bayt.
Kenapa me ini harus khawatir
Data disimpan dalam memori dalam bentuk struktur data, seperti objek, daftar, array, dll. Tetapi jika Anda ingin mengirim data melalui jaringan atau file, Anda harus menyandikannya sebagai urutan baytov. representasi dalam memori dalam urutan byte disebut pengkodean, dan transformasi terbalik - dekodirovaniem. akhirnya diagram data yang diproses oleh aplikasi, atau disimpan dalam memori dapat berkembang, bidang baru dapat ditambahkan ke atau dihapus starye. Digunakan pengkodean Harus harus sebagai terbalik (baru kode harus be dapat dibaca dibaca data tulis kode lama)), jadi dan direksi (lama kode harus be dapat dihapus baca data wrotebaru barukode) kompatibilitas.
Pada
artikel ini, kita akan membahas berbagai format pengkodean, mencari tahu mengapa pengkodean biner lebih baik daripada JSON, XML, dan juga sebagai metode pengkodean biner mendukung perubahan skema
dannyh.
Jenis pemformatan format
Adadua jenis format penyandian:
- Teks format
- Biner format
Format teks
Format teks Contoh format umum adalah JSON, CSV, dan XML. Format teks mudah digunakan dan dimengerti, tetapi mereka memiliki masalah tertentu:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Format teks membutuhkan lebih banyak ruang daripada pengkodean biner. Sebagai contoh, salah satu alasannya adalah bahwa JSON dan XML adalah schemaless dan karenanya harus berisi nama bidang.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Pengkodean JSON dari contoh ini membutuhkan 82 byte setelah semua spasi kosong telah dihapus.
Pengkodean biner
Untuk analisis data yang hanya digunakan secara internal, Anda dapat memilih format yang lebih ramping atau lebih cepat. Meskipun JSON kurang verbose dari XML, keduanya masih memakan banyak ruang jika dibandingkan dengan format biner. Pada artikel ini, kita akan membahas tiga format penyandian biner yang berbeda:
- Penghematan
- Buffer protokol
- Avro
Semuanya menyediakan serialisasi data yang efisien menggunakan skema dan memiliki alat untuk menghasilkan kode, serta dukungan untuk bekerja dengan berbagai bahasa pemrograman. Mereka semua mendukung evolusi skema, menyediakan kompatibilitas mundur dan maju.
Penghemat dan Protokol Buffer
Hemat dikembangkan oleh Facebook dan Protokol Buffer dikembangkan oleh Google. Dalam kedua kasus, skema diperlukan untuk menyandikan data. Thrift mendefinisikan skema menggunakan bahasa definisi antarmuka (IDL) sendiri.
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Skema Setara untuk Protokol Buffer:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Seperti yang Anda lihat, setiap bidang memiliki tipe data dan nomor tag (1, 2, dan 3). Thrift memiliki dua format penyandian biner yang berbeda: BinaryProtocol dan CompactProtocol. Format biner sederhana seperti yang ditunjukkan di bawah ini dan membutuhkan 59 byte untuk menyandikan data di atas.
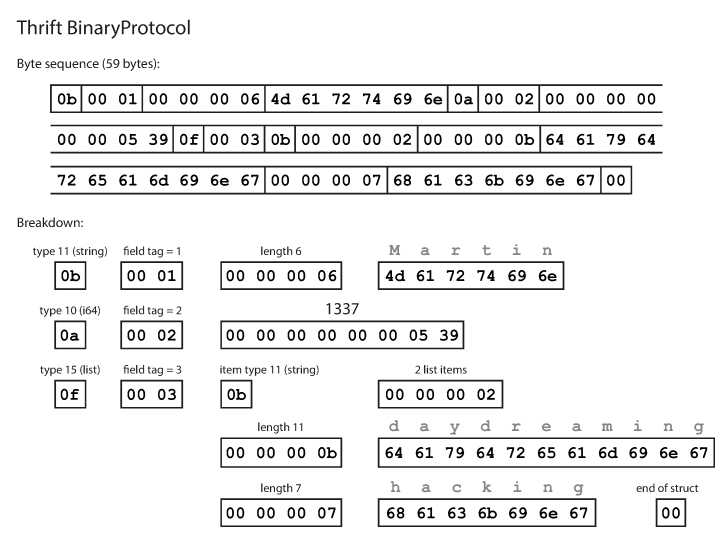
Pengkodean menggunakan protokol biner Thrift Protokol
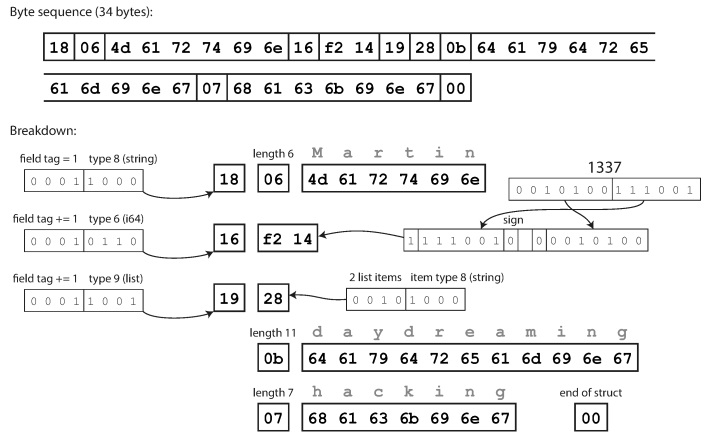
ringkas secara semantik setara dengan biner, tetapi mengemas informasi yang sama menjadi hanya 34 byte. Penghematan dicapai dengan mengemas jenis bidang dan nomor tag menjadi satu byte.
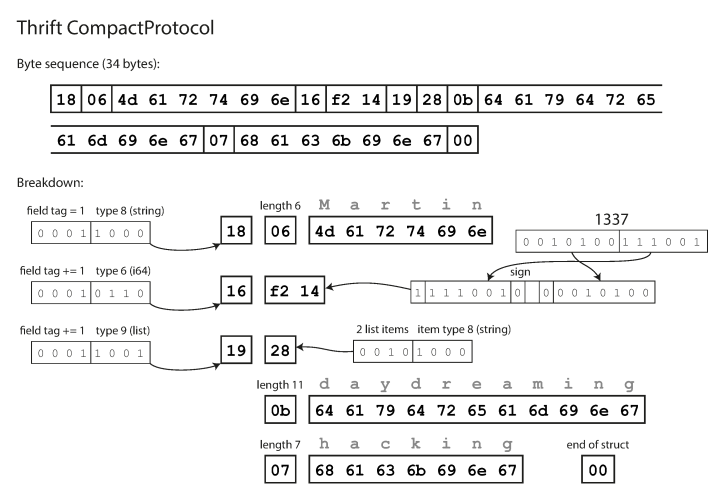
Pengkodean menggunakan Thrift Compact
Protocol Buffer mengkode data dengan cara yang mirip dengan protokol kompak Thrift, dan setelah pengodean, data yang sama adalah 33 byte.
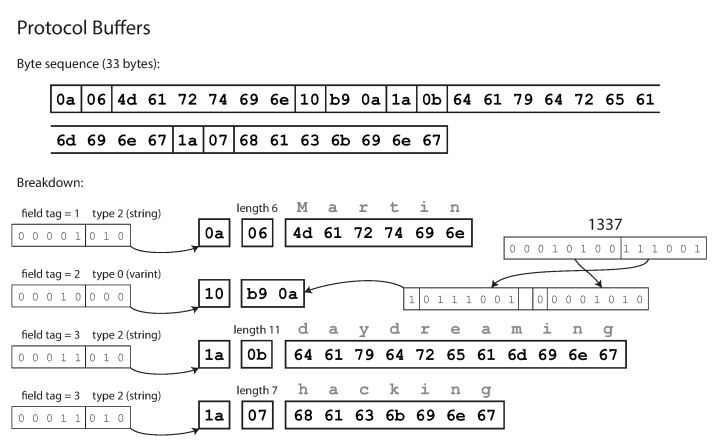
Pengkodean menggunakan Protokol Buffer
Nomor tag mendukung evolusi skema di Hemat dan Protokol Buffer. Jika kode lama mencoba membaca data yang ditulis dengan skema baru, itu hanya akan mengabaikan bidang dengan nomor tag baru. Demikian juga, kode baru dapat membaca data yang ditulis dalam skema lama dengan menandai nilai sebagai nol untuk nomor tag yang hilang.
Avro
Avro berbeda dari Protocol Buffers dan Thrift. Avro juga menggunakan skema untuk mendefinisikan data. Skema dapat didefinisikan menggunakan Avro IDL (format yang dapat dibaca manusia):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Atau JSON (format yang lebih bisa dibaca mesin):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Perhatikan bahwa bidang tidak memiliki nomor label. Data yang sama yang dikodekan dengan Avro hanya membutuhkan 32 byte.
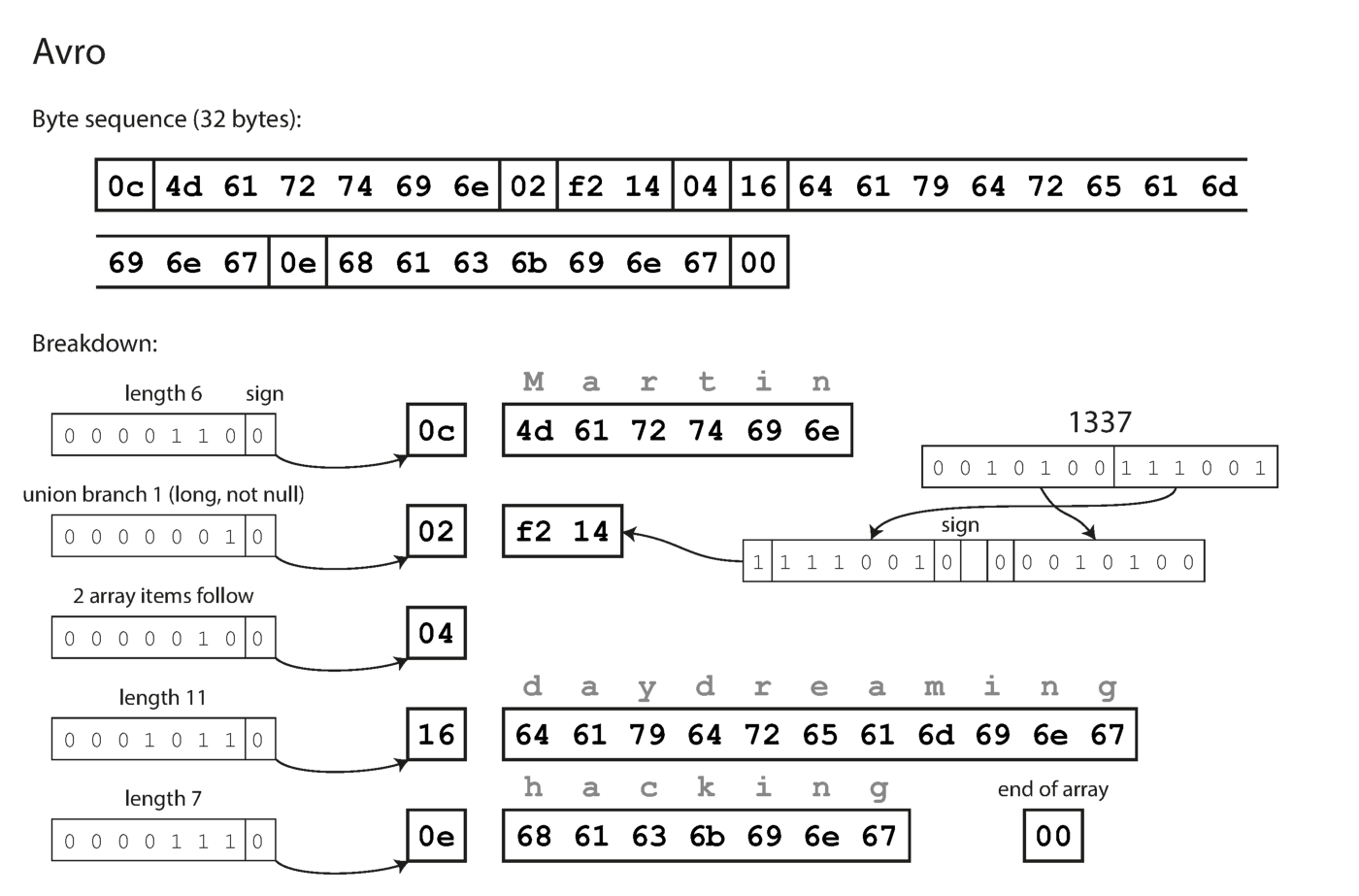
Pengodean dengan Avro.
Seperti yang dapat Anda lihat dari urutan byte di atas, bidang tidak dapat diidentifikasi (dalam label Thrift dan Protokol Buffer dengan angka digunakan untuk ini), juga tidak mungkin untuk menentukan tipe data bidang tersebut. Nilai-nilai disatukan. Apakah ini berarti bahwa setiap perubahan pada rangkaian selama decoding akan menghasilkan data yang salah? Ide utama Avro adalah bahwa skema untuk menulis dan membaca tidak harus sama, tetapi harus kompatibel. Ketika data diterjemahkan, perpustakaan Avro memecahkan masalah ini dengan melihat kedua sirkuit dan menerjemahkan data dari sirkuit perekam ke sirkuit pembaca.
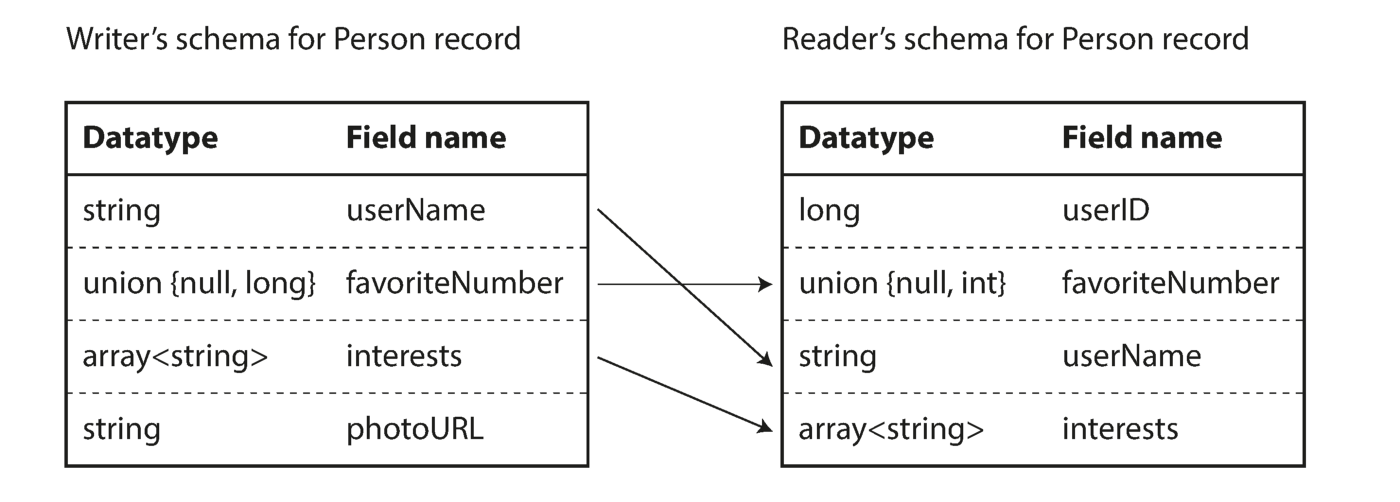
Menghilangkan Perbedaan Antara Pembaca dan Sirkuit Penulis
Anda mungkin berpikir tentang bagaimana pembaca belajar tentang sirkuit penulis. Ini semua tentang skenario penggunaan pengkodean.
- Saat mentransfer file atau data besar, perekam dapat menyertakan sirkuit di awal file satu kali.
- Dalam database dengan catatan individual, setiap baris dapat ditulis dengan skema sendiri. Solusi paling sederhana adalah dengan memasukkan nomor versi di awal setiap entri dan menyimpan daftar skema.
- Untuk mengirim catatan melalui jaringan, pembaca dan penulis dapat menyetujui skema ketika koneksi dibuat.
Salah satu keuntungan utama menggunakan format Avro adalah dukungan untuk skema yang dihasilkan secara dinamis. Karena tidak ada tag bernomor yang dihasilkan, Anda dapat menggunakan sistem kontrol versi untuk menyimpan entri yang berbeda yang dikodekan dengan skema yang berbeda.
Kesimpulan
Pada artikel ini, kami melihat format teks dan penyandian biner, membahas bagaimana data yang sama dapat menempati 82 byte dengan JSON disandikan, 33 byte disandikan dengan Thrift dan Protokol Buffer, dan hanya 32 byte menggunakan encoding Avro. Format biner menawarkan beberapa keuntungan berbeda dari JSON saat mentransfer data melalui jaringan antara layanan back-end.
Sumber daya
Untuk mempelajari lebih lanjut tentang pengodean dan merancang aplikasi intensif data, saya sangat merekomendasikan membaca Merancang Aplikasi Intensif Data oleh Martin Kleppman.

Pelajari detail cara mendapatkan profesi yang dicari dari awal atau Tingkatkan keterampilan dan gaji dengan menyelesaikan kursus online berbayar SkillFactory:
- Kursus Pembelajaran Mesin (12 minggu)
- Belajar Ilmu Data dari awal (12 bulan)
- Profesi analis dengan level awal apa pun (9 bulan)
- Python untuk Kursus Pengembangan Web (9 bulan)