
Bagaimana cara menghemat biaya cloud saat bekerja dengan Kubernetes? Satu-satunya solusi yang tepat tidak ada, tetapi artikel ini menjelaskan beberapa alat yang akan membantu Anda mengelola sumber daya lebih efisien dan mengurangi biaya komputasi awan.
Saya menulis artikel ini dengan mempertimbangkan Kubernet untuk AWS, tetapi akan berlaku (hampir) dengan cara yang sama untuk penyedia cloud lainnya. Saya berasumsi bahwa cluster Anda telah dikonfigurasi penskalaan otomatis ( cluster-autoscaler ). Menghapus sumber daya dan mengurangi skala penyebaran akan menghemat uang hanya jika itu juga mengurangi armada node kerja Anda (instance EC2).
Artikel ini akan mencakup:
- membersihkan sumber daya yang tidak digunakan ( kube-janitor )
- downscaling saat jam off ( kube-downscaler )
- menggunakan horizontal autoscale (HPA),
- mengurangi overbooking sumber daya ( kube-resource-report , VPA)
- Menggunakan Instans Spot
Membersihkan sumber daya yang tidak digunakan
Bekerja di lingkungan yang serba cepat sangat bagus. Kami ingin organisasi teknis untuk mempercepat . Pengiriman perangkat lunak yang lebih cepat juga berarti lebih banyak penggunaan PR, lingkungan pratinjau, prototipe, dan solusi analitik. Semuanya dikerahkan di Kubernetes. Siapa yang punya waktu untuk membersihkan penyebaran pengujian secara manual? Sangat mudah untuk melupakan tentang menghapus percobaan lama selama seminggu. Tagihan cloud akhirnya akan naik karena kami lupa untuk menutup:

(Henning Jacobs:
Zhiza:
(dikutip) Corey Quinn:
Mitos: Akun AWS Anda adalah fungsi dari jumlah pengguna Anda.
Fakta: Akun AWS Anda adalah fungsi dari jumlah insinyur Anda.
Ivan Kurnosov (sebagai tanggapan):
Fakta sebenarnya: Akun AWS Anda adalah fungsi tergantung pada jumlah hal yang Anda lupa nonaktifkan / hapus.)
Kubernetes Janitor (kube- janitor ) membantu membersihkan cluster Anda. Konfigurasi petugas kebersihan fleksibel untuk penggunaan global dan lokal:
- Aturan umum untuk seluruh kluster dapat menentukan waktu-to-live (TTL) maksimum untuk penempatan PR / tes.
- Sumber daya individual dapat dijelaskan dengan petugas kebersihan / ttl, misalnya untuk menghapus spike / prototipe secara otomatis setelah 7 hari.
Aturan umum didefinisikan dalam file YAML. Path-nya dilewatkan melalui parameter
--rules-fileke kube-janitor. Berikut adalah contoh aturan untuk menghapus semua ruang nama dengan -pr-dalam nama setelah dua hari:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dContoh berikut ini mengatur penggunaan label aplikasi pada Deployment dan StatefulSet pods untuk semua Deploymentments / StatefulSet baru pada tahun 2020, tetapi pada saat yang sama memungkinkan pengujian dijalankan tanpa label ini selama seminggu:
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dMenjalankan demo terbatas waktu selama 30 menit di cluster tempat kube-janitor berjalan:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mSumber lain dari kenaikan biaya adalah volume persisten (AWS EBS). Menghapus Kubernetes StatefulSet tidak menghapus volume persistennya (PVC - PersistentVolumeClaim). Volume EBS yang tidak digunakan dapat dengan mudah menyebabkan biaya dalam ratusan dolar per bulan. Kubernetes Janitor memiliki fitur untuk membersihkan PVC yang tidak digunakan. Misalnya, aturan ini akan menghapus semua PVC yang tidak dipasang oleh pod dan tidak direferensikan oleh StatefulSet atau CronJob:
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor dapat membantu Anda menjaga cluster Anda “bersih” dan mencegah biaya komputasi cloud yang menumpuk lambat. Untuk instruksi penggunaan dan konfigurasi, ikuti README kube-janitor .
Mengurangi penskalaan saat jam tidak aktif
Sistem uji dan menengah biasanya diperlukan untuk bekerja hanya selama jam kerja. Beberapa aplikasi produksi, seperti alat back office / admin, juga memerlukan ketersediaan terbatas dan mungkin dinonaktifkan pada malam hari.
Kubernetes Downscaler (kube-downscaler) memungkinkan pengguna dan operator untuk menurunkan skala sistem selama off-hour. Penyebaran dan StatefulSets dapat ditingkatkan ke nol replika. CronJobs dapat ditangguhkan. Kubernetes Downscaler dapat dikonfigurasi untuk seluruh cluster, satu atau lebih ruang nama, atau sumber daya individual. Anda dapat mengatur "waktu idle" atau sebaliknya "run time". Misalnya, untuk mengurangi penskalaan sebanyak mungkin dalam semalam dan akhir pekan:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeBerikut adalah grafik penskalaan node kerja klaster pada akhir pekan:

Menurunkan dari ~ 13 hingga 4 node kerja tentu saja memberikan perbedaan yang nyata dalam akun AWS.
Tetapi bagaimana jika saya perlu bekerja selama cluster "downtime"? Penempatan tertentu dapat secara permanen dikecualikan dari penskalaan dengan menambahkan downscaler / kecualikan: anotasi benar. Penyebaran dapat sementara dikecualikan menggunakan downscaler / kecualikan-sampai anotasi dengan cap waktu absolut dalam format YYYY-MM-DD HH: MM (UTC). Jika perlu, seluruh kluster dapat diskalakan kembali dengan menggunakan pod beranotasi
downscaler/force-uptime, misalnya dengan menjalankan nginx dummy:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueLihat README kube-downscaler jika Anda tertarik pada instruksi penerapan dan opsi tambahan.
Gunakan skala horizontal
Banyak aplikasi / layanan berurusan dengan skema pemuatan dinamis: kadang-kadang modul mereka tidak digunakan, dan kadang-kadang berjalan pada kapasitas penuh. Tidak ekonomis untuk beroperasi dengan armada perapian yang konstan untuk mengatasi beban puncak maksimum. Kubernetes mendukung penskalaan otomatis horisontal melalui sumber daya HorizontalPodAutoscaler (HPA). Penggunaan CPU sering merupakan indikator yang baik untuk penskalaan:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando telah membuat komponen untuk dengan mudah menghubungkan metrik khusus untuk penskalaan: Kube Metrics Adapter (kube-metrics-adapter) adalah adaptor metrik universal untuk Kubernet yang dapat mengumpulkan dan mempertahankan metrik khusus dan eksternal untuk penskalaan perapian horizontal. Ini mendukung penskalaan berdasarkan metrik Prometheus, antrian SQS, dan penyesuaian lainnya. Misalnya, untuk meningkatkan penyebaran Anda untuk metrik khusus yang diwakili oleh aplikasi itu sendiri sebagai JSON dalam / metrik, gunakan:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueMenyiapkan autoscaling horizontal dengan HPA harus menjadi salah satu tindakan default untuk meningkatkan kinerja layanan tanpa negara. Spotify memiliki presentasi dengan pengalaman dan praktik terbaik mereka untuk HPA: Skala penyebaran Anda, bukan dompet Anda .
Pengurangan Reservasi Sumber Daya Redundan
Beban kerja Kubernetes menentukan persyaratan CPU / memori melalui “permintaan sumber daya”. Sumber daya CPU diukur dalam inti virtual atau lebih sering dalam millicores, misalnya, 500m menyiratkan 50% vCPU. Sumber daya memori diukur dalam byte dan sufiks umum dapat digunakan, misalnya 500Mi yang berarti 500 megabita. Sumber daya meminta "mengunci" kapasitas pada node pekerja, yaitu, modul dengan permintaan CPU 1000m pada sebuah simpul dengan 4 vCPU akan menyisakan hanya 3 vCPU yang tersedia untuk modul lain. [1]
Kendur (kelebihan cadangan)Apakah perbedaan antara sumber daya yang diminta dan penggunaan aktual. Misalnya, pod yang meminta 2 GiB memori tetapi hanya menggunakan 200 MiB memiliki ~ 1,8 GiB memori "berlebih". Kelebihan membutuhkan uang. Secara kasar dapat diperkirakan bahwa 1 GiB dari biaya memori berlebih ~ $ 10 per bulan. [2]
Laporan Sumber Daya Kubernetes (kube-resource-report) menampilkan kelebihan cadangan dan dapat membantu Anda menentukan potensi penghematan:

Laporan Sumber Daya Kubernetesmenunjukkan kelebihan yang dikumpulkan oleh aplikasi dan tim. Ini memungkinkan Anda menemukan tempat-tempat di mana permintaan sumber daya dapat dikurangi. Laporan HTML yang dihasilkan hanya memberikan snapshot dari penggunaan sumber daya. Anda harus melihat penggunaan CPU / memori dari waktu ke waktu untuk menentukan permintaan sumber daya yang memadai. Berikut adalah diagram Grafana untuk layanan penggunaan CPU tinggi "khas": semua pod menggunakan kurang dari 3 core CPU yang diminta:
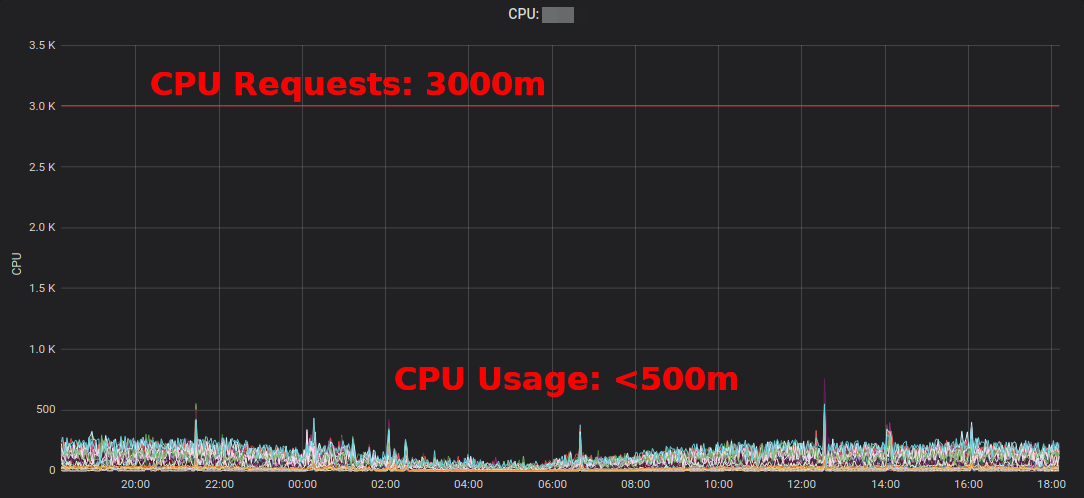
Mengurangi permintaan CPU dari 3000m menjadi ~ 400m membebaskan sumber daya untuk beban kerja lain dan memungkinkan cluster menyusut.
“Rata-rata pemanfaatan CPU dari instance EC2 sering berfluktuasi dalam kisaran persentase satu digit,” tulis Corey Quinn . Sedangkan untuk EC2, memperkirakan ukuran yang benar bisa menjadi keputusan yang burukMengubah beberapa permintaan sumber daya Kubernetes dalam file YAML mudah dan dapat menghemat banyak biaya.
Tetapi apakah kita benar-benar ingin orang mengubah nilai dalam file YAML? Tidak, mesin bisa melakukannya lebih baik! Kubernetes Vertical Pod Autoscaler (VPA) tidak hanya itu: ia menyesuaikan permintaan dan kendala sumber daya agar sesuai dengan beban kerja. Berikut adalah contoh grafik permintaan CPU Prometheus (garis biru tipis) yang diadaptasi oleh VPA dari waktu ke waktu:

Zalando menggunakan VPA di semua clusternya untuk komponen infrastruktur. Aplikasi yang tidak kritis juga dapat menggunakan VPA.
Goldilocksdari Fairwind adalah alat yang membuat VPA untuk setiap penyebaran di ruang nama dan kemudian menampilkan rekomendasi VPA di dasbornya. Ini dapat membantu pengembang membuat permintaan prosesor / memori yang benar untuk aplikasi mereka:

Saya menulis posting blog kecil tentang VPA pada tahun 2019, dan VPA baru - baru ini dibahas di Komunitas Pengguna Akhir CNCF .
Menggunakan Mesin Virtual EC2 Spot
Terakhir namun tidak kalah pentingnya, biaya AWS EC2 dapat dikurangi dengan menggunakan contoh Spot sebagai simpul pekerja Kubernetes [3] . Instance spot tersedia dengan potongan harga hingga 90% sesuai permintaan. Menjalankan Kubernetes di EC2 Spot adalah kombinasi yang baik: Anda perlu menentukan beberapa jenis instance berbeda untuk ketersediaan yang lebih tinggi, yaitu, Anda bisa mendapatkan node yang lebih besar dengan harga yang sama atau lebih rendah, dan peningkatan kapasitas dapat digunakan oleh beban kerja kontainer Kubernetes.
Bagaimana menjalankan Kubernetes di EC2 Spot? Ada beberapa opsi: gunakan layanan pihak ketiga seperti SpotInst (sekarang disebut Spot, jangan tanya kenapa), atau cukup tambahkan Spot AutoScalingGroup (ASG) ke cluster Anda. Misalnya, inilah cuplikan CloudFormation untuk ASG Spot "yang dioptimalkan kapasitas" dengan beberapa jenis instance:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Beberapa catatan tentang penggunaan Spot dengan Kubernetes:
- Anda perlu menangani penyelesaian Spot, misalnya dengan mengeringkan simpul di pemberhentian instance
- Zalando bercabang yang klaster resmi autoscaling dengan prioritas simpul kolam renang
- Node spot dapat dipaksa untuk menerima pendaftaran beban kerja untuk dijalankan di Spot
Ringkasan
Saya harap Anda menemukan beberapa alat yang disajikan di sini bermanfaat dalam mengurangi tagihan cloud computing Anda. Anda juga dapat menemukan sebagian besar konten dalam pembicaraan dan slide YouTube DevOps Gathering 2019 saya .
Apa praktik terbaik Anda untuk menghemat biaya cloud di Kubernetes? Beri tahu kami di Twitter (@try_except_) .
[1] Faktanya, kurang dari 3 vCPU akan tetap dapat digunakan karena bandwidth host dikurangi oleh sumber daya sistem yang dicadangkan. Kubernetes membedakan antara kapasitas simpul fisik dan sumber daya "yang dialokasikan" ( Node Allocatable ).
[2] Contoh perhitungan: satu salinan m5.large dengan memori 8 GiB adalah ~ 84 USD per bulan (eu-central-1, On-Demand), yaitu 1/8 simpul pemblokiran adalah sekitar ~ 10 dolar AS per bulan.
[3] Ada banyak lagi cara untuk mengurangi akun EC2 Anda seperti Mesin Virtual yang Dicadangkan, Paket Tabungan, dll. - Saya tidak akan membahas topik-topik ini di sini, tetapi Anda pasti harus mengetahuinya!
Pelajari lebih lanjut tentang kursus.