (dalam hal ini, data lama dicap dengan waktu kedaluwarsa valid_to_ts dan data yang lebih baru dengan kunci primer yang sama dimasukkan)
Skenario seperti itu mengemulasi mode operasi nyata dari sistem bisnis tertentu - sebagian besar data baru muncul secara real time dan segera dituangkan ke dalam GreenPlum.
Sekarang mari kita lihat log skrip:
Mulai Create_test_data.input.pset di 2020-06-04 11:49:11
Selesai Create_test_data.input.pset di 2020-06-04 11:49:37
Mulai mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset di 2020-06-04 11:49:37
Selesai mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset pada 2020-06-04 11:50:42
Mulai Create_test_data.input.pset di 2020-06-04 11:50:42
Selesai Create_test_data.input.pset pada 2020-06-04 11:51:06
Mulai mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset di 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Mulai Create_test_data.input.pset di 2020-06-04 11:59:55
Selesai Create_test_data.input.pset di 2020-06-04 12:00:23
Mulai mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset di 2020-06-04 00:00:23
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset di 2020/06/04 00:03:23
Mulai Create_test_data.input.pset di 2020/06/04 00:03:23
Finish Create_test_data.input.pset di 2020-06-04 12:03:49
Mulai mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset pada 2020-06-04 12:03:49
Selesai mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset di 2020-06-04:03:49 : 46
Gambarnya terlihat seperti ini:
| Grafik | Waktu mulai | Selesai waktu | Panjangnya |
|---|---|---|---|
| Buat_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Buat_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Buat_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Buat_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Buat_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 PM | 00:03:00 |
| Buat_test_data.input.pset | 06/04/2020 12:03:23 PM | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/04/2020 12:06:46 PM | 00:02:57 |
Kami melihat bahwa 6.000.000 garis kenaikan diproses dalam 3 menit, yang cukup cepat.
Data dalam tabel target ternyata didistribusikan sebagai berikut:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;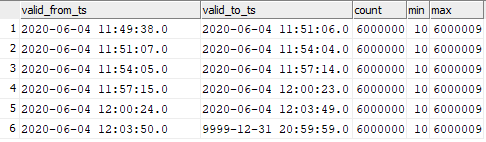
Anda dapat melihat korespondensi data yang dimasukkan dengan momen peluncuran grafik.
Ini berarti Anda dapat mulai memasukkan data tambahan ke dalam GreenPlum di Ab Initio dengan frekuensi yang sangat tinggi dan mengamati kecepatan tinggi memasukkan data ini ke dalam GreenPlum. Tentu saja, tidak akan mungkin untuk memulai sekali dalam satu detik, karena Ab Initio, seperti alat ETL lainnya, membutuhkan waktu untuk "berayun" saat startup.
Kesimpulan
Sekarang Ab Initio digunakan di Sberbank untuk membangun Unified Semantic Data Layer (ESS). Proyek ini melibatkan pembangunan satu versi negara dari berbagai entitas bisnis perbankan. Informasi berasal dari berbagai sumber, replika yang disiapkan di Hadoop. Berdasarkan kebutuhan bisnis, model data disiapkan dan transformasi data dijelaskan. Ab Initio mengunggah informasi ke ECC dan data yang dimuat tidak hanya menarik bagi bisnis itu sendiri, tetapi juga berfungsi sebagai sumber untuk membangun data mart. Pada saat yang sama, fungsionalitas produk memungkinkan Anda untuk menggunakan berbagai sistem (Hive, Greenplum, Teradata, Oracle) sebagai penerima, yang memungkinkan untuk dengan mudah menyiapkan data untuk bisnis dalam berbagai format yang diperlukan.
Kemampuan Ab Initio sangat luas, misalnya, kerangka MDW yang disertakan memungkinkan untuk membuat data historis teknis dan bisnis di luar kotak. Untuk pengembang, Ab Initio memberikan kesempatan untuk "tidak menemukan kembali roda", tetapi untuk menggunakan banyak komponen fungsional yang tersedia, yang, pada kenyataannya, perpustakaan diperlukan ketika bekerja dengan data.
Penulis adalah pakar komunitas profesional Sberbank SberProfi DWH / BigData. Komunitas profesional SberProfi DWH / BigData bertanggung jawab untuk pengembangan kompetensi di berbagai bidang seperti ekosistem Hadoop, Teradata, Oracle DB, GreenPlum, serta alat BI Qlik, SAP BO, Tableau, dll.