Untuk tinjauan umum, kami mengambil proses CHI: Konferensi tentang Faktor Manusia dalam Sistem Komputasi selama 10 tahun, dan dengan bantuan NLP dan analisis jejaring sosial, kami melihat topik dan area di persimpangan disiplin ilmu.

Di Rusia, fokusnya sangat kuat pada masalah penerapan desain UX. Banyak peristiwa yang membantu pertumbuhan HCI di luar negeri tidak terjadi di negara kami: iSchools tidak muncul , banyak spesialis yang terlibat dalam aspek terkait psikologi teknik meninggalkan ilmu pengetahuan, dll. Akibatnya, profesi muncul kembali, mulai dari masalah terapan dan penelitian. Salah satu hasil dari ini terlihat bahkan sekarang - itu adalah representasi yang sangat rendah dari pekerjaan HCI Rusia di konferensi-konferensi utama.
Tetapi di luar Rusia, HCI telah berkembang dengan cara yang sangat berbeda, dengan fokus pada berbagai topik dan bidang. Pada program master " Sistem informasi dan interaksi manusia-komputer»Di St. Petersburg HSE kami, antara lain, berdiskusi - dengan siswa, kolega, lulusan spesialisasi serupa dari universitas-universitas Eropa, mitra yang membantu mengembangkan program - yang termasuk bidang interaksi manusia-komputer. Dan diskusi ini menunjukkan heterogenitas dari arah di mana masing-masing spesialis memiliki gambar sendiri, tidak lengkap, bidangnya.
Dari waktu ke waktu kami mendengar pertanyaan tentang bagaimana arah ini terkait (dan apakah itu terhubung sama sekali) dengan pembelajaran mesin dan analisis data. Untuk menjawabnya, kami beralih ke penelitian terbaru yang dipresentasikan di konferensi CHI .
Pertama-tama, kami akan memberi tahu Anda apa yang terjadi di berbagai bidang seperti xAI dan iML (eXplainable Artificial Intelligence dan Pembelajaran Mesin yang Dapat Diartikan) dari sisi antarmuka dan pengguna, serta bagaimana dalam HCI mereka mempelajari aspek-aspek kognitif dari pekerjaan para ilmuwan data, dan kami akan memberikan contoh pekerjaan yang menarik dalam beberapa tahun terakhir di setiap bidang.
xAI dan iML
Teknik pembelajaran mesin sedang mengalami pengembangan intensif dan - yang lebih penting dari sudut pandang area yang sedang dibahas - sedang diimplementasikan secara aktif dalam pengambilan keputusan otomatis. Oleh karena itu, para peneliti semakin mendiskusikan pertanyaan-pertanyaan berikut: bagaimana pengguna pembelajaran non-mesin berinteraksi dengan sistem di mana algoritma yang sama digunakan? Salah satu pertanyaan penting dari interaksi ini: bagaimana membuat pengguna mempercayai keputusan yang dibuat oleh model? Oleh karena itu, setiap tahun topik pembelajaran mesin yang ditafsirkan (Interpretable Machine Learning - iML) dan kecerdasan buatan yang dapat dijelaskan (eXplainable Artificial Intelligence - XAI) semakin panas.
Pada saat yang sama, jika pada konferensi seperti NeurIPS, ICML, IJCAI, KDD, algoritma dan sarana iML dan XAI dibahas, CHI berfokus pada beberapa topik yang berkaitan dengan fitur desain dan pengalaman menggunakan sistem ini. Misalnya, pada CHI-2020, beberapa bagian dikhususkan untuk topik ini sekaligus, termasuk "AI / ML & melihat melalui kotak hitam" dan "Mengatasi AI: tidak agAIn!". Tetapi bahkan sebelum munculnya bagian yang terpisah, ada banyak karya seperti itu. Kami telah mengidentifikasi empat area di dalamnya.
Desain sistem interpretif untuk menyelesaikan masalah yang diterapkan
Arah pertama adalah desain sistem yang didasarkan pada algoritma interpretabilitas dalam berbagai masalah yang diterapkan: medis, sosial, dll. Pekerjaan seperti itu muncul di bidang yang sangat berbeda. Misalnya, bekerja di CHI-2020 CheXplain: Memungkinkan Dokter untuk Menjelajahi dan Memahami Data-Didorong, Pencitraan Medis Analisis Pencitraan Medis Diaktifkan menjelaskan suatu sistem yang membantu dokter memeriksa dan menjelaskan hasil rontgen dada. Ia menawarkan penjelasan tekstual dan visual tambahan, serta gambar dengan hasil yang sama dan berlawanan (contoh yang mendukung dan bertentangan). Jika sistem memprediksi bahwa suatu penyakit terlihat pada x-ray, itu akan menunjukkan dua contoh. Contoh pendukung pertama adalah potret paru-paru pasien lain yang telah mengonfirmasi penyakit yang sama. Contoh kedua, yang bertentangan adalah potret di mana tidak ada penyakit, yaitu potret paru-paru orang sehat. Gagasan utamanya adalah untuk mengurangi kesalahan yang jelas dan mengurangi jumlah konsultasi eksternal dalam kasus-kasus sederhana untuk membuat diagnosis lebih cepat.
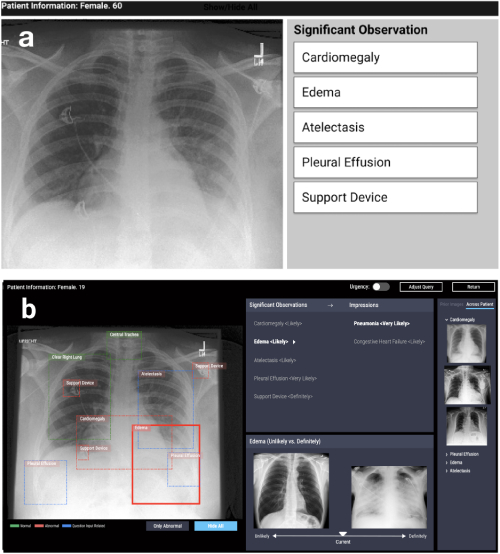
CheXpert: pemilihan wilayah + contoh otomatis (tidak mungkin vs pasti)
Mengembangkan sistem untuk meneliti model pembelajaran mesin
Arah kedua adalah pengembangan sistem yang membantu untuk secara interaktif membandingkan atau menggabungkan beberapa metode dan algoritma. Sebagai contoh, dalam karya Silva: Menilai Secara Interaktif Keadilan Pembelajaran Mesin Menggunakan Kausalitas di CHI-2020, sebuah sistem disajikan yang membangun beberapa model pembelajaran mesin pada data pengguna dan memberikan kemungkinan analisis selanjutnya. Analisis ini mencakup pembuatan grafik kausal antara variabel dan menghitung sejumlah metrik yang mengevaluasi tidak hanya keakuratan, tetapi juga keadilan model (Perbedaan Paritas Statistik, Perbedaan Kesempatan Kesetaraan, Perbedaan Peluang Rata-Rata, Dampak Berbeda, Dampak Berbeda, Indeks Theil), yang membantu untuk menemukan bias dalam prediksi.

Silva : grafik hubungan antara variabel + grafik untuk membandingkan metrik kewajaran + penyorotan warna dari variabel yang berpengaruh di setiap kelompok
Masalah umum interpretabilitas model
Area ketiga adalah pembahasan pendekatan masalah interpretabilitas model secara umum. Paling sering ini adalah ulasan, kritik terhadap pendekatan dan pertanyaan terbuka: misalnya, apa yang dimaksud dengan "interpretabilitas". Di sini saya ingin mencatat ulasan di CHI-2018 Tren dan Lintasan untuk Sistem yang Dapat Dijelaskan, Akuntabel, dan Cerdas: Agenda Penelitian HCI, di mana penulis meninjau 289 makalah utama tentang penjelasan dalam kecerdasan buatan, dan 12.412 publikasi mengutip mereka. Menggunakan analisis jaringan dan pemodelan kasus, mereka mengidentifikasi empat bidang penelitian utama 1) Sistem Cerdas dan Ambient (I&A), 2) AI yang Dapat Dijelaskan: Algoritma yang Adil, Bertanggung Jawab, dan Transparan (FAT) dan Pembelajaran Mesin yang Dapat Diartikan (iML), 3) Teori dari Penjelasan: Kausalitas & Psikologi Kognitif, 4) Interaktivitas dan Pembelajaran. Selain itu, penulis menggambarkan tren penelitian utama: pembelajaran interaktif dan interaksi dengan sistem.
Penelitian pengguna
Akhirnya, area keempat adalah penelitian pengguna pada algoritma dan sistem yang menafsirkan model pembelajaran mesin. Dengan kata lain, ini adalah studi tentang apakah dalam praktiknya sistem baru menjadi lebih jelas dan lebih transparan, kesulitan apa yang dihadapi pengguna ketika bekerja dengan model interpretatif dan bukan asli, bagaimana menentukan apakah sistem sedang digunakan sesuai rencana (atau aplikasi baru telah ditemukan untuk itu) - mungkin salah), apa kebutuhan pengguna dan apakah pengembang menawarkan apa yang sebenarnya mereka butuhkan.
Ada banyak alat interpretasi dan algoritme, sehingga muncul pertanyaan: bagaimana memahami algoritma mana yang harus dipilih? Dalam Mempertanyakan AI: Menginformasikan Praktik Desain untuk Pengalaman Pengguna AI yang Dapat Dijelaskanmasalah motivasi untuk penggunaan algoritma penjelasan dibahas dan masalah diidentifikasi bahwa, dengan semua variasi metode, belum cukup diselesaikan. Para penulis sampai pada kesimpulan yang tidak terduga: sebagian besar metode yang ada dibangun sedemikian rupa sehingga mereka menjawab pertanyaan "mengapa" ("mengapa saya memiliki hasil seperti itu"), sementara pengguna juga membutuhkan jawaban untuk pertanyaan "mengapa tidak" ("mengapa bukan yang lain "), dan terkadang -" apa yang harus dilakukan untuk mengubah hasilnya. "
Makalah ini juga mengatakan bahwa pengguna perlu memahami apa saja batasan penerapan metode, batasan apa yang mereka miliki - dan ini perlu diterapkan secara eksplisit dalam alat yang diusulkan. Masalah ini ditunjukkan lebih jelas di artikelMenafsirkan Interpretabilitas: Memahami Data Penggunaan Alat Interpretabilitas oleh Para Ilmuwan untuk Pembelajaran Mesin . Para penulis melakukan percobaan kecil dengan spesialis di bidang pembelajaran mesin: mereka menunjukkan hasil dari beberapa alat populer untuk menafsirkan model pembelajaran mesin dan meminta mereka untuk menjawab pertanyaan yang terkait dengan pengambilan keputusan berdasarkan hasil ini. Ternyata bahkan para ahli terlalu mempercayai model seperti itu dan tidak mengambil hasilnya secara kritis. Seperti alat apa pun, model penjelas dapat disalahgunakan. Saat mengembangkan toolkit, penting untuk mempertimbangkan hal ini, dengan menggunakan akumulasi pengetahuan (atau spesialis) di bidang interaksi manusia-komputer untuk memperhitungkan karakteristik dan kebutuhan pengguna potensial.
Data Science, Notebooks, Visualization
Bidang lain yang menarik dari HCI adalah dalam analisis aspek kognitif bekerja dengan data. Baru-baru ini, sains telah mengajukan pertanyaan tentang bagaimana "derajat kebebasan" peneliti - fitur pengumpulan data, desain eksperimental, dan pilihan metode analitik - memengaruhi hasil penelitian dan reproduktifitasnya. Sementara sebagian besar diskusi dan kritik terkait dengan psikologi dan ilmu sosial, banyak masalah menyangkut keandalan kesimpulan dalam pekerjaan analis data pada umumnya, serta kesulitan dalam mengkomunikasikan kesimpulan ini kepada konsumen analisis.
Oleh karena itu, subjek dari area HCI ini adalah pengembangan cara-cara baru untuk memvisualisasikan ketidakpastian dalam prediksi model, penciptaan sistem untuk membandingkan analisis yang dilakukan dengan cara yang berbeda, serta analisis kerja analis dengan alat-alat seperti notebook Jupyter.
Memvisualisasikan ketidakpastian
Visualisasi ketidakpastian adalah salah satu fitur yang membedakan grafis ilmiah dari presentasi dan visualisasi bisnis. Untuk waktu yang cukup lama, prinsip minimalis dan fokus pada tren utama dianggap sebagai kunci dalam tren yang terakhir. Namun, ini mengarah pada kepercayaan berlebihan pengguna dalam estimasi titik besarnya atau perkiraan, yang bisa sangat penting, terutama jika kita harus membandingkan perkiraan dengan berbagai tingkat ketidakpastian. Menampilkan Ketidakpastian Pekerjaan Menggunakan Dotplot Kuantil atau CDF Meningkatkan Pengambilan Keputusan Transitmemeriksa bagaimana visualisasi ketidakpastian dalam prediksi plot sebar dan fungsi distribusi kumulatif membantu pengguna membuat keputusan yang lebih rasional menggunakan contoh masalah memperkirakan waktu kedatangan bus dari data aplikasi seluler. Apa yang sangat baik adalah bahwa salah satu penulis mempertahankan paket ggdist untuk R dengan berbagai opsi untuk memvisualisasikan ambiguitas.

Contoh visualisasi ketidakpastian ( https://mjskay.github.io/ggdist/ )
Namun, tugas memvisualisasikan alternatif yang mungkin sering ditemui, misalnya, untuk urutan tindakan pengguna dalam analisis web atau analitik aplikasi. Bekerja Memvisualisasikan Ketidakpastian dan Alternatif dalam Peristiwa Urutan Prediksi menganalisis bagaimana representasi grafis dari alternatif berdasarkan model Time-Aware Recurrent Neural Network (TRNN ) membantu para ahli untuk membuat keputusan dan memercayai mereka.
Perbandingan model
Sama pentingnya dengan memvisualisasikan ketidakpastian, aspek pekerjaan analis membandingkan bagaimana - sering disembunyikan - pilihan peneliti tentang pendekatan yang berbeda untuk pemodelan pada semua tahapannya dapat menghasilkan hasil analitik yang berbeda. Dalam psikologi dan ilmu sosial, pra-registrasi desain penelitian dan pemisahan yang jelas dari studi eksplorasi dan konfirmasi semakin populer. Namun, dalam tugas-tugas di mana penelitian lebih didorong oleh data, sebuah alternatif dapat menjadi alat yang memungkinkan Anda untuk menilai risiko tersembunyi dari analisis dengan membandingkan model. Bekerja Meningkatkan Transparansi Makalah Penelitian dengan Analisis Multiverse yang Dapat Dieksplorasimenyarankan menggunakan visualisasi interaktif dari beberapa pendekatan untuk analisis dalam artikel. Intinya, artikel itu berubah menjadi aplikasi interaktif di mana pembaca dapat mengevaluasi apa yang akan berubah dalam hasil dan kesimpulan jika pendekatan yang berbeda diterapkan. Ini sepertinya ide yang berguna untuk analitik praktis juga.
Bekerja dengan alat untuk mengatur dan menganalisis data
Blok kerja terakhir terkait dengan studi tentang bagaimana analis bekerja dengan sistem seperti Jupyter Notebooks, yang telah menjadi alat yang populer untuk mengatur analisis data. Artikel Eksplorasi dan Penjelasan dalam Notebook Komputasi menganalisis kontradiksi antara penelitian dan menjelaskan tujuan pembelajaran yang ditemukan pada dokumen interaktif Github, dan Mengelola Pesan dalam Notebook Komputasipenulis menganalisis bagaimana catatan, potongan kode, dan visualisasi berevolusi dalam alur kerja analis berulang, dan menyarankan kemungkinan penambahan alat untuk mendukung proses ini. Akhirnya, sudah di CHI 2020, masalah utama analis di semua tahap pekerjaan, dari memuat data hingga mentransfer model ke produksi, serta ide-ide untuk meningkatkan alat, dirangkum dalam artikel What's Wrong with Computational Notebooks? Poin Nyeri, Kebutuhan, dan Peluang Desain .
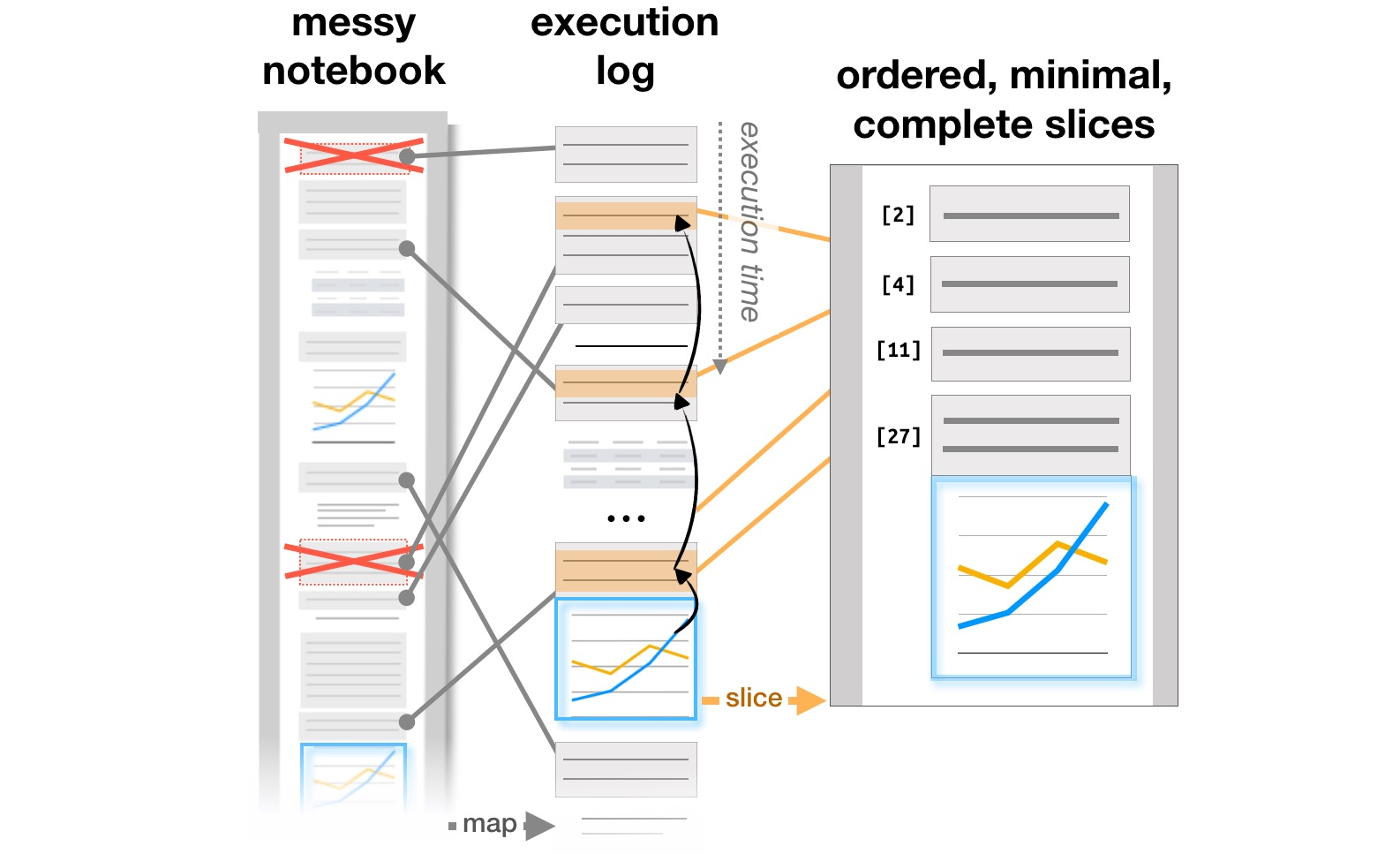
Transformasi struktur laporan berdasarkan log eksekusi ( https://microsoft.github.io/gather/ )
Meringkas
Mengakhiri bagian dari diskusi "apa yang dilakukan HCI" dan "mengapa seorang spesialis HCI mengetahui pembelajaran mesin", saya ingin mengulangi kesimpulan umum dari motivasi dan hasil penelitian ini. Segera setelah seseorang muncul dalam sistem, ini segera mengarah ke sejumlah pertanyaan tambahan: bagaimana menyederhanakan interaksi dengan sistem dan menghindari kesalahan, bagaimana pengguna mengubah sistem, apakah penggunaan aktual berbeda dari yang direncanakan. Sebagai hasilnya, kita membutuhkan mereka yang mengerti bagaimana proses merancang sistem dengan kecerdasan buatan bekerja, dan tahu bagaimana memperhitungkan faktor manusia.
Kami mengajarkan semua ini pada program master " Sistem informasi dan interaksi manusia-komputer". Jika Anda tertarik dalam penelitian HCI, periksa lampu ( kampanye penerimaan baru saja dimulai ). Atau ikuti blog kami: kami akan memberi tahu Anda lebih banyak tentang proyek yang telah dikerjakan siswa tahun ini.